

1.1.4 Визначення мінімальної кількості спостережень
В процесі вивчення статистичного матеріалу постає задача визначення об’єму вибірки. Суть даної задачі полягає у тому, що об’єм вибірки (число спостережень, експериментів) повинен бути достатньо представницьким і характеризувати стан досліджуваного об’єкту. Для великої вибірки мінімальне число спостережень розраховується за формулою
![]() (1.13)
(1.13)
або
![]() (1.14)
(1.14)
де t – квантиль нормального розподілу (додаток Д5) для прийнятого значення довірчої ймовірності Рд (0.95 або 0.90);
– задана абсолютна точність оцінки досліджуваної величини ;
– задана відносна точність оцінки ( = 0.01–0.05).
У випадку малої вибірки задачу розв’язують за допомогою розподілу Стьюдента. Для цього за відомим числом спостережень та довірчою ймовірністю Рд за таблицею розподілу Стьюдента (додаток Д4) визначають величину t.
В дослідницькій практиці для оцінки точності дослідів приймають показник точності дослідів
![]() ,
(1.15)
,
(1.15)
де – коефіцієнт варіації.
Досліди враховують точними, якщо P 2.5%, середньої точності при 2.5% P 5% і малоточними, якщо P>5%.
1.2 Встановлення емпіричного закону розподілу досліджуваних параметрів
Емпіричний закон розподілу – це співвідношення, яке встановлює зв’язок між значеннями випадкової величини і відповідними їм ймовірностями (відносними частотами) подій, які визначаються за формулою
![]() ,
(1.16)
,
(1.16)
де mi – кількість дослідів, в яких випадкова величина X набуває значення xi.
Емпіричний закон розподілу випадкової величини може бути заданий в табличній або графічній формі.
В табличній формі закон розподілу задається статистичним рядом розподілу або функцією F(x) розподілу (інтегральною функцією), яка визначається як сума відносних частот fi або ймовірностей Pi на всіх проміжках:
F(x)= (1.17)
(1.17)
Приклад табличного способу задавання закону розподілу дискретної випадкової величини (кількість автомобілів, які надходять під навантаження на склад протягом години) наведений в таблиці 1.2.
При побудові статистичного ряду неперервної випадкової величини весь діапазон спостережень розбивають на інтервали. Величина інтервалу визначається за формулою
I
=![]() .
(1.18)
.
(1.18)
В кожному розряді підраховують відносні частоти (частості) попадання ознаки в заданий інтервал і будують таблицю емпіричного розподілу. В таблиці 1.3 показаний розподіл неперервної величини часу завантаження автомобіля на складі .
Таблиця 1.2 – Емпіричний закон розподілу дискретної випадкової величини
|
xi |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
mi |
2 |
4 |
10 |
14 |
7 |
5 |
4 |
3 |
1 |
|
Pi |
0.04 |
0.08 |
0.20 |
0.28 |
0.14 |
0.10 |
0.08 |
0.06 |
0.02 |
|
F(x)= Pi |
0.04 |
0.12 |
0.32 |
0.60 |
0.74 |
0.84 |
0.92 |
0.98 |
1.00 |
Таблиця 1.3 – Емпіричний розподіл неперервної випадкової величини
|
№ інтервалу |
Межі інтервалу хі-хі+1, хв |
Частота попадання результатів спостережень в інтервал mі |
Відносна частота (частість)і |
Інтегральна функція F(x) |
|
1 2 3 4 5 |
10-30 30-50 50-70 70-90 90-110 |
15 40 30 10 5 |
0.15 0.40 0.30 0.10 0.05 |
0.15 0.55 0.85 0.95 1.00 |
Графічна інтерпретація емпіричних законів розподілу здійснюється у вигляді полігонів або емпіричних кривих розподілу (для дискретних і неперервних величин), гістограм (для неперервних величин ) і кумулят. Для цього по осі абсцис відкладають всі можливі значення випадкової величини, а по осі ординат – їх відносні частоти fi при побудові гістограм і полігонів, і значення інтегральної функції F(x) при побудові кумуляти. Для дискретної випадкової величини кумулята має східчасту структуру. Графіки емпіричних законів розподілу, побудовані за даними таблиць 1.2-1.3 , показані на рисунку 1.1 і рисунку 1.2.


а) б)
Р

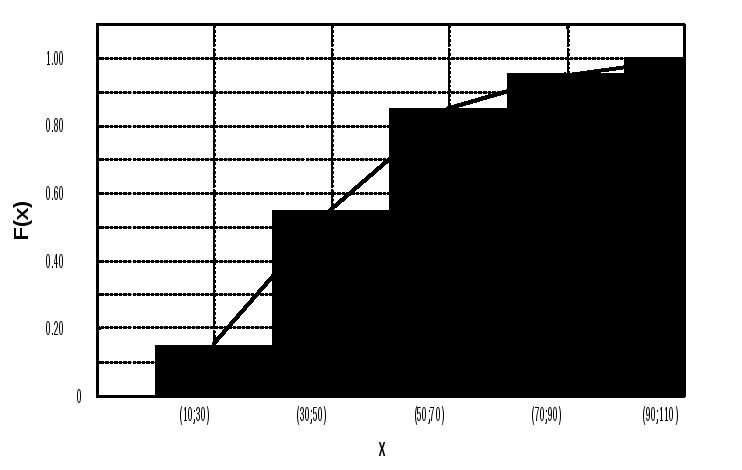
Рисунок 1.2 – Графіки розподілу неперервної величини: а) гістограма (1) і полігон (2) ; б) кумулята..