

Так, якщо порівнювати безпосередньо координати (ознаки), то
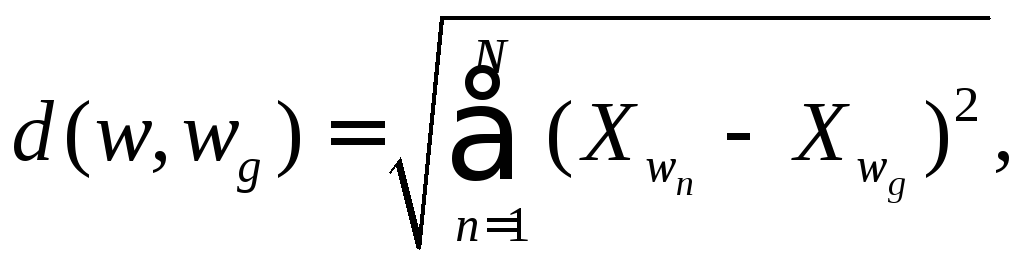
де N - розмірність признакового простору.
Якщо порівнювати кутові відхилення, те розглядаючи вектори, складовими якх є ознаки об'єкта розпізнавання wі класу wg, будемо мати:
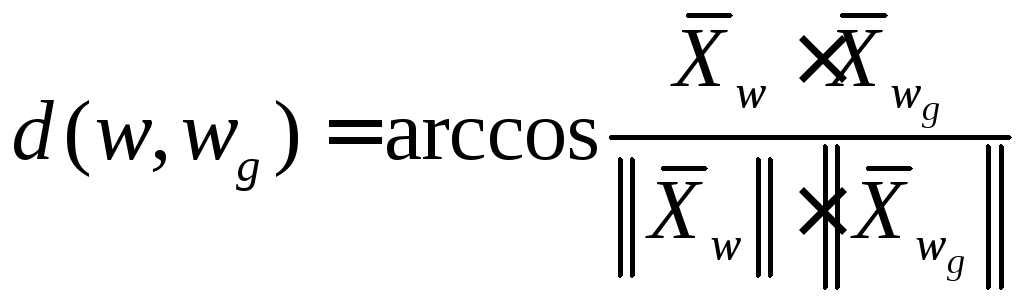 ,
,
де ||Хw|| і 1 ||Хwg|| - норми відповідних векторів.
У алгоритмі розпізнавання, що використовує детерміновані ознаки можна враховувати і їх ваги Vj (встановлювати ступінь довіри або важливості). Тоді розглянута середньоквадратична відстань приймає такий вигляд:

У алгоритмах розпізнавання, що використовують ймовірнісні ознаки, у якості міри близькості використовується ризик, пов'язаний із рішенням про належність об'єкта до класу Wі, де і - номер класу. [і = 1, 2, ..., m).
Описи класів, як ми нещодавно розглянули
![]() .
.
У випадку, що розгрядаєгься до вихідних даних для розрахунку міри близькості відноситься платіжна матриця виду:
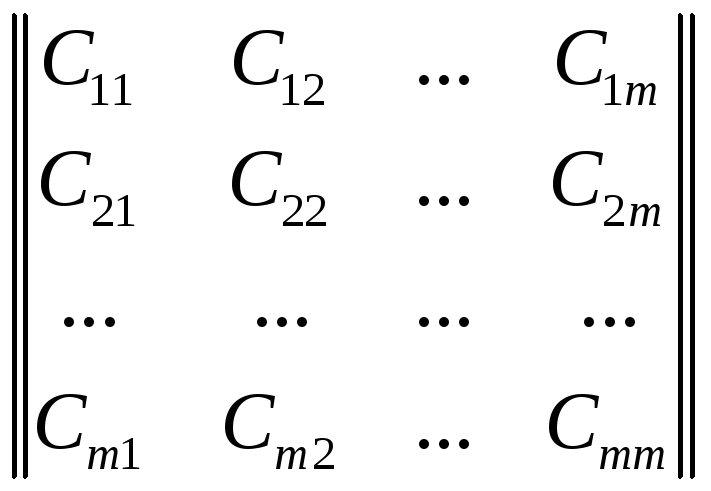 .
.
Тут на головній діагоналі - втрати при правильних рішеннях. Звичайно приймають Сіj = 0 або Сіj < 0.
По обидва боки від головної діагоналі - втрати при помилкових рішеннях. У кожній системі ці втрати свої, властиві тільки їй. Проте призначення їх - творчість розробника системи розпізнавання.
Якщо
вектор ознак об'єкта розпізнавання w
–![]() ,
то ризик, пов'язаний з ухваленням рішеная
про належність цього об'єкта до класу
Wg,
коли насправді він може належати класам
W1, W2, …, Wm
найбільш доцільно визначати як середнє
значення втрат
,
то ризик, пов'язаний з ухваленням рішеная
про належність цього об'єкта до класу
Wg,
коли насправді він може належати класам
W1, W2, …, Wm
найбільш доцільно визначати як середнє
значення втрат
С1g, С2g, ..., Сmg, тобто, втрат, що знаходяться у g-му стовпчику платіжної матриці.
Тоді цей середній ризик можна записати як визначення
![]()
Тут Р(Wi/Хw) - апостеріорна ймовірність того, що wWi
Для вихідних даних, а саме описів класів, ця ймовірність легко може бути визначена у відповідності до теореми гіпотез або по формулі Байеса
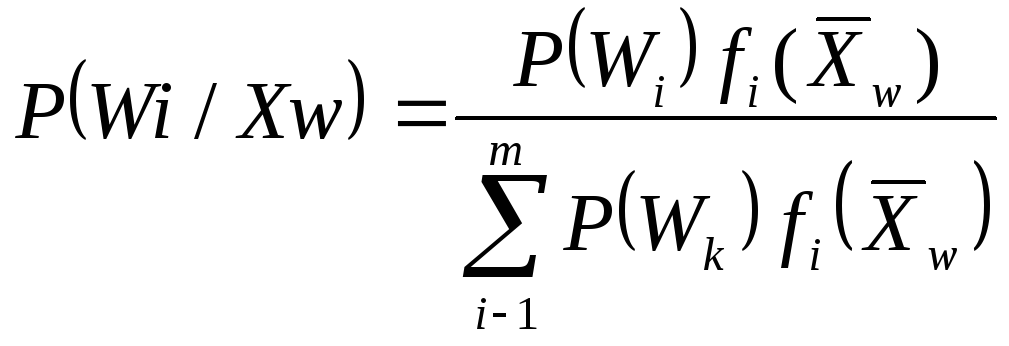
Ймовірності і щільності, що входять у формулу - ні що інше як характеристики опису класів у ймовірносній системі.
Для алгоритмів, заснованих на логічних ознаках, поняття "міра близькості" не має змісту. Пригадаємо спрощений приклад, розглянутий нами для логічних ознак захворювань (простої застуди й ангіни).
Маючи значення ознак А, В, С, достатньо підставити їх у булеві співвідношення між класами й ознаками, щоб відразу одержати результат як істинність або хибність булевої функції опису того або іншого класу.
Дійсно, нехай ознаки прийняли такі значення:
– Підвищена температура: А = 1;
– Нежить: В = 0;
– Нариви в горлі: С = 1;
Тоді підстановка їх у булеві співвідношення дасть такий результат:
W1= 0; W2 = 1.
Тобто, істиною є друге співвідношення, що відповідає розпізнаванню ангіни як класу, що діагаосгується, з двох захворювань.
Для алгоритмів, заснованих на структурних (лінгвістичних) ознаках, поняття «міри близькості» більш специфічно.
З урахуванням того, що кожен клас описується сукупністю пропозицій, що характеризують структурні особливості об'єктів відповідних класів, розпізнавання невідомого об'єкта здійснюється ідентифікацією пропозиції, що описує цей об'єкт, з одним із пропозицій у складі опису якогось класу.
При цьому ідентифікація може розуміти найбільшу подібність пропозиції, що описує об'єкт розпізнаваня із пропозиціями з наборів опису кожного класу.
Визначення робочого алфавіту класів і робочого словника ознак системи розпізнавання.
Дана задача на рівні розробки, що пройшла етапи рішення задач 1-5, принаймні вже можливо поставлена, тому що в результаті виконання попередніх задач створено систему розпізнавання першого наближення (апріорний алфавіт класів і апріорний словник ознак, обраний алгоритм розпізнавання).
Суть поставленої задачі - розробка такого (робочого) алфавіту класів і такого (робочого) словника ознак, що забезпечили б максимальне значення показника ефективності розпізнавання. Тобто, з апріорного словника ми повинні вибрати ознаки, що дозволяють при всіх існуючих обмеженнях на їх одержання (вимірювання) доставити максимум ймовірності правильної класифікації об'єктів (явищ) і (або) мінімальні ймовірності помилкових класифікацій, що утворюється системою. Такий вибір не може не припускати оцінку зазначених показників до того, як створена система.
Зазначена сутність задачі змушує знову звернути увагу на можливість одержання оцінки ефективності системи розпізнавання шляхом її моделювання. Про це ми говорили при створенні апріорного словника ознак. До цього ми повернемося при спеціальному розгляді питань моделювання.