

2.5. Выводы по главе 2
Результаты вычислительного эксперимента для задачи распределения температуры в тонком стержне показали наличие ускорения для СЛАУ без учета разреженности и существенного ускорения для СЛАУ с учетом разреженности. Что объясняется введением в алгоритм дополнительной проверки блоков.
Можно рекомендовать составление узконаправленных модификаций решений СЛАУ для практических задач. Однако в тех случаях, когда практическая задача сводится к системе малой или средней размерности, или когда задача имеет другие, более вычислительно трудоемкие участки, применение параллельных алгоритмов может не дать ожидаемого результата. Поэтому необходимо проводить предварительный анализ, в результате которого определять целесообразность составления параллельной модификации.
Самыми трудоемкими операциями при решении СЛАУ оказались матричные операции. Как уже отмечалось, основными способами уменьшения времени решения матричных задач в многопроцессорных системах передачи сообщений являются наиболее равномерное распределение вычислительной нагрузки по исполнителям и организация эффективных обменных взаимодействий. Рассмотрение последнего способа на примере задачи матричного умножения изложено в следующей главе.
Глава 3. Исследование организации обменных взаимодействий в модели передачи сообщений
Наиболее часто используемая модель параллельного программирования – модель передачи сообщений. Самым распространенным программным инструментом этой модели является коммуникационная библиотека MPI [4].
На ускорение параллельного решения любой сложной задачи в первую очередь оказывает влияние качество ее декомпозиции. Вторым по важности фактором, влияющим на ускорение в модели передачи сообщений, является организация обменных взаимодействий. Хорошо продуманная организация обменных взаимодействий может существенно ускорить последовательно-параллельные вычисления, а ошибка в организации может привести даже к замедлению параллельного решения, по сравнению с последовательным.
Организация вычислительного процесса в MPI строится по принципу обмена информацией между процессорами-исполнителями. Все обмены можно разделить на две категории – массовые обменные взаимодействия и точечные обмены.
В данной главе проведено исследование эффективности обменных взаимодействий и различной зернистости производимых разбиений на примере задачи умножения двух матриц. Выбор задачи обусловлен ее распространенностью, возможностью гибкой декомпозиции и уместностью обоих видов обменных взаимодействий.
3.1. Способы умножения двух матриц
Произведением
двух прямоугольных матриц
 и
и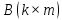 называется матрица
называется матрица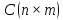 ,
,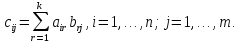
Умножение
матриц предполагает выполнение
 операций умножения и столько же операций
сложения исходных матриц. При умножении
квадратных матриц размера
операций умножения и столько же операций
сложения исходных матриц. При умножении
квадратных матриц размера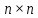 количество выполненных операций имеет
порядок
количество выполненных операций имеет
порядок 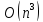 [3].
Известны последовательные алгоритмы
умножения матриц, обладающие меньшей
вычислительной сложностью. Примером
такого алгоритма может служить алгоритм
Штрассена. Этот алгоритм при выполнении
матричного умножения требует выполнения
числа операций
[3].
Известны последовательные алгоритмы
умножения матриц, обладающие меньшей
вычислительной сложностью. Примером
такого алгоритма может служить алгоритм
Штрассена. Этот алгоритм при выполнении
матричного умножения требует выполнения
числа операций
 ,
что дает заметный выигрыш на больших
плотных матрицах уже начиная с
,
что дает заметный выигрыш на больших
плотных матрицах уже начиная с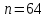 [5].
[5].
Суть алгоритма Штрассена в представлении исходных матриц в блочном виде из 4-х частей и выполнении ряда преобразований с использованием промежуточных переменных.
Были
разработаны и другие подобные алгоритмы.
Наименьшая оценка числа требуемых для
выполнения матричного умножения операций
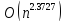 достигнута в алгоритме Копперсмита-Винограда.
Однако на практике этот алгоритм не
применяется, так как он имеет очень
большую константу пропорциональности
и начинает выигрывать в быстродействии
у других известных алгоритмов только
для матриц, размер которых превышает
память современных компьютеров [6].
достигнута в алгоритме Копперсмита-Винограда.
Однако на практике этот алгоритм не
применяется, так как он имеет очень
большую константу пропорциональности
и начинает выигрывать в быстродействии
у других известных алгоритмов только
для матриц, размер которых превышает
память современных компьютеров [6].
Широко используется блочный подход в задаче матричного умножения. Так, алгоритмы Фокса и Кэннона [1] нацелены на то, чтобы в каждый текущий момент времени, подзадачи содержали лишь часть необходимых для проведения расчетов данных, а доступ к остальной части данных обеспечивался бы при помощи передачи данных между процессорами. Серьезным недостатком обоих алгоритмов является требование: размерность блока должна быть равна квадратному корню из количества исполнителей.