

18. Параллельная обработка. Сравнение организации многопроцессорных вс (smp, numa, mpp, кластер).
Мультипроцессоры UMA с многоступенчатыми сетями
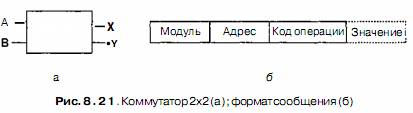
В основе «совсем другого подхода» лежит небольшой коммутатор 2x2. Этот коммутатор содержит два входа и два выхода. Сообщения, приходящие на любую из входных линий, могут переключаться на любую выходную линию. В нашем примере сообщения будут содержать до четырех частей (рис. 8.21, б). Поле Модуль сообщает, какую память использовать. Поле Адрес определяет адрес в этом модуле памяти. В поле Код операции содержится операция, например REA D или WRITE . Наконец, дополнительное поле Значение может содержать операнд, например 32-битное слово, которое нужно записать при выполнении операции WRITE . Комму-
татор исследует поле Модуль и использует его для определения, через какую выходную линию нужно отправить сообщение: через X или через Y.
Наши коммутаторы 2x2 можно компоновать различными способами и получать ногоступенчатые сети [1, 15, 78]. Один из возможных вариантов — сеть omega (рис. 8.22). Здесь мы соединили 8 процессоров с 8 модулями памяти, используя 12 коммутаторов. Для п процессоров и п модулей памяти нам понадобится log2n ступеней, п/2 коммутаторов на каждую ступень, то есть всего (n/2)log2n
Мультипроцессоры NUMA
Размер мультипроцессоров UMA с одной шиной обычно ограничивается до нескольких десятков процессоров, а для координатных мультипроцессоров или мультипроцессоров с коммутаторами требуется дорогое аппаратное обеспечение, и они ненамного больше по размеру. Чтобы получить более 100 процессоров, нужно что-то предпринять. Отметим, что все модули памяти имеют одинаковое время доступа.
Это наблюдение приводит к разработке мультипроцессоров NUMA (NonUniform Memory Access — с неоднородным доступом к памяти). Как и мультипроцессоры UMA, они обеспечивают единое адресное пространство для всех процессоров, но, в отличие от машин UMA, доступ к локальным модулям памяти происходит быстрее, чем к удаленным. Следовательно, все программы UMA будут работать без изменений на машинах NUMA, но производительность будет хуже, чем на машине UMA с той же тактовой частотой. Машины NUMA имеют три ключевые характеристики, которыми все они обладают и которые в совокупности отличают их от других мультипроцессоров:
1. Существует одно адресное пространство, видимое для всех процессоров.
2. Доступ к удаленной памяти производится с использованием команд LOA D и STORE .
3. Доступ к удаленной памяти происходит медленнее, чем доступ к локальной
памяти.
Если время доступа к удаленной памяти не скрыто (поскольку кэш-память отсутствует), то такая система называется NC-NUMA (No Caching NUMA — NUMA без кэширования). Если присутствуют согласованные кэши, то система называется CC-NUMA (Coherent Cache NUMA — NUMA с согласованной кэш-памятью).
МРР — процессоры с массовым параллелизмом
МРР (Massively Parallel Processors — процессоры с массовым параллелизмом) — это огромные суперкомпьютеры стоимостью несколько миллионов долларов. Они используются в различных науках и промышленности для выполнения сложных вычислений, для обработки большого числа транзакций в секунду или для хранения больших баз данных и управления ими.
В большинстве таких машин используются стандартные процессоры. Это могут быть процессоры Intel Pentium, Sun UltraSPARC, IBM RS/6000 и DEC Alpha. Отличает мультикомпьютеры то, что в них используется сеть, по которой можно передавать сообщения, с низким временем ожидания и высокой пропускной способностью. Обе характеристики очень важны, поскольку большинство сообщений малы по размеру (менее 256 байтов), но при этом суммарная нагрузка в большей степени зависит от длинных сообщений (более 8 Кбайт).
Еще одна характеристика МРР — огромная производительность процесса ввода-вывода. Часто приходится обрабатывать огромные массивы данных, иногда терабайты. Эти данные должны быть распределены по дискам, и их нужно перемещать в машине с большой скоростью.
Следующая специфическая черта МРР — отказоустойчивость. При наличии не одной тысячи процессоров несколько неисправностей в неделю неизбежны. Прекращать работу системы из-за неполадок в одном из процессоров было бы неприемлемо, особенно если такая неисправность ожидается каждую неделю. Поэтому большие МРР всегда содержат специальное аппаратное и программное обеспечение для контроля системы, обнаружения неполадок и их исправления.
Было бы неплохо теперь рассмотреть основные принципы разработки МРР, но, по правде говоря, их не так много. МРР представляет собой набор более или менее стандартных узлов, которые связаны друг с другом высокоскоростной сетью. Поэтому ниже мы просто рассмотрим несколько конкретных примеров систем МРР: Cray T3E и Intel/Sandia Option Red.
COW — Clusters of Workstations
(кластеры рабочих станций)
Второй тип мультикомпьютеров — это системы COW (Cluster of Workstations —кластер рабочих станций) или NOW (Network of Workstations — сеть рабочих станций) [8,90]. Обычно он состоит из нескольких сотен персональных компьютеров или рабочих станций, соединенных посредством сетевых плат. Различие между МРР и COW аналогично разнице между большой вычислительной машиной и персональным компьютером. У обоих есть процессор, ОЗУ, диски, операционная система и т. д. Но в большой вычислительной машине все это работает гораздо быстрее (за исключением, может быть, операционной системы). Однако они применяются
и управляются по-разному. Это же различие справедливо для МРР и COW.
Процессоры в МРР — это обычные процессоры, которые любой человек может купить. В системе ТЗЕ используются процессоры Alpha; в системе Option Red — процессоры Pentium Pro. Ничего специфического. Используются обычные динамические ОЗУ и система UNIX.