


28
факторов и предпосылок экономического регионального развития для достижения адекватных ей социальных результатов. Основной целью данной методики является определение возможности решения текущих и долгосрочных задач социального и экономического развития регионов.
Порядок расчета комплексной оценки уровня социально-экономического развития субъектов РФ
В предлагаемых ниже формулах верхний индекс j означает номер региона; СР – для среднероссийских показателей, а нижний индекс t – рассматриваемый год.
Для учета территориальной дифференциации уровня цен в данной методике использованы следующие индикаторы, отражающие географические особенности страны:
Коэффициент уровня покупательной способности
ПРMIN tj
КПСtj =
ПРMIN tср
рассчитывается как отношение среднедушевого прожиточного минимума в регионе (ПРMIN tj ) к среднероссийскому показателю (ПРMINtj ).
Районный коэффициент степени удорожания капитальных затрат по регионам России (ККЗ) определен на основе экспертной оценки данных о показателях территориальной дифференциации затрат на создание социальной инфраструктуры.
Перечень базовых индикаторов комплексной оценки уровня социально-экономического развития регионов
1. Валовой региональный продукт (с учетом уровня покупательной способности) на душу населения (тыс.руб.) определяется как отношение валового регионального продукта к численности населения, то есть пока-

29
затель валового регионального продукта на душу населения, деленный на коэффициент уровня покупательной способности:
|
|
ВРПt j |
1 |
|
ВРПtj |
на 1чел. = |
|
∙ |
|
|
|
|||
|
|
Чt j |
КПСt j |
|
2. Объем инвестиций в основной капитал на душу населения в регионе (тыс.руб) определяется как отношение объема инвестиций за счёт всех источников финансирования к численности населения, делённое на коэффициент удорожания капитальных затрат:
|
ИНВt j |
1 |
|
ИНВt j на 1 чел. = |
. |
∙ |
|
|
|||
|
Чt j |
ККЗt j |
|
3. Объем внешнеторгового оборота на душу населения в регионе (долл. США) определяется как отношение суммарного объёма экспорта и импорта к численности населения:
Эt j + Иt j
ВТОt j на 1 чел. =
Чt j
4. Финансовая обеспеченность региона с учетом уровня покупательной способности на душу населения (тыс.руб.) рассчитывается как отношение доходов региона с учетом взаиморасчетов с федеральным бюджетом и государственными внебюджетными фондами региона к численности населения, делённое на коэффициент уровня покупательной способности:
|
Дt j |
1 |
|
ФОРt j на 1 чел. = |
|
∙ |
|
|
|
||
Чt j |
КПСt j |
||
5.Доля занятых на малых предприятиях в общей численности занятых
вэкономике региона (%) определяется как отношение численности заня-
30
тых на малых предприятиях (тыс.чел.) к численности занятых в экономике (тыс.чел.):
|
Чtj |
МП |
|
Дtj МП = |
|
|
∙100 |
|
|
||
Чtj
6. Уровень регистрируемой безработицы (% от экономически активного населения) определяется как отношение численности зарегистрированных безработных (тыс. чел.) к численности занятых в экономике (тыс.чел.):
Чt jбезр
Уt jбезр = |
|
|
∙ 100 |
|
|
||
|
Чt |
j |
|
7. Соотношение среднедушевых доходов и среднедушевого прожиточного минимума в регионе определяется как отношение величины среднедушевых доходов населения к величине среднедушевого прожиточного минимума в регионе.
8.Доля населения с доходами ниже прожиточного минимума (%) в общей численности населения региона.
9. Общий объем розничного товарооборота и платных услуг (с учётом уровня покупательной способности) на душу населения в регионе (тыс.руб.) определяется как отношение суммы розничного товарооборота и объёма платных услуг к численности населения, делённое на коэффициент уровня покупательной способности:
|
VРТО t j + VПУ t j |
1 |
|
j |
|
|
|
V РТО t на 1 чел. = |
|
∙ |
|
|
|
||
|
Ч t j |
КПС t j |
|
31
10. Основные фонды отраслей экономики региона (по полной балансовой стоимости с учетом степени удорожания капитальных затрат) на душу населения (тыс.руб.) определяется как отношение основных фондов отраслей экономики (тыс.руб.) к численности населения (тыс.руб.), делённое на районный коэффициент степени удорожания капитальных затрат:
ОПФt j |
1 |
|||
ОПФt j на1 чел. = |
|
∙ |
|
|
Чt j |
ККЗt j |
|||
|
|
|||
11.Коэффициент плотности автомобильных дорог (коэф. Энгеля) определяется как отношение плотности автодорог к корню квадратному от плотности населения:
-плотность автодорог вычисляется как отношение протяженности автодорог (тыс.км) к площади территории;
-плотность населения определяется как отношение среднегодовой численности населения (тыс.чел) к площади территории (тыс. км2).
12.Сводный показатель уровня развития отраслей социальной инфраструктуры, рассчитываемый на основе четырёх первичных индикаторов:
 обеспеченность дошкольными образовательными учреждениями (мест на 1000 детей дошкольного возраста);
обеспеченность дошкольными образовательными учреждениями (мест на 1000 детей дошкольного возраста);
 выпуск специалистов высшими и государственными учебными заведениями (чел. на 10 тыс. жителей);
выпуск специалистов высшими и государственными учебными заведениями (чел. на 10 тыс. жителей);
 обеспеченность лечебными амбулаторными учреждениями (посещений в смену на 10 тыс. жителей);
обеспеченность лечебными амбулаторными учреждениями (посещений в смену на 10 тыс. жителей);  обеспеченность врачами и средним медицинским персоналом (чел. на 10 тыс. жителей).
обеспеченность врачами и средним медицинским персоналом (чел. на 10 тыс. жителей).
Расчёт интегрального показателя комплексной оценки проводится поэтапно:
На 1 этапе по каждому из базовых оценочных индикаторов, кроме последнего, определяется ранг каждого региона, а также ранг среднерос-
32
сийского значения, начиная с лучшего значения (1 место) и заканчивая худшим значением (последнее место).
По сводному показателю уровня развития отраслей социальной инфраструктуры сначала аналогично определяются ранги четырех перечисленных выше индикаторов по социальной сфере, потом полученные ранги суммируются и определяется интегрированный ранг по свободному показателю уровня развития социальной инфраструктуры каждого региона, а также среднероссийского значения.
В том случае, если по какому-либо показателю имеют место абсолютно одинаковые значения по двум или нескольким регионам, производится операция локального ранжирования данных регионов в соответствии со значениями ключевого показателя – объёма валового регионального продукта с учётом уровня покупательной способности на душу населения.
На 2 этапе производится расчет балльной оценки по каждому из показателей для каждого региона. Определяется эта оценка как разница между рангом показателя по РФ и рангом показателя по региону.
На 3 этапе для каждого региона производится операция суммирования приведённых балльных оценок по всем 12 базовым индикаторам с последующим делением полученного результата на 12 , и таким образом определяется искомая интегральная оценка уровня социальноэкономического развития каждого региона.
Общие прогнозы социально-экономического развития России и её регионов основываются на частных прогнозах – природно-ресурсных, демографических, научно-технических и др. Данные долгосрочного прогноза должны закладываться в основу подготовки прогнозов и программ на среднесрочную перспективу, а последние – в основу краткосрочных прогнозов и программ. Региональный аспект прогнозирования отражается в правительственных программах углубления экономической реформы, стабилизации и развития экономики России.
33
2.2. Методы прогнозирования экономики региона
2.2.1. Методы прогнозной экстраполяции
Для прогнозирования экономического развития региона используются различные методы, наиболее распространенные – это методы прогнозной экстраполяции и методы моделирования.
Сущность методов прогнозной экстраполяции состоит в анализе изменений объектов исследования во времени и распространение выявленных закономерностей на будущее.
Термин «экстраполяция» имеет несколько толкований. В широком смысле слова экстраполяция – это метод научного исследования, заключающийся в распространении выводов, полученных из наблюдения над одной частью явления, на другую его часть. В узком смысле слова экстраполяция – это нахождение по ряду данных функции других ее значений, находящихся вне этого ряда. Экстраполяция заключается в изучении сложившихся в прошлом и настоящем устойчивых тенденций экономического развития и перенесении их на будущее.
В прогнозировании экстраполяция (экстраполирование) применяется при изучении временных рядов и представляет собой нахождение значений функции за пределами области ее определения с использованием информации о поведении данной функции в некоторых точках, принадлежащих области ее определения.
Временной ряд представляет собой совокупность последовательных измерений показателя (объем валовой продукции, объем валовых инвестиций, численность занятых в экономике и др.) , произведенных через одинаковые интервалы времени. Анализ временных рядов позволяет решать следующие задачи:
34
исследовать структуру временного ряда, включающую, как правило, тренд – закономерные изменения среднего уровня, а также случайные периодические колебания;
исследовать причинно-следственные взаимосвязи между процессами, проявляющими в виде корреляционных связей между временными рядами;
построить математическую модель процесса, представленного временным рядом;
преобразовать временной ряд средствами сглаживания и фильтра-
ции.
Анализ тренда предназначен для исследования изменений среднего значения временного ряда с построением математической модели тренда и с прогнозированием на этой основе будущих значений ряда. Анализ тренда выполняется на основе методов прогнозной экстраполяции, регрессионных моделей и производственных функций. Далее мы подробно рассмотрим каждый из этих методов.
В практической работе временные ряды прогнозируемых показателей приближают следующими элементарными функциями:
У= а0 + а1Х (уравнение прямой линии) ;
У= а0 + а1Х + а2Х2 (парабола второго порядка) ;
У= а0 + а1Х+а2Х2+а3Х3 (парабола третьего порядка) ;
У= а0 + а1lnX (логарифмическая) ;
У= а0Ха1 (степенная) ;
У= а0 + а1х (показательная) .
Различают перспективную и ретроспективную экстраполяцию. Перспективная экстраполяция предполагает продолжение уровней ряда динамики на будущее на основе выявленной закономерности изменения уровней в изучаемом отрезке времени. Ретроспективная экстраполяция характеризуется продолжением уровней ряда динамики в прошлое.
Понятием, противоположным экстраполяции, является интерполяция, интерполирование, которое предусматривает нахождение промежуточных значений функции в области ее определения.
При экстраполяции предполагается, что:

35
 текущий период изменения показателей может быть охарактеризован траекторией – трендом;
текущий период изменения показателей может быть охарактеризован траекторией – трендом;
 основные условия, определяющие технико-экономические показатели в текущем периоде, не претерпят существенных изменений в будущем, т.е. в будущем они будут изменяться по тем же законам, что и в прошлом, и в настоящем;
основные условия, определяющие технико-экономические показатели в текущем периоде, не претерпят существенных изменений в будущем, т.е. в будущем они будут изменяться по тем же законам, что и в прошлом, и в настоящем;
 отклонения фактических значений показателей от линии тренда носят случайный характер и распределяются по нормальному закону.
отклонения фактических значений показателей от линии тренда носят случайный характер и распределяются по нормальному закону.
Простая экстраполяция. Этот метод предполагает расчет простого среднего значения показателя, который закладывается в основу краткосрочного прогноза. Так, положим необходимо обосновать краткосрочный прогноз темпа прироста ВРП в регионе, т.е. необходимо определить среднеарифметическую величину:
n |
xi |
|
|
Xn = |
|
, Xn – прогнозируемая величина; xi – темп прироста в i го- |
|
n |
|||
i 1 |
|
ду; n – число рассматриваемых лет.
Известно, что за прошедшие 10 месяцев темп прироста ВРП в регионе составил (табл. 2.1):
Таблица 2.1
Динамика темпа прироста ВРП в регионе (в сопоставимых ценах, по сравнению с предыдущим месяцем)
1 мес. |
2мес. |
3мес. |
4 мес. |
5 мес. |
6 мес. |
7мес. |
8 мес. |
9 мес. |
10мес |
|
|
|
|
|
|
|
|
|
|
0,25 |
0,28 |
0,2 |
0,24 |
0,23 |
0,29 |
0,27 |
0,22 |
0,23 |
0,28 |
|
|
|
|
|
|
|
|
|
|
Расчет. Учитывая определенную стабильность экономического развития региона, составим прогноз темпа прироста ВРП на основе его среднего значения за месяц:
Xn= (0,25+0,28+0,2+0,24+0,23+0,29+0,27+0,22+0,23+0,28): 10= 0,25
Можно рассчитать среднюю ошибку прогноза по формуле1:
2
n ,
1 Замков О. О. Толстопятенко А. В. , Черемных Ю. Н. Математические методы в экономике. М. : ДИС, 1998. С.18 .

36
где - средняя ошибка; 2 – дисперсия, определяемая по формуле
|
(x |
x)2 |
||
2 = |
n |
|
. |
|
n |
1 |
|||
|
|
|||
Средняя ошибка прогноза составит 0,09.
Вывод Прогноз темпа прироста ВРП в регионе на следующий месяц составит 0,25 и при сохранении тенденций развития может иметь отклоне-
ние 0,09.
Метод наименьших квадратов. Сущность метода наименьших квадратов состоит в минимизации суммы квадратических отклонений между наблюдаемыми и расчетными величинами. Считается, что этот метод лучше других соответствует идее усреднения, как единичного влияния учтенных факторов, так и общего влияния неучтенных.
Рассмотрим случай линейной зависимости между переменными Y и Х. Линейная зависимость имеет вид: Yt = a0 +a1Xt. Необходимо определить числовые параметры (а0 и а1), которые наилучшим образом описали бы зависимость, полученную при наблюдении. Наилучшее согласование достигается в случае, когда сумма квадратов отклонений опытных точек от точек, рассчитанных по теоретической кривой, обращается в минимум:
n |
|
S = |
(Yi Yit)2 = min . |
i |
1 |
Так как, по условию, Yt = a0 +a1Xt, то
n
S = (Yi a0 a1Xi)2 = min .
i 1
Функция S – функция двух независимых переменных а0 и а1. Для определения экстремума функции нескольких переменных необходимо обращение в ноль ее частных производных первого порядка. Далее необходимо сократить все члены уравнений на 2 и сгруппировать члены, содержащие а0 и а1, тогда получим:
|
n |
n |
na0 + a1 |
Xi |
Yi , |
|
i 1 |
i 1 |
n |
n |
n |
a0 Xi a1 |
Xi2 |
XiYi . |
i 1 |
i 1 |
i 1 |

37
Теперь для определения а0 и а1 необходимо решить систему уравнений с двумя неизвестными.
Пример. Описать линейную зависимость между выпуском валовой продукции в регионе Y и численностью работающих X и составить прогноз валового выпуска продукции в регионе при условии, что численность работающих увеличится на 20% по сравнению с последним наблюдением. Данные представлены в таблице 2.2
Таблица 2.2 Динамика валового выпуска продукции и численность занятых в ре-
гионе (данные условные)
|
1 год |
2 год |
3 год |
4 год |
|
|
|
|
|
Xi тыс. чел |
10 |
30 |
50 |
70 |
|
|
|
|
|
Yi млн р. |
11 |
13 |
16 |
18 |
|
|
|
|
|
Решение: При n=4 имеем
4 |
4 |
|
Xi = 10+30+50+70=160 ; |
Yi = 11+13+16+18=58 ; |
|
i 1 |
i |
1 |
4 |
4 |
|
XiYi =2560 ; |
Xi2 = 8400 . |
|
i 1 |
n 1 |
|
Получим систему уравнений:
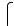 4а0 + 160а1 = 58 , 160а0 +8400а1 = 2560 .
4а0 + 160а1 = 58 , 160а0 +8400а1 = 2560 .
Решением системы уравнений является: а0 = 9,7 и а1 = 0,12 Тогда зависимость имеет вид: Yt = 9,7 +0,12Xt .
Для расчета ошибки прогноза определим отклонение фактических значений Y от расчетных.
Результаты представим в виде таблицы:
Год |
1 |
2 |
3 |
4 |
|
|
|
|
|
Yфактическое |
11 |
13 |
16 |
18 |
|
|
|
|
|
Yрасчетное |
10,9 |
13,3 |
15,7 |
18,1 |
|
|
|
|
|
Yр -Yф |
-0,1 |
0,3 |
-0,3 |
0,1 |
|
|
|
|
|

38
Тогда ошибка прогноза равна:
t = |
( 0,1)2 (0,3)2 ( 0,3)2 0,12 |
= 0,26 |
|
3 |
|||
|
|
При условии, что численность работающих в регионе увеличится на
20%, тогда Yt = 9,7 + 0,12*84=19,78 тыс. руб .
Вывод При увеличении численности занятых в регионе на 20% по сравнению с последним наблюдением объем выпуска валовой продукции в регионе составит 19,78 тыс. руб. т. е. увеличится на 9,8%, при сохранении тенденций развития может иметь отклонение 0,26.
Метод наименьших квадратов широко применяется в прогнозировании в силу простоты и возможности реализации на ЭВМ. Недостаток данного метода состоит в том, что модель тренда жестко фиксируется, а это делает возможным его применение только при небольших периодах упреждения, т.е. при краткосрочном прогнозировании.
Метод скользящей средней. Метод скользящей средней применяется в том случае, когда ряды динамики характеризуются резкими колебаниями показателей по годам. Такие ряды, как правило, имеют слабую связь со временем и не обнаруживают четкой тенденции изменения. Наиболее распространенным и простым путем выявления тенденции развития является сглаживание или выравнивание динамического ряда.
Суть различных приемов, с помощью которых осуществляется сглаживание или выравнивание, сводится к замене фактических уровней динамического ряда расчетными, имеющими меньшую колеблемость, чем исходные данные.
Один из наиболее простых приемов сглаживания заключается в расчете скользящих средних, их применение позволяет сгладить периодические и случайные колебания и тем самым выявить имеющуюся тенденцию в развитии.
Метод скользящих средних позволяет отвлечься от случайных колебаний временного ряда, что достигается путем замены значений внутри выбранного интервала средней арифметической величиной. Интервал, ве-
39
личина которого остается постоянной, постепенно сдвигается на одно наблюдение. Величина интервала скольжения Р может принимать любое значение от минимального (Р=2) до максимального (Р = N –1, где N – длина рассматриваемого временного ряда). Сглаженный ряд короче первоначального на Р–1 наблюдение.
При использовании метода скользящих средних прежде всего определяют величину интервала скольжения, обеспечивающую взаимное погашение случайных отклонений во временном ряду. Если наблюдается определенная цикличность изменения показателей, интервал скольжения должен быть равен продолжительности цикла. При отсутствии цикличности в изменении показателей рекомендуется производить многовариантный расчет при изменяющемся параметре сглаживания. Лучший вариант Р определяется на основании последующей оценки выровненных рядов (по коэффициентам, темпам роста и т.д.). Найденный таким образом параметр скольжения затем используется для прогнозирования социальноэкономических процессов.
Для любого интервала скользящая средняя исчисляется по формуле
Yk = Р1
P
X k i ,
i 1
где Xk-i – реальное значение показателя в момент времени tk-i; Р – интервал скольжения;
Yk – значение скользящей средней для момента времени tk.
Пример Имеется временной ряд показателя объема валовой продукции в регионе в сопоставимых ценах за 7 лет. (см. табл. 2.3 ). Используя метод скользящей средней, сделать прогноз валового выпуска продукции в регионе на последующий 8 год.
|
|
|
|
|
|
|
Таблица 2.3 |
|
|
|
|
|
Годы |
|
|
|
|
|
|
|
|
|
|
|
|
|
ВРП, |
1-й |
2-й |
3-й |
4-й |
5-й |
6-й |
|
7-й |
млн.руб. |
|
|
|
|
|
|
|
|
100 |
60 |
50 |
110 |
90 |
80 |
|
70 |
|
|
|
|
|
|
|
|
|
|
Источник: данные условные

40
Используя метод скользящей средней, определяем сглаженный временной ряд. Считаем, что Р = 3, тогда
Y4 = |
100 |
60 |
50 |
= 70 |
; |
|
Y5 = |
60 50 110 |
|
= 73 ; |
|
||||||||||
|
|
|
|
3 |
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3 |
|
|
|
|
|
Y6 = |
50 |
110 |
90 |
= 83 |
; |
|
Y7 = |
110 |
90 80 |
= 73 ; |
|
||||||||||
|
|
|
3 |
|
|
|
|
|
3 |
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Y8 = |
90 |
80 |
70 |
= 80 |
; |
|
|
|
|
|
|
|
|
|
|
||||||
|
|
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Годы |
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
1-й |
|
|
|
|
2-й |
3-й |
4-й |
|
5-й |
6-й |
|
7-й |
8-й |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(прогноз) |
ВРП, |
|
100 |
|
60 |
50 |
110 |
|
90 |
80 |
|
|
70 |
- |
||||||||
млн руб . |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
фактический |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
ВРП, |
|
100 |
|
60 |
50 |
70 |
|
73 |
83 |
|
|
93 |
80 |
||||||||
млн руб . |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
сглаженный |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
Ответ: прогнозируемый объем валового выпуска в 8 году исследования в регионе составит 80 млн руб.
Метод экспоненциального сглаживания. Метод экспоненциаль-
ного сглаживания, разработанный Р. Брауном, дает возможность получить оценки параметров тренда, характеризующие не средний уровень процесса, а тенденцию, сложившуюся к моменту последнего наблюдения. Данный метод позволяет давать обоснованные прогнозы на основании рядов динамики, имеющих умеренную связь во времени, и обеспечивает большой учет показателей, достигнутых в последние периоды наблюдения.
Суть метода заключается в сглаживании временного ряда с помощью взвешенной скользящей средней, в которой веса подчинены экспоненциальному закону. Метод экспоненциального сглаживания не просто экстраполирует действующие зависимости в будущее, а приспосабливается, адаптируется к изменяющимся во времени условиям. Поэтому он является эффективным и надежным методом среднесрочного прогнозирования.
Рассмотрим применение метода экспоненциального сглаживания для наиболее распространенного случая, когда тренд описывается линейной
41
функцией. В этом случае используется полином первой степени и тренд выражается двумя членами ряда Тейлора и некоторым малым числом t , зависящим от времени:
Y = A+Bt+ t .
Данное выражение называют линейной моделью Брауна. При выборе начальных условий Браун рекомендует рассчитывать А, В путем выравнивания исходного временного ряда способом наименьших квадратов.
Процесс экспоненциального сглаживания основывается на цепочечных расчетах. Сначала устанавливаются исходные параметры выравнивающих кривых А,В по которым с помощью формул находятся начальные условия. На основе этих условий по формулам определяются характеристики сглаживания, затем – оценки коэффициентов для экспоненциального сглаживания первого порядка в исходном динамическом ряду и, наконец, расчетное значение линейной (y=A+Bt). Полученные на первом этапе характеристики сглаживания затем используются в качестве исходных данных для вычисления второго сглаженного значения в рассматриваемом динамическом ряду и т.д. Вычисления продолжаются до тех пор, пока не будут сглажены все значения исходного временного ряда.
Коэффициенты уравнения (оценки коэффициентов), найденные при экспоненциальном сглаживании последнего значения в исходном динамическом ряду, используются для последующего прогноза.
Начальные приближения для случая линейного тренда равны: экспоненциальная средняя 1-го порядка:
S10 (y) = A - 1 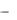 B ;
B ;
экспоненциальная средняя 2-го порядка:
S 02 (y) = A - 2(1 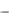 ) B ,
) B ,
где – параметр сглаживания.
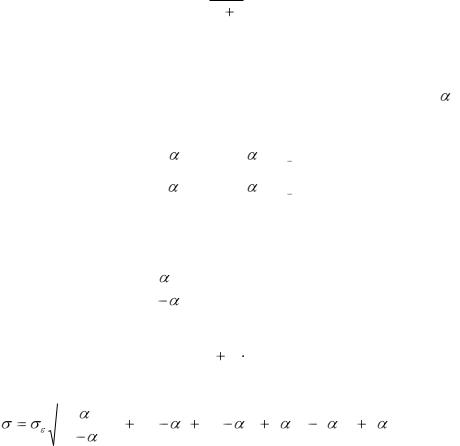
В зависимости от величины параметра прогнозные оценки по разному учитывают влияние исходного ряда наблюдений: чем больше , тем больше вклад последних наблюдений в формирование тренда, а влияние начальных условий убывает быстро. При малом 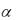 прогнозные оценки
прогнозные оценки
42
учитывают все наблюдения, при этом уменьшение влияния более ранней информации происходит медленно.
Для приближенной оценки 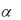 используют соотношение Брауна:
используют соотношение Брауна:
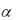 = т2 1 ,
= т2 1 ,
где m – число наблюдений (точек) в ретроспективном динамическом
ряду.
Зная начальные условия S1 (y), S 2 |
(y) и значение параметра , вы- |
|||||||||||||||||||
|
|
|
|
0 |
|
|
0 |
|
|
|
|
|
|
|
||||||
числяют экспоненциальные средние 1-го и 2-го порядка: |
||||||||||||||||||||
|
S1 |
(y) = |
|
y |
+ (1- |
) S1 |
1 |
(y); |
||||||||||||
|
|
t |
|
|
|
|
|
|
t |
|
|
|
|
|
t |
|
|
|||
|
S 2 |
(y) = |
|
S1 |
+ (1- |
) S 2 |
1 |
(y). |
||||||||||||
|
|
t |
|
|
|
|
|
|
t |
|
|
|
|
|
t |
|
|
|||
Оценки коэффициентов линейного тренда: |
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
A = 2 S1 |
(y) - S 2 |
(y); |
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
t |
|
|
|
|
t |
|
|
|
|
|
|
|
|
|
|
|
|
[ S1 (y) - S 2 (y)]. |
|||||||||||||
|
|
|
В = |
|
|
|||||||||||||||
|
|
|
|
|
||||||||||||||||
|
|
|
|
1 |
|
|
t |
|
|
|
t |
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
Прогноз на время t равен: |
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
yt= А |
|
В t |
|
|
|
|
|||||
Ошибка прогноза: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
[1 |
4(1 |
) |
5(1 |
)2 |
2 |
(4 3 ) p 2 2 p2 ] , |
||||||||||||
(2 )3 |
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
где p – период прогноза.
Рассмотрим пример Пусть задан временной ряд показателя валовой продукции (yt ) в регионе за 4 года ( см. табл.2.4) в млрд руб. в сопоставимых ценах:
Таблица 2.4 Динамика ВНП в регионе (в сопоставимых ценах)
t |
1 |
2 |
3 |
4 |
|
|
|
|
|
yt |
40 |
43 |
46 |
48 |
Используя метод экспоненциального сглаживания, построить прогноз валового выпуска на 5 год.
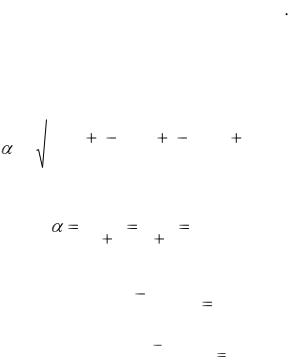
43
Согласно имеющейся динамике показателя валовой продукции, можно предположить, что тренд описывается линейной функцией.
Определим коэффициенты прямой y = A +B*t по методу наименьших квадратов. Для этого вычислим ряд промежуточных значений и их суммы.
Результаты занесем в таблицу 2.5 .
Расчет методом экспоненциального сглаживания
|
|
|
|
|
Таблица 2.5 |
|
|
|
|
|
|
|
|
Период, t |
Фактиче- |
|
Расчетные значения |
|
|
|
|
|
|
|
|
|
|
|
ское зна- |
t2 |
tyt |
y=37,5+ |
|
y-yt |
|
чение yt |
|
|
2,7*t |
|
|
|
|
|
|
|
|
|
1 |
40 |
1 |
40 |
40,2 |
|
0,2 |
|
|
|
|
|
|
|
2 |
43 |
4 |
86 |
42,9 |
|
-0,1 |
|
|
|
|
|
|
|
3 |
46 |
9 |
138 |
45,6 |
|
-0,4 |
|
|
|
|
|
|
|
4 |
48 |
16 |
192 |
48,3 |
|
0,3 |
|
|
|
|
|
|
|
Итого10 |
177 |
30 |
456 |
|
|
|
|
|
|
|
|
|
|
А = 37,5; В = 2,7
Тогда уравнение прямой имеет вид: y = 37,5+ 2,7 t
Подставив в него значения t = 1,2,3,4, получим расчетные значения тренда (см. таблицу 2.6) .
Основная ошибка:
t = |
0,22 |
( 0,1)2 |
|
( 0,4)2 0,32 |
|
|
|
3 |
= 0,3 |
||
|
|
|
|
|
|
2. Параметр сглаживания:
2 |
|
2 |
0,4 . |
|
|
|
|
||
N 1 |
4 1 |
|||
|
||||
3. Начальные условия: |
|
|
|
|
|
S10 (y) = 37,5 – |
1 0,4 |
2,7 |
33,45; |
||
|
0,4 |
|
|
|
|
S 02 (y) = 37,5 – |
|
2(1 0,4) |
2,7 |
29,4. |
|
|
|||||
|
0,4 |
|
|
|
|
4. Для t =2 вычисляем экспоненциальные средние:

44
S12 = 0,4 ∙ 40+0,6.33,45 = 36;
S 22 = 0,4 ∙ 36+0,6.29,4 = 32.
Далее вычисляем значения коэффициентов:
A =2∙36–32 = 40;
|
|
|
|
|
|
|
|
|
0,4 |
|
|
|
|
2,6 ; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В = |
|
(36 32) |
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
1 |
0,4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
прогнозируемые значения: |
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
y2 = 40+2,6 ∙ 1 = 42,6; |
|
|
|
|
||||||||||||
|
|
отклонения от фактического значения: |
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
y2 = 42,6 – 43 = – 0,4. |
|
|
|
|
||||||||||||
Аналогичные вычисления выполним для t = 3(1999г.), t = |
4(2000г.), |
|||||||||||||||||||||
результаты представим в таблице: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
Прогнозирование методом экспоненциального сглаживания |
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 2.6 |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Периодt |
Факт. |
|
|
|
|
|
|
|
|
|
Расчетные значения |
|
|
|
|
|||||||
|
значение |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
S 1t |
|
|
|
|
S t2 |
|
А |
|
|
В |
|
yt |
y |
|
||||||
|
yt |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
40 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
2 |
43 |
36 |
|
|
32 |
|
40 |
|
2,6 |
|
42,6 |
|
-0,4 |
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
3 |
46 |
38,6 |
|
|
34,6 |
|
42,6 |
|
2,7 |
|
45,3 |
|
-0,7 |
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
4 |
48 |
41,6 |
|
|
37,4 |
|
45,8 |
|
2,8 |
|
48,6 |
|
0,6 |
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
p=1 |
- |
44,2 |
|
|
40,1 |
|
48,3 |
|
2,7 |
|
51 |
|
- |
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
При построении модели прогноза на 5-й год период прогноза р = 1, |
||||||||||||||||||||||
тогда окончательная модель прогноза имеет вид: |
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
yt+p = 48,3+2,7p |
|
|
|
|
|||||||||||
|
|
|
|
|
|
y5 = 48,3+2,7∙ 1= 51. |
|
|
|
|
||||||||||||
Ошибка прогноза |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,3 |
|
0,4 |
[1 4 0,6 |
5 0,62 |
0,8 2,8 1 0,32 12 ] = 0,46. |
|
|||||||||||||||
|
(1,6)3 |
|
||||||||||||||||||||
Ответ Прогноз валового выпуска в регионе на следующий год составит 51 млрд руб., при сохранении тенденций развития может иметь отклонение 0,46.
45
2.2.2. Методы моделирования
Большинство явлений и процессов в экономике находятся в постоянной взаимной и объективной связи. Исследование зависимостей и взаимосвязей между объективно существующими явлениями и процессами играет большую роль в региональной экономике. Оно дает возможность глубже понять сложный механизм причинно-следственных отношений между региональными экономическими явлениями. Для исследования интенсивности, вида и формы зависимостей широко применяется корреляци- онно-регрессионный анализ, который является методическим инструментарием при решении задач прогнозирования и планирования регионального развития.
Различают два вида зависимостей между экономическими явлениями
ипроцессами: функциональную и стохастическую (вероятностную, статистическую).
Вслучае функциональной зависимости имеется однозначное отображение множества А на множество В. Множество А называют областью определения функции, в множество В – множеством значений функции.
Функциональная зависимость встречается редко. В большинстве случаев функция (Y) или аргумент (Х) – случайные величины. Х и Y подвержены действию различных случайных факторов, среди которых могут быть факторы, общие для двух случайных величин.
Статистической называется зависимость между случайными величинами, при которой изменение одной из величин влечет за собой изменение закона распределения другой величины. В этом случае говорят о корреляционной зависимости. В экономике приходится иметь дело со многими явлениями, имеющими вероятностный характер. Например, к числу случайных величин можно отнести: стоимость продукции, доходы бюджетов
идр.
Односторонняя вероятностная зависимость между случайными величинами есть регрессия. Она устанавливает соответствие между этими величинами.
46
Односторонняя стохастическая зависимость выражается с помощью функции, которая называется регрессией. В общем виде такая зависимость может быть представлена следующим образом:
Yit = f (Xkt, et ),
где Yit – i-я зависимая переменная в момент времени t; Xkt – k-я независимая переменная (фактор) в момент времени t; et – ошибка наблюдения в момент времени t.
Уравнение регрессии характеризует взаимосвязь переменных X и Y в том смысле, что показывает, как изменяется величина Y в зависимости от изменения величины Х.
Перечислим различные виды регрессии.
1. Регрессия относительно числа переменных:
–простая регрессия – регрессия между двумя переменными;
–множественная регрессия – регрессия между зависимой переменной Y и несколькими независимыми переменными Х1,Х2…Хm.
2. Регрессия относительно формы зависимости:
–линейная регрессия, выражаемая линейной функцией;
–нелинейная регрессия, выражаемая нелинейной функцией.
3. В зависимости от характера регрессии различают:
–положительную регрессию.Она имеет место, если с увеличением (уменьшением) независимой переменной значения зависимой переменной также соответственно увеличиваются (уменьшаются);
–отрицательную регрессию. В этом случае с увеличением или уменьшением независимой переменной зависимая переменная уменьшается или увеличивается.
Регрессия тесно связана с корреляцией. Корреляция в широком смысле слова означает связь, соотношение между объективно существующими явлениями. Связи между явлениями могут быть различны по силе. При измерении тесноты связи говорят о корреляции в узком смысле слова.
Понятия «корреляция» и «регрессия» тесно связаны между собой. В корреляционном анализе оценивается сила связи, а в регрессионном анализе исследуется ее форма. Корреляция в широком смысле объединяет корреляцию в узком смысле и регрессию.
47
Исследование корреляционных связей называют корреляционным анализом, а исследование односторонних стохастических зависимостей – регрессионным анализом. Корреляционный и регрессионный анализ имеют свои задачи.
Задачи корреляционного анализа :
1. Измерение степени связности (тесноты, силы) двух и более явле-
ний.
2.Отбор факторов, оказывающих наиболее существенное влияние на результирующий признак, на основании измерения тесноты связи между явлениями.
3.Обнаружение неизвестных причинных связей. Корреляция непосредственно не выявляет причинных связей между явлениями, но устанавливает степень необходимости этих связей и достоверность суждений об их наличии. Причинный характер связей выясняется с помощью логиче- ски-профессиональных суждений, раскрывающих механизм связей.
Перечислим задачи регрессионного анализа:
1.Установление формы зависимости (линейная, нелинейная, положительная или отрицательная и т.д.) .
2.Определение функции регрессии и установление влияния факторов на зависимую переменную. Важно не только определить форму регрессии, указать общую тенденцию изменения зависимой переменной, но
ивыяснить, каково было бы действие на зависимую переменную главных факторов, если прочие не изменились и если бы были исключены случайны элементы. Для этого определяют функцию регрессии в виде математического уравнения того или иного типа.
Построение корреляционно-регрессионной модели осуществляется в несколько этапов:
1.Постановка задачи.
2.Сбор статистических данных.
3.Корреляционно-регрессионный анализ данных.
4.Прогнозирование на основе полученной зависимости.

48
Постановка задачи. На первом этапе дается постановка задачи. Например, определить численность занятых в стране в зависимости от произведенного валового продукта; зависимость затрат от количества работников на предприятии и т.д. На этом этапе также считается, что связь между независимыми показателями и результирующим показателем (зависимым) может существовать и характеризуется функцией Y= f(Xn).
Сбор статистических данных. Статистические данные набираются на основе первичных документов и отчетных данных. Некоторые показатели могут быть получены только после предварительной обработки полученной информации. При сборе данных необходимо определить количество выборочных наблюдений или выборочную совокупность, т.е. часть наблюдений, отобранных для дальнейшего исследования.
Объем выборочных наблюдений (Кв) определяется по формуле предельной ошибки случайной бесповторной выборки:
2 2
Кв=
2 2 |
( у)2 |
где N – величина генеральной совокупности, т.е. величина всей совокупности наблюдений, отображаемых результативных признаков и факторов;
2– дисперсия значений признака в генеральной совокупности;
у– предельная ошибка случайной бесповторной выборки;
 – коэффициент доверия.
– коэффициент доверия.
Дисперсия 2 является характеристикой рассеивания случайных величин, т.е. их отклонения от средней величины. Квадратный корень из дисперсии – среднее квадратическое отклонение определяется по формуле
 R6 ,
R6 ,
где R – разница между максимальным и минимальным значением признака (фактора). Она устанавливается на основе анализа данных.
Размеры предельной ошибки по абсолютной величине у задаются в зависимости от требований точности к полученным результатам. Например, если признак исчисляется в сотнях рублей, то предельная ошибка может быть установлена в рублях; если в днях, то в части дня (0,1дня).

49
Корреляционно-регрессионный анализ. После сбора данных осу-
ществляется их регрессионный анализ, который включает три этапа:
1)определение вида функции (уравнения регрессии);
2)определение тесноты связи между переменными;
3)установление числового значения параметров уравнения регрес-
сии.
На первом этапе определяется форма связи исследуемых показателей или уравнение регрессии. Функциональная зависимость определяется следующим образом: предположим, что линия регрессии переменной, кото-
рую мы обозначим У , от переменной Х имеет вид: У = а0 + а1Х+ – это простейший вид зависимости между двумя показателями – линейная зави-
симость. Здесь У – результативный показатель, а0 и а1– постоянные коэффициенты, Х – фактор, – добавочный коэффициент, при учете которого
У никогда не может попасть на линию регрессии, т.е. У Х.
Это уравнение можно использовать как предсказывающее уравнение, подстановка в него значения Х позволяет предсказать истинное среднее значение У для этого Х.
Проверка линейной зависимости может быть проведена путем сопоставления по собранным данным вариации результативного и факторного признаков. Любую форму зависимости можно проверить графическим путем, отмечая каждое наблюдение точкой в прямоугольной системе координат. По оси ординат откладываются значения У, а по оси абсцисс – значение Х.
Вторым этапом проверяется теснота связи выбранных показателей, т.е. насколько полно выбраны факторные признаки, как велико влияние неучтенных факторов. Поэтому оценка параметров регрессии обычно сопровождается расчетом такой дополнительной характеристики, как коэффициент корреляции, который представляет собой эмпирическую меру линейной зависимости между Х и Y:
|
|
yx |
|
|
|||
r = ( |
n |
|
|
|
|
|
, |
|
|
y x) |
|
||||
|
|
y |
|||||
y,x |
n |
|
|||||
|
|
|
|
||||
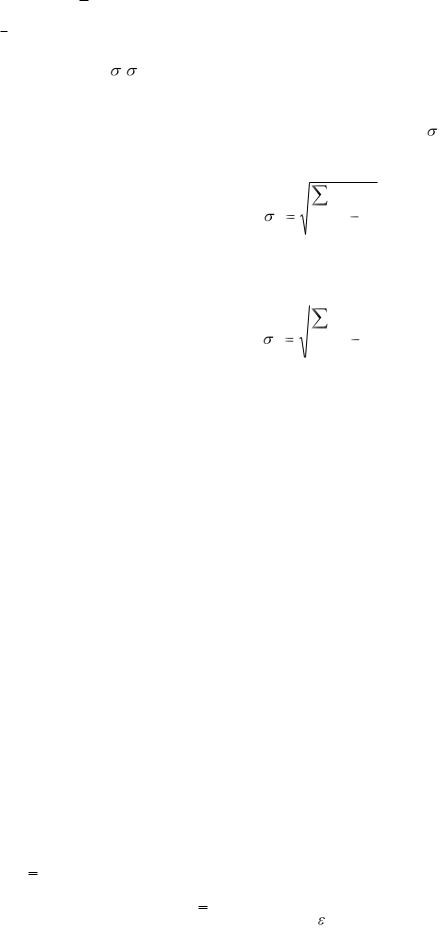
50
где y – среднеарифметическое значение результативных признаков; x – среднеарифметическое значение факторов; n- количество выборочных наблюдений; x y – среднее квадратическое отклонение результирующего и факторного признаков.
Среднее квадратическое отклонение фактора формуле
|
|
|
x2 |
|
|
||||
|
|
n |
|
|
|
x2 . |
|||
x |
|
|
|||||||
|
|
|
n |
||||||
Среднее квадратическое отклонение значений результирующего |
|||||||||
признака рассчитывается по формуле: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
y2 |
|
|
||||
|
|
n |
|
|
|
|
y2 . |
||
y |
|
|
|
|
|||||
|
|
|
n |
||||||
Величина коэффициента корреляции лежит между (-1;1). Чем выше значение коэффициента корреляции, тем теснее связь между переменными и тем точнее будет прогноз, произведенный на основе полученного уравнения регрессии. Если коэффициент корреляции равен +1, то связь между показателями выражается в прямой зависимости, т.е. при увеличении одного показателя увеличивается и второй, и наоборот. Если же коэффициент корреляции равен –1, то связь между двумя показателями выражается в обратной зависимости, т.е. при увеличении одного показателя другой уменьшается, и наоборот.
Завершающим этапом является определение численных значений постоянных коэффициентов уравнения регрессии (а0 и а1). Эти коэффициенты находятся в результате решения системы уравнений. Систему можно получить с помощью метода наименьших квадратов. Метод наименьших квадратов позволяет из бесчисленного множества прямых линий на плоскости выбрать одну, наилучшим образом соответствующую исходным данным.
Этот метод обладает определенными свойствами: пусть мы имеем множество из n наблюдений (Х1,Y1), (Х2,Y2)…(Хn, Yn). Тогда уравне-
ниеУ = а0 + а1Х+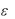 можно записать в виде:
можно записать в виде:
У i = а0 + а1Хi+ i, где i = 1,2…n.
51
Следовательно, сумма квадратов отклонений фактических значений от расчетных равна:
|
|
|
|
|
|
|
S= |
2= |
|
|
|
) 2 . |
|
|
|
||
|
|
|
|
|
|
|
(Y a0 a1X |
|
|
|
|||||||
|
|
|
|
|
|
|
|
i |
|
i |
i |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
i 1 |
|
|
|
|
|
|
|
|
|
|
Будем подбирать значения оценок а0 и а1 так, чтобы их подстановка |
||||||||||||||||
|
|
|
|
|
|
) 2 |
|
||||||||||
|
|
|
|
|
|
|
|||||||||||
в уравнение давала наименьшее значение S, т.е. (Y a0 |
a1X |
= S min |
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
i |
i |
|
|
|
|
Определим |
а0 |
и |
а1 |
, |
дифференцируя |
|
уравнение |
|||||||||
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|||||||||||||
S= |
i |
2= ( |
Y |
a0 |
a1X |
) 2, сначала по а0, затем по а1, и приравняем резуль- |
|||||||||||
|
|
i |
i |
|
|
|
|
|
|
|
|
|
|
|
|
||
|
i 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
таты к нулю. Тогда получим:
|
|
|
|
n |
|
n |
|
|
|
||
|
|
na0 + a1 |
Xi |
|
|
Yi ; |
|
|
|||
|
|
|
|
i |
1 |
|
i 1 |
|
|
||
|
|
n |
n |
|
|
|
|
n |
|
|
|
|
a0 |
|
Xi |
a1 |
Xi2 |
|
|
XiYi . |
|
|
|
|
|
i |
1 |
i 1 |
|
i |
1 |
|
|
||
Эти уравнения представляют собой систему нормальных уравнений. |
|||||||||||
Отсюда находим коэффициенты регрессионной функции: |
|
||||||||||
|
XiYi [( |
|
Xi )( |
Y )]/ ni |
|
|
( X 2 |
X )(Y Y ) |
|
||
|
|
|
|
|
|
|
|
|
i |
i |
|
а1= |
n |
n |
|
|
|
|
= |
|
n |
|
. |
Xi 2 |
( |
Xi )2 / n |
|
( X i |
X )2 |
||||||
|
|
|
|
||||||||
|
n |
|
n |
|
|
|
|
|
n |
|
|
Решение системы уравнений относительно а0: а0 =Y – a1X. С помо-
щью подстановки этого уравнения в уравнение У i = а0 + а1Хi+ i получим оцениваемое уравнение регрессии Yi = Y+a1X.
Для практического использования регрессионных моделей важно установить, насколько точно могут быть рассчитаны значения исследуемого показателя по заданным значениям факторов. Для оценки точности уравнений регрессии на практике используют ряд показателей: коэффициент множественной корреляции (детерминации), критерий Фишера, остаточная дисперсия, критерий Стьюдента и др.1
Следует отметить, что регрессионные приемы анализа и прогнозирования не вскрывают специфические причины изучаемых явлений, а только дают возможность определить количественную величину связей между
1 См . подробнее: Бережная Е. В. Математические методы моделирования экономических систем. М. : Финансы и статистика, 2001. С.143 – 147.
52
ними. Причины могут быть вскрыты только при тщательном изучении технической, технологической и организационной сторон процесса производства и экономических отношений.
Рассмотрим пример прогноза валовой продукции в регионе на основе использования корреляционно-регрессионного анализа.
Известна динамика ВРП в регионе за 25 лет (с1976 г. по 2000 г.) в сопоставимых ценах. Максимальный объем ВРП за исследуемый период составляет 15 млрд руб., минимальный 6 млрд. руб. Тогда R = 15-6 = 9 млрд руб. Величина предельной ошибки принимается равной 0,1 млрд руб., а коэффициент доверия равен 2. Определим объем выборочных
наблюдений: Кв = |
22 |
1,52 |
25 |
24,5 . |
22 1,52 25 0,12 |
||||
Таким образом, для того чтобы получить результат выборки с точностью до 0,1 млрд руб., необходимо сделать 25 наблюдений.
Таблица 2.5 Динамика ВРП в регионе (в сопоставимых ценах, в млдр руб.)
Показатель/год |
ВРП, млрд руб |
1 |
10 |
2 |
12,5 |
3 |
12,8 |
4 |
12,9 |
5 |
13,2 |
6 |
13,5 |
7 |
13,8 |
8 |
13,8 |
9 |
13,9 |
10 |
14,1 |
11 |
14,5 |
12 |
14,6 |
13 |
15,0 |
14 |
14,9 |
15 |
14,8 |
16 |
11,6 |
17 |
10,2 |
18 |
9,3 |
19 |
8,0 |
20 |
8,6 |
21 |
7,1 |
22 |
6,3 |
23 |
6,0 |
24 |
8,8 |
25 |
9,1 |
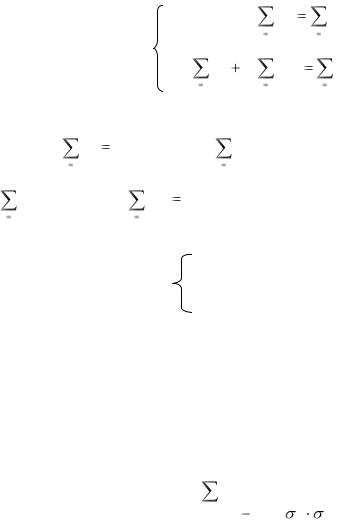
|
|
|
|
|
|
|
|
53 |
|
|
|
|
|
Согласно |
таблице |
можно предположить, что зависимость между |
|||||||||||
У (объем ВРП в регионе) и Х (год наблюдения) имеет линейный вид: |
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
У = а0 + а1Х. |
|||||||
Для определения а0 и а1 воспользуемся методом наименьших квад- |
|||||||||||||
ратов. Решим систему уравнений: |
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
n |
n |
|||
|
|
|
|
|
na0 + a1 |
Xi |
|
Yi ., |
|||||
|
|
|
|
|
|
|
|
|
i |
1 |
i 1 |
||
|
|
|
|
|
n |
|
n |
|
n |
||||
|
|
|
|
|
a0 |
Xi |
|
a1 |
Xi2 |
|
|
XiYi . |
|
|
|
|
|
|
i |
1 |
|
|
i 1 |
i 1 |
|||
Пользуясь данными таблицы, найдем: |
|
|
|
||||||||||
n |
|
|
|
|
|
n |
|
|
|
|
|
|
|
N = 25; |
Xi 325; X = 13; |
Yi = 289,3; Y = 11,57 ; |
|||||||||||
i 1 |
|
|
|
|
|
i 1 |
|
|
|
|
|
|
|
n |
n |
|
|
|
|
|
|
|
|
|
|
|
|
XiYi = 3406,4; |
Х 2 |
5525. |
|
|
|
|
|
|
|
||||
i 1 |
i |
1 |
|
|
|
|
|
|
|
|
|
|
|
25а0+325а1 = 289,3 ;
325а0+5525а1=3406,4 .
Решаем систему уравнений относительно а1, находим:
а1 = – 0,067, тогда Y = Y+a1(Xi – X) ; |
|||||
Y = 11,57 – 0,067(X–13) = 12,44 – 0,067X . |
|||||
Оценим тесноту связи между фактором (Х) и результирующим пока- |
|||||
зателем (Y). |
|
|
|
|
|
|
|
yx |
|||
|
n |
|
|
|
|
ry,x = ( |
|
|
y x) / х у = – 0,69 . |
||
|
|
||||
|
|
n |
|||
Согласно полученному коэффициенту корреляции (– 0,69) можно сделать вывод, что связь между исследуемыми показателями значимая и обратная, т.е. с увеличением показателя X происходит уменьшение показателя Y.
Прогноз валового выпуска продукции в регионе в следующем (26 году) составит Y = 12,44 – 0,067*26 = 10,7 млрд руб.
Для функционального анализа экономических циклов одной макроэкономики недостаточно, любое современное хозяйство, включая и эконо-