


PROGRAMMING WITH INTEL MMX TECHNOLOGY
•Chapter 11, MMX Technology System Programming Model, in the IA-32 Intel Architecture Software Developer’s Manual, Volume 3 describes the manner in which MMX technology is integrated into the IA-32 system programming model.
9.2THE MMX TECHNOLOGY PROGRAMMING ENVIRONMENT
Figure 9-1 shows the execution environment for MMX technology. All MMX instructions operate on MMX registers, the general-purpose registers, and/or memory as follows:
•MMX registers — These eight registers (see Figure 9-1) are used to perform operations on 64-bit packed integer data. They are named MM0 through MM7.
Address Space
232 -1
MMX Registers
Eight 64-Bit
General-Purpose
Registers
Eight 32-Bit
0
Figure 9-1. MMX Technology Execution Environment
•General-purpose registers — The eight general-purpose registers (see Figure 3-5) are used with existing IA-32 addressing modes to address operands in memory. (MMX registers cannot be used to address memory). General-purpose registers are also used to hold operands for some MMX technology operations. They are EAX, EBX, ECX, EDX, EBP, ESI, EDI, and ESP.
9.2.1MMX Technology in 64-Bit Mode and Compatibility Mode
In compatibility mode and 64-bit mode, MMX instructions function like they do in protected mode. Memory operands are specified using the ModR/M, SIB encoding described in Section 3.7.5
9-2 Vol. 1

PROGRAMMING WITH INTEL MMX TECHNOLOGY
9.2.2MMX Registers
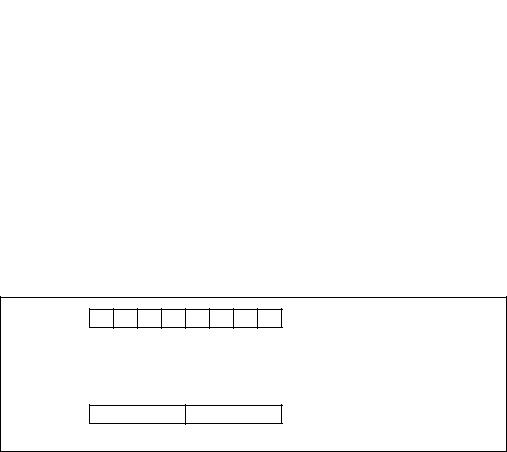
The MMX register set consists of eight 64-bit registers (see Figure 9-2), that are used to perform calculations on the MMX packed integer data types. Values in MMX registers have the same format as a 64-bit quantity in memory.
The MMX registers have two data access modes: 64-bit access mode and 32-bit access mode. The 64-bit access mode is used for:
•
•
•
•
64-bit memory accesses
64-bit transfers between MMX registers All pack, logical, and arithmetic instructions Some unpack instructions
The 32-bit access mode is used for:
•32-bit memory accesses
•32-bit transfer between general-purpose registers and MMX registers
•Some unpack instructions
63 |
0 |
MM7
MM6
MM5
MM4
MM3
MM2
MM1
MM0
Figure 9-2. MMX Register Set
Although MMX registers are defined in the IA-32 architecture as separate registers, they are aliased to the registers in the FPU data register stack (R0 through R7).
See also Section 9.5, “Compatibility with x87 FPU Architecture”.
Vol. 1 9-3
PROGRAMMING WITH INTEL MMX TECHNOLOGY
9.2.3MMX Data Types
MMX technology introduced the following 64-bit data types to the IA-32 architecture (see Figure 9-3):
•
•
•
64-bit packed byte integers — eight packed bytes 64-bit packed word integers — four packed words
64-bit packed doubleword integers — two packed doublewords
MMX instructions move 64-bit packed data types (packed bytes, packed words, or packed doublewords) and the quadword data type between MMX registers and memory or between MMX registers in 64-bit blocks. However, when performing arithmetic or logical operations on the packed data types, MMX instructions operate in parallel on the individual bytes, words, or doublewords contained in MMX registers (see Section 9.2.5, “Single Instruction, Multiple Data (SIMD) Execution Model”).
Packed Byte Integers
63 |
|
0 |
|
|
|
|
|
|
Packed Word Integers |
|
|
|
|
|
63 |
|
0 |
|
|
Packed Doubleword Integers
63 |
0 |
Figure 9-3. Data Types Introduced with the MMX Technology
9.2.4Memory Data Formats
When stored in memory: bytes, words and doublewords in the packed data types are stored in consecutive addresses. The least significant byte, word, or doubleword is stored at the lowest address and the most significant byte, word, or doubleword is stored at the high address. The ordering of bytes, words, or doublewords in memory is always little endian. That is, the bytes with the low addresses are less significant than the bytes with high addresses.
9.2.5Single Instruction, Multiple Data (SIMD) Execution Model
MMX technology uses the single instruction, multiple data (SIMD) technique for performing arithmetic and logical operations on bytes, words, or doublewords packed into MMX registers (see Figure 9-4). For example, the PADDSW instruction adds 4 signed word integers from one source operand to 4 signed word integers in a second source operand and stores 4 word integer results in a destination operand. This SIMD technique speeds up software performance by allowing the same operation to be carried out on multiple data elements in parallel. MMX
9-4 Vol. 1