

ivanter2000_vved_v_kolich_biol
.pdf162
Дисперсионная таблица сразу приобретет строку учета взаимодействия (INTERACTIONS AB). С помощью этой опции можно эффективно регулировать "глубину" учета взаимодействий, когда исследуется несколько факторов.
Результаты дисперсионного анализа полностью идентичны табл. 7.8 и табл. 7.9. Важно отметить, что итог всех вычислений в среде StatGraphics сопровождаются комментариями о методах расчета, а также статистическими выводами. Текст комментариев можно скопировать в буфер обмена из окна StatAdvisor.

163
8
ЗАДАЧА "НАЙТИ ЗАВИСИМОСТЬ МЕЖДУ ДВУМЯ ПРИЗНАКАМИ"
Изложенные выше методы статистического анализа дают возможность изучать изменчивость биологических объектов по отдельным признакам – весу, размерам, плодовитости, физиологическим показателям и др. Однако в ряде случаев важно знать, какова зависимость между вариацией двух или нескольких признаков, изменяются ли две переменные самостоятельно, независимо друг от друга, или изменчивость одного признака в какойто степени связана с изменчивостью другого. В качестве второй переменной часто выступает какой-либо фактор среды.
Эту задачу можно рассматривать как развитие метода дисперсионного анализ, решающего задачу сравнения нескольких выборок (изучения влияния фактора на признак). Техника дисперсионного анализа имеет две особенности. Во-первых, фактор (факториальный признак) задан дискретно, в виде градаций, или "доз". Когда исследуется фактор, заданный качественно, то градации оказываются очень эффективным способом его превращения в подобие количественно заданного фактора. Вместе с тем фактор, выраженный количественной величиной, имеет большее число значений, чем число градаций. Тогда в грубой градуальной схеме дисперсионного анализа утрачивается часть информации, имеющейся в исходных выборках. Кроме этого, дисперсионный анализ явным образом не учитывает тенденции изменения среднего уровня признака при изменении уровня фактора, не содержит показателя динамики зависимости признака от фактора.
Сделать необходимые дополнения позволяет исследование сопряженной (взаимозависимой) изменчивости признаков в рамках регрессионного и корреляционного анализов. Способ представления отдельных наблюдений здесь меняется: каждая варианта рассматривается как носитель двух численных характеристик объекта измерения, двух зависимых значений случайной величины. Если выше мы отождествляли отдельное значение с отдельной вариантой, то теперь мы рассматриваем варианту как некоторое тело, обладающее

164
минимум двумя зарегистрированными качествами, различными у разных вариант:
x |
x |
x |
y |
y |
y |
Например, для любого животного можно определить массу (M) и длину (L) тела; отдельная варианта будет нести два значения (L, M). При этом множество вариант выборки можно отобразить графически как точки на плоскости осей двух признаков M и L.
y (M)
x (L)
Вся выборка предстанет в виде множества точек на плоскости (двумерное рассеяние). Как видно на диаграмме, "облако" вариант вытянуто в направлении диагонали облака точек. Справа вверху находятся варианты с высокими значениями и размеров и массы тела, в левом нижнем углу – с наименьшими значениями. В центре находятся варианты с промежуточными, средними значениями. В первом приближении двумерное распределение – это простая ординация вариант на плоскости осей двух признаков.
Помимо рассеяния на плоскости, в определение двумерного распределения входит и частота встречаемости отдельных вариант. В соответствии с идеологией регрессионного анализа признаки x и y должны подчиняться нормальному закону. Значит, для каждого значения x признак y дает множество нормально распределенных значений; то же и для каждого значения признака y (для случая математической совокупности бесконечного объема) (рис. 8.1). Скопление вариант в трех осях (оси признаков x, y и частоты а) образует весьма странный "бугор", растянутое в пространстве трехмерное нормальное распределение. Однако в реальности такой идеальной картины получить никогда не удается, приходится ориентироваться только на плоскую фигуру рассеяния немногочисленных вариант.

165
Если область, занятую вариантами, очертить по периферии плавной линией, мы получим вытянутую фигуру, эллипс, ограничивающий область рассеяния вариант, эллипс рассеяния. Эллипс рассеяния – это область распространения вариант одной совокупности.
Можно видеть, что в нашем случае признаки связаны друг с другом – есть общая тенденция: чем больше длина тела, тем больше вес, хотя эта зависимость и не очень жесткая, но размыта индивидуальными особенностями.
Рис. 8.1. Двумерное распределение
|
|
Таблица 8.1 |
|
Задача |
Содержание задачи |
Методы |
|
Доказать зависимость |
Признак x служит |
Регрессионный и |
|
дисперсионный и |
|
||
одного признака |
доминирующим |
|
|
корреляционный |
|
||
от другого |
фактором для признака y |
|
|
анализы |
|
||
|
|
|
|
Доказать зависимость |
Переменные x1, x2, … |
Множественная |
|
одной переменной от |
корреляция, |
|
|
влияют на признак y |
|
||
нескольких других |
регрессия |
|
|
|
|
||
Доказать |
Признак x служит |
|
|
доминирующим |
Корреляционный |
|
|
взаимозависимость |
|
||
фактором для признака y, |
анализ |
|
|
двух признаков |
|
||
и наоборот |
|
|
|
|
|
|
|
Доказать связь двух |
Признак z служит |
Метод частной |
|
признаков, исключив |
доминирующим |
корреляции |
|

166
влияние третьего |
фактором для признаков |
|
|
|
x и y |
|
|
Доказать зависимость |
Изменчивость признаков |
Коэффициент |
|
неколичественных |
|||
сопряжена |
Спирмена |
||
признаков |
|||
|
|
Итак, в двумерном распределении проявляются два эффекта: синхронное изменение двух признаков и размывание этой синхронности, т. е. действие факторов доминирующих и случайных: доминирующий фактор (фактор сопряжения признаков) действует вдоль оси эллипса, случайные факторы – поперек оси, размывая взаимозависимость y и x. Проблема изучения зависимости распадается на ряд частных задач (табл. 8.1).
Регрессионный анализ зависимости двух признаков
Регрессионный анализ изучает эффект влияния одного признака на другой, зависимость признака от фактора, зависимость результативного признака от факториального. Его основные результаты таковы:
1.Таблица дисперсионного анализа, в которой показана сила и достоверность влияния на признак изучаемого фактора или другого признака (таблица разложения общего варьирования результативного признака на компоненты и соотнесение их друг с другом).
2.Уравнение регрессии, выражающее пропорциональность сопряженного изменения признаков, тенденции их взаимосвязанной изменчивости или динамики.
3.Оценки значимости параметров регрессионного уравнения.
Логико-теоретические основы
Регрессионный анализ методически односторонне ориентирован на изучение зависимости одного признака от другого (зависимость y от x или, напротив, зависимость x от y), хотя может применяться к случаям, когда фактически имеется взаимозависимость двух переменных. В свою очередь, обобщенная зависимость исследуется "симметричным" методом – корреляционным анализом.
167
Судить о том, как меняется одна величина по мере изменения другой, позволяет коэффициент регрессии (a), показывающий, на какую величину в среднем изменяется один признак (y) при изменении другого (x) на единицу измерения:
y – Y = a∙(x – X).
Простые преобразования: y = a∙x +Y – a∙X,
b = Y – a∙X
приводят к уравнению линейной регрессии: y = ax + b.
Возможность получить уравнение зависимости признаков позволяет важная смена идеологии: регрессионный анализ сравнивает друг с другом не выборки, разнесенные по градациям фактора, но отдельные варианты, т. е. изучает характер рассеяния вариант в осях двух изучаемых признаков, сопряженную изменчивость признаков.
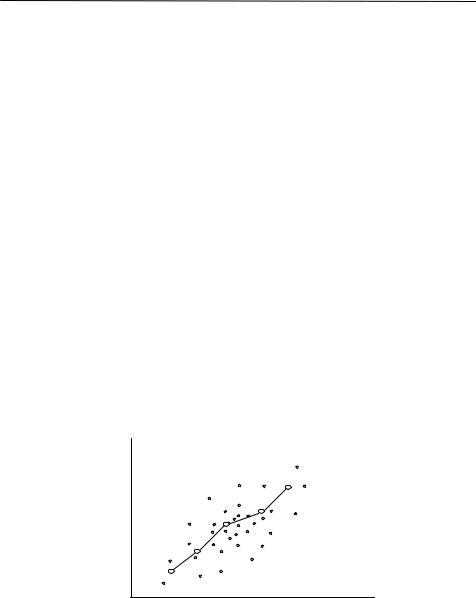
Основную тенденцию взаимосвязанного изменения двух признаков можно отобразить с помощью простого графического приема. Разобьем ось x на несколько интервалов. Найдем для каждого из них среднее (My) значение признака y. Теперь проведем через эти средние точки ломаную линию. Это будет линия регрессии Y по x. Регрессия – изменение среднего уровня одного признака при изменении другого (рис. 8.2).
y
x
Рис. 8.2. Эмпирическая линия регрессии
К сожалению, ход ломаной линии нельзя передать простым уравнением, к тому же на нем сказывается способ интервального

168
разбиения оси абсцисс, а также уровень репрезентативности в разных областях распределения. В этом смысле предпочтительнее была бы единственная прямая линия регрессии, подчеркивающая основные тенденции зависимости признаков и выраженная простым уравнением:
Y = ax + b
(заменив символ для обозначения зависимого признака с y на Y, мы подчеркиваем, что на базе признака x уравнение позволяет рассчитать теоретическое, среднее, значение признака Y, в общем не равное ни одному наблюдаемому значению y).
Грубо регрессионную линию можно построить, взяв всего две точки – средний уровень признаков в верхней и нижней половинках эллипса (рис. 8.3).
Гораздо точнее определить и уравнение регрессии, и ход графика прямой линии можно в том случае, если учесть информацию по всем вариантам изучаемой совокупности. Для этой цели разработан метод наименьших квадратов, основная идея которого состоит в том, чтобы линия регрессии прошла на наименьшем удалении от каждой точки, т. е. чтобы сумма квадратов расстояний от всех точек до прямой линии была наименьшей. В математической статистике показано, что для случая двумерного нормального распределения лучшей (эффективной, несмещенной и пр.) линией, описывающей зависимость одного признака от другого, может быть только линия средних арифметических. Линия регрессии признака y по признаку x – это множество частных средних Yi, соответствующих определенным
значениям xi.
y
x
Рис. 8.3. Примерная прямолинейная регрессия
Используя метод наименьших квадратов, вычислить

169
коэффициенты линейной регрессионной модели можно по следующему алгоритму.
Сначала найдем вспомогательные величины:
Cx = Σx² – (Σx)²/n, Cy = Σy² – (Σy)²/n, Cxy = Σ(x∙y) – (Σx)∙(Σy)/n,
My = Σy/n, Mx = Σx/n.
Затем рассчитаем коэффициенты:
a = Cxy/Cx, b = My – a∙Mx.
Существо коэффициента регрессии a состоит в том, что он призван выражать пропорцию изменения признака y при изменении признака x:
y – Y = a∙(x – X) или a |
y M |
y |
, |
|
|
||
|
|
x M x
но обобщенно для всех вариант выборки:
a |
( y M |
y )( |
x M x ) |
|
Cxy |
. |
|
( x M |
x ) 2 |
Cx |
|||||
|
|
|
|||||
В этой формуле числитель характеризует только сопряженную изменчивость обоих признаков, знаменатель – квадрат общей изменчивости признака x; в итоге имеем показатель пропорции изменения одного признака при изменении другого. Однако это не "чистая" пропорция, но искаженная случайными факторами. Здесь уместно обратиться к истории.
Термин "регрессия" предложил Ф. Гальтон. Анализируя зависимость роста сыновей (y) от роста отцов (x), он обнаружил, что в соответствии с линейным графиком, у низкорослых отцов сыновья должны иметь более высокий рост, чем отцовский. Напротив, у более высоких отцов сыновья должны быть менее высоки, чем они сами (x2 – x1 > y2 – y1). Вместо интуитивно ожидаемой прямой пропорции между ростом отцов и детей (отмечена серым пунктиром, это
y |
Y = a∙x + b |
|
|
|
|
y2 |
|
|
y1 |
|
|
|
|
x |
|
x1 |
x2 |

170
ось эллипса рассеяния) наблюдается определенное возвращение к среднему уровню, "регрессия", как ее назвал исследователь.
Причины такого явления состоят в том, что в случае стохастической зависимости для предсказания значений одного признака по значениям другого требуется показатель, который наиболее обоснован со статистической точки зрения. Таким показателем является средняя арифметическая (точнее, условная средняя, линия регрессии), но ее значения не лягут точно на ось эллипса рассеяния, кроме центральной точки (My, Mx). Однако случайная изменчивость не дает точно охарактеризовать истинную зависимость (пропорцию). Поэтому чем больше величина случайной составляющей общей изменчивости (Cx) по сравнению с сопряженной (Cxy), тем сильнее линия регрессии будет отклоняться от оси эллипса, т. е. чем больше знаменатель, тем ближе к нулю величина коэффициента регрессии.
Построить регрессионное уравнение – это еще даже не пол дела, важнее оценить значимость зависимости признаков, реальность их взаимодействия, т. е. установить, что признак x является существенным, "доминирующим" фактором, сказывается на изменчивости признака y.
Сходную задачу о достоверном влиянии фактора мы решали с помощью критерия исключения выскакивающих вариант. При этом изучаемая выборка состояла из двух частей – некоего "ядра", внутри которого варианты отличаются друг от друга по случайным причинам, и периферических вариант, которые отклонились от "ядра" за счет действия каких-то новых (доминирующих) факторов. Границы области случайного варьирования определялись по "соглашению 95%" и составляли M 2S. Чем больше выборка, тем более точно определяются эти границы.
Перенесем эту логику на случай двумерного нормального распределения. Это значит, что всю область рассеяния вариант можно разбить на две зоны. Во-первых, это "ядро", в котором варианты отличаются друг от друга только по случайным причинам, т. е. факториальный признак x не влияет на результативный признак y. На

171
плоскости двух осей граница области случайного варьирования будет иметь форму окружности, случайный разлет вариант от средней возможен, естественно, во все стороны. Во-вторых, по периферии будут располагаться варианты, отклонившиеся от "ядра" за счет действия доминирующего фактора, т. е. за счет взаимодействия признаков. Такое положительное влияние x на y означает, что чем больше будет значение признака x, тем больше будет и значение признака y, а чем меньше x, тем меньше y. Получается, что варианты, не случайно отклонившиеся от общей средней (от центра), будут накапливаться вверху справа и внизу слева от круглого "ядра". Область рассеяния вариант сформирует эллипс.
y
x
Рис. 8.4. Взаимодействие признаков есть "растягивание" окружности в эллипс
Оценка достоверности взаимодействия признаков есть задача описания пропорций эллипса рассеяния: достаточно ли много вариант выходят за границы случайного рассеяния (за границы круга), чтобы с уверенностью говорить о реальности связи признаков x и y. Для этой цели используется общая идея статистического оценивания – соотнести отклонения под действием доминирующего фактора с отклонениями по случайным причинам.
Лучшим показателем взаимосвязи является линия регрессии (динамика среднего уровня), которая пытается показать только взаимозависимое изменение признаков и вовсе не рассматривает независимое варьирование каждого из них. В свою очередь, характеристикой чисто случайного варьирования выступает