

2.4.4. Модели бинарного выбора
В теме фиктивные переменные рассматриваются модели, в которых какие-либо независимые переменные принимают дискретные значения. Например, 0 и 1, выражая некоторые качественные признаки относительно зависимой переменной. Явно или неявно предполагалось, что она выражает количественный признак, принимая непрерывное множество значений, но довольно часто интересующая нас величина по своей природе является дискретной.
Рассмотрим несколько типичных ситуаций.
1 блок. Выбор из двух или нескольких
альтернатив (голосование ,например ,
решение работать или не работать,
покупать или не покупать, выбор профессии,
способ попадания из дома на работу).
блок. Выбор из двух или нескольких
альтернатив (голосование ,например ,
решение работать или не работать,
покупать или не покупать, выбор профессии,
способ попадания из дома на работу).
xt= 1
0
Когда есть две возможности, т.е. бинарный выбор и результат наблюдаемый можно описать с помощью 1 и 0, то переменную называют бинарной.
Если есть выбор из k альтернатив (нескольких), то переменную называют номинальной, если альтернативы нельзя естественным образом упорядочить. Последние и предпоследние примеры – номинальные переменные.
2 блок. Ранжированный выбор.
Есть несколько альтернатив, но они некоторым образом упорядочены. Например, доходы семьи (высокие, низкие, средние), уровень образования (высшее, среднее), состояние здоровья (плохое, удовлетворительное, нормальное).
Т акие
переменные называются порядковыми
(ранговыми).
акие
переменные называются порядковыми
(ранговыми).
1
xt= 2
…
k
3 блок. Количественная целочисленная характеристика.
Например, количество прибыльных предприятий, количество зарегистрированных патентов в течение года.
Для моделей с дискретными зависимыми переменными МНК применить достаточно сложно.
Для рассмотрения первого типа ситуаций(для бинарных переменных) можно применить модели бинарного выбора.
Модели с несколькими альтернативами можно свести к моделям бинарного выбора или исследовать аналогичные методы.
Другой класс моделей, рассматриваемый для качественных переменных, связан с цензурированными или урезанными выборками.
Пусть имеется общая модель линейной регрессии:
 yt=x1/β+ε
yt=x1/β+ε
yt=1
0
M(εt)=0
P(yt=1)=xt/β - линейная модель вероятности
Если в качестве уравнения выбрать функцию
P(yt=1)*F(xt/*β), где F – некоторая функция, область значений которой лежит в отрезке от 0 до 1.
Предположим, что существует некая количественная переменная yt*, связанная с независимыми переменными xt в обычном регресионном уравнении. Например, yt*=xt/*β+ε
Решение соответствующих значений yt=1 принимается тогда, когда yt* превосходит некоторые пороговые значения:
yt=1, если yt*=у пороговое;
yt=0, если yt= у пороговое
Если в качестве F используется функцию стандартизированного нормального распределения, то соответствующую модель называют probit-моделью.
Если в качестве F используется функцию логистического распределения, то соответствующую модель называют logit-моделью.
Тема 3. Нелинейная регрессия (группа 3.3а)
3.1.Виды нелинейной зависимости
3.1.1.Основные понятия
Зависимость между теми или иными факторами в эконометрике не всегда можно описать с помощью линейной функции. В этом случае применяют нелинейную регрессию. Общий вид:
yрасч=f(x1) – для однофакторной регрессии
yрасч=f(x1,x2,…,xp) – для многофакторной регрессии




a>1
a<1
Для перехода к линейному виду, уравнение логарифмируют по основанию a:
logay=logaabx+ε=bx+ ε
logay=bx+ ε
Заменим зависимую переменную logay на z:
z= bx+ ε
Частный случай экспоненциальной зависимости – логистическая кривая:
![]()
Д
анная
кривая имеет 2 горизонтальные асимптоты
y=o, y=1/a
и точку перегиба
![]()
1/a
1/2a
1/(a+b)





Логистические кривые используются для описания поведения показателей, имеющих определенные уровни насыщения (например, для описания зависимости спроса на товар от дохода).
Линеаризация этой зависимости проводится с помощью перехода к переменным
ex=t;
![]() .
Получаем: z=a+bt+ε
.
Получаем: z=a+bt+ε
З
 ависимости
логарифмического типа имеют вид
ависимости
логарифмического типа имеют вид
![]()
a>1
a<1

Обозначим logax=z. Получим линейную модель:
![]()
Зависимости полиномиального вида:
y=a+b1x+b2x2+…+bpxp+ε
Обозначим x=z1, x2=z2,…, xp=zp
y=a+b1z1+b2z2+…+bpzp+ ε
Зависимости степенного вида
y=axb
Прологарифмируем по основанию e:
ln(y)=ln(a)+b*ln(x)
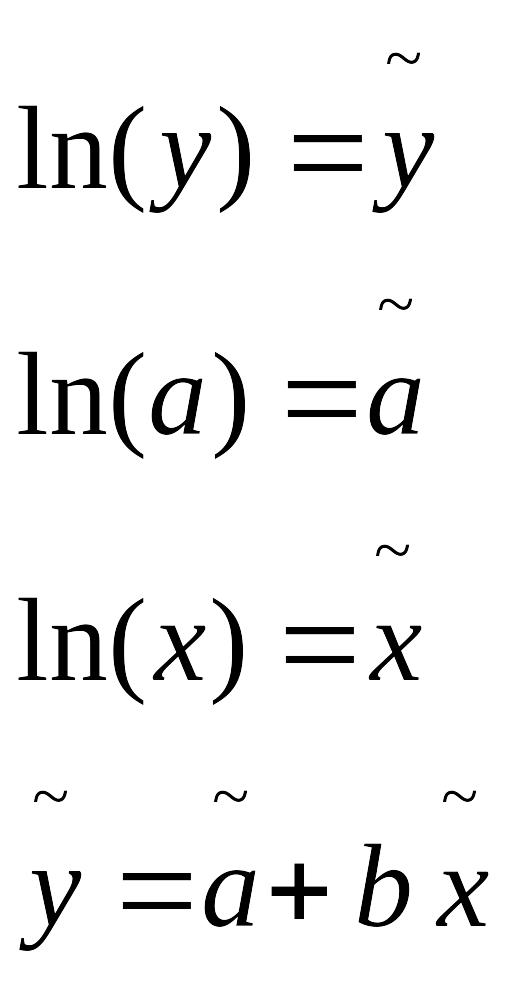
Если модель по независимым факторам является мультипликативной, то переход к аддитивной модели и как следствие к линейной осуществляется с помощью логарифмирования всей зависимости