

3.2. Разработка последовательно-параллельной модификации алгоритма умножения матриц
При разработке параллельной модификации использована идея блочной декомпозиции исходных матриц. Однако в отличие от блочного разбиения СЛАУ в рассмотренной ранее модификации, в матричном умножении размерность блока – параметр. Она определяет зернистость разбиения. Программная реализация осуществлена в модели передачи сообщений с применением MPI.
Чтобы получить один блок результирующей матрицы на одном из исполнителей, необходимо передать этому исполнителю соответствующие строку первой матрицы и столбец второй матрицы, как это показано на рис. 3.1.
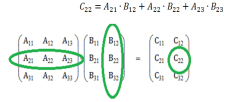
Рис. 3.1. Иллюстрация блочного способа матричного умножения
Для удобной работы при организации блочных взаимодействий сформированы квадратные блоки. Если размерность матриц не кратна размерности блока, пустые места последних строки и столбца заполняются нулями. После получения результата перемножения эти добавленные нули не принимаются во внимание.
Для экономного использования памяти и времени на передачу исходных данных в процессе решения строки матрицы A в блочном виде распределяются, по возможности, равномерно между процессорами, а матрица B отправляется всем процессорам-исполнителям. Получив свои строки и всю вторую матрицу, процесс вычисляет соответствующие строки результирующей матрицы.
Среди процессов выделяется главный (арбитр), распределяющий нагрузку между всеми процессами. В ситуациях, когда вычислительная нагрузка не может быть распределена равномерно, главный процесс берет на себя вычисления в меньшем объеме. Эта мера предпринята для выравнивания нагрузки между главным процессом, загруженным передачей входных данных подчиненным процессам и приемом от них фрагментов результата, и всеми остальными.
При выполнении программы возможна установка следующих режимов работы.
Первый режим – наличие или отсутствие проверки нулевых блоков. Как и в задаче решения СЛАУ, такая проверка способна обеспечить существенное ускорение за счет игнорирования «лишних» межблочных операций умножения.
Второй режим – задание размерности блоков. Этот режим поможет проследить влияние «зернистости» разбиений на временные показатели решения задачи в модели передачи сообщений.
Третий режим – использование или отказ от использования массовых обменных взаимодействий. Цель создания этого режима в выявлении влияния массовых обменов на временные характеристики решения задачи.
3.3. Особенности организации обменных взаимодействий
Специфика задачи матричного умножения в организации наиболее экономного с точки зрения оперативной памяти и времени обменных взаимодействий вычислительного процесса.
В представляемой реализации каждая строка результирующей матрицы вычисляется на одном процессоре. Для этого вычисления процессору необходимо переслать соответствующую строку первой матрицы и всю вторую. Графически это представлено на рис. 3.2.

Рис. 3.2. Организация обменов при последовательно-параллельном матричном умножении
Понятно, что пересылка какой-либо строки матрицы должна осуществляться с помощью обменного взаимодействия типа «точка-точка», так как информация о ней более не потребуется ни одному процессору. Рассылать вторую матрицу можно с помощью как массовых обменов, так и с помощью точечных.