

1.3. Кластер московского энергетического института
В 2007 году в МЭИ был установлен кластер с пиковой производительностью 281 GFlops. Обобщенная структурная схема кластера представлена на рис. 1.3. Все узлы кластера реализованы на базе серверов SUN Fire X4100. В его состав входят 16 вычислительных (computing node – CN) и один управляющий узел (control node – Con N), каждый из CN выполнен на двух двухядерных процессорах AMD Opteron 275, а Con N на одноядерных процессорах AMD Opteron 254 .
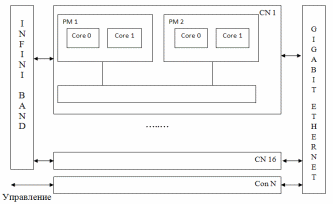 Рис.1.3
Схема архитектуры кластера МЭИ.
Рис.1.3
Схема архитектуры кластера МЭИ.
Каждый CN имеет в своем составе общую память емкостью 4ГБ (MEM 1 и MEM 2) и дисковую память HDD емкостью 2*73 ГБ. Con N имеет общую память емкостью 8ГБ и дисковую – 73ГБ. Связь между ядрами CN осуществляется с помощью локальной сети AMD Hyper Transport, связь между узлами с помощью системной сети InfiniBand, связь с «внешним миром» осуществляется с помощью вспомогательной сети Gigabit Ethernet. Операционная система OC SUSE LINUX Enterprise Server 10.
1.4. Специфика декомпозиции матричных задач для их параллельной реализации
Матрицы и матричные операции широко используются при математическом моделировании самых разнообразных процессов, явлений и систем. Матричные вычисления составляют основу многих научных и инженерных расчетов – среди областей приложений можно указать вычислительную математику, физику, экономику и др.
С учетом значимости эффективного выполнения матричных расчетов многие стандартные библиотеки программ содержат процедуры для различных матричных операций. Объем программного обеспечения для обработки матриц постоянно увеличивается – разрабатываются новые экономные структуры хранения для матриц специального типа (треугольных, ленточных, разреженных и т.п.), создаются различные высокоэффективные машинно-зависимые реализации алгоритмов, проводятся теоретические исследования для поиска более быстрых методов матричных вычислений [1].
Являясь вычислительно трудоемкими, матричные задачи представляют собой классическую область применения параллельных вычислений. Во-первых, они допускают гибкую декомпозицию на достаточно равномерные по сложности подзадачи. Во-вторых, многие из матричных задач являются слабосвязными сложными задачами, а значит время обмена данными между вычислительными узлами существенно уступает времени решения подзадач. В-третьих, многие матричные задачи являются самым вычислительно трудоемким отрезком в практических задачах, поэтому уменьшение времени решения матричной подзадачи может существенно ускорить получение результата исходной задачи.
Важным участком составления параллельной реализации любой задачи, и матричной в том числе, является ее разбиение на подзадачи по трудоемкости адекватные особенностям вычислительной системы. При неудачном способе декомпозиции могут возникнуть простои вычислительных ресурсов или неэффективно организованные обмены между вычислительными узлами [1]. При этом можно не только не получить желаемого ускорения, но и, наоборот, получить решение за большее время, чем при последовательном решении.
Для многих методов матричных вычислений характерным является повторение одних и тех же вычислительных действий для разных элементов матриц. Данное свойство свидетельствует о наличии параллелизма по данным при выполнении матричных расчетов, и, как результат, распараллеливание матричных операций сводится в большинстве случаев к разделению обрабатываемых матриц между процессорами используемой вычислительной системы. Выбор способа разделения матриц приводит к определению конкретного метода параллельных вычислений; существование разных схем распределения данных порождает целый ряд параллельных алгоритмов матричных вычислений. Наиболее общие и широко используемые способы разделения матриц состоят в разбиении данных на полосы (по вертикали или горизонтали) или на прямоугольные фрагменты (блоки) [1].
При ленточном разбиении, изображенном на рис. 1.4, каждому процессору выделяется то или иное подмножество строк или столбцов матрицы.
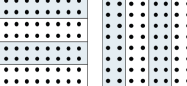
Рис. 1.4. Ленточное разбиение матриц
При таком подходе матрица A представляется в виде:
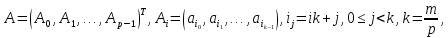
где
 есть i-я
строка матрицы A
(предполагается, что количество строк
m
кратно числу процессоров p,
т.е.
есть i-я
строка матрицы A
(предполагается, что количество строк
m
кратно числу процессоров p,
т.е.
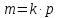 ).
).
Другой возможный подход к формированию полос состоит в применении той или иной схемы чередования строк или столбцов. Как правило, для чередования используется число процессоров p – в этом случае при горизонтальном разбиении матрица A принимает вид:
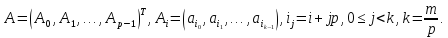
Циклическая схема формирования полос может оказаться полезной для лучшей балансировки вычислительной нагрузки процессоров.
При блочном разделении, представленном на рис. 1.5, матрица делится на прямоугольные наборы элементов.
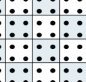
Рис 1.5. Блочное разбиение матриц
Пусть
количество процессоров составляет
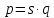 ,
количество строк матрицы является
кратнымs,
а количество столбцов – кратным q,
то есть
,
количество строк матрицы является
кратнымs,
а количество столбцов – кратным q,
то есть
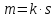 и
и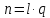 .
При этом возможное представление матрицы
выглядит так:
.
При этом возможное представление матрицы
выглядит так:
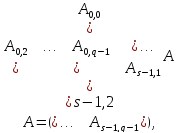
где
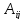 – блок матрицы, состоящий из элементов:
– блок матрицы, состоящий из элементов:

При таком подходе целесообразно, чтобы вычислительная система имела физическую или, по крайней мере, логическую топологию процессорной решетки из s строк и q столбцов. В этом случае при разделении данных на непрерывной основе процессоры, соседние в структуре решетки, обрабатывают смежные блоки исходной матрицы [1].
Перечисленные стандартные способы разбиений матриц применяются в вычислительных системах с равномерно разнесенной по узлам вычислительной мощностью. В системах с различающимися по мощности узлами следует разрабатывать собственные способы разбиений для лучшей балансировки вычислительной нагрузки.