

Глава 1. Высокопроизводительные вычислительные системы и их применение для решения сложных матричных задач
Современные высокопроизводительные вычислительные системы часто разделяют по способу организации оперативной памяти на системы с общей памятью (Symmetric Multiprocessing) и распределенной памятью (Massive Parallel Processing). NUMA-архитектуры (Non-Uniform Memory Access) представляют нечто среднее между SMP и MPP: в них память физически разделена, но логически общедоступна. Среди MPP машин выделяют кластерные системы из-за их дешевизны и легкой масштабируемости [4].
Главным фактором, побуждающим к развитию высокопроизводительных вычислительных систем, является наличие, так называемых, сложных задач – задач, решение которых на последовательных ЭВМ не может быть получено за удовлетворительное время. Ярким примером таких задач является задача прогноза погоды. Основным способом ее решения является моделирование климатической ситуации, сводящееся к сложной системе дифференциальных уравнений, численное решение которой на последовательной машине получают, когда прогноз становится уже не актуальным.
Особое место среди сложных задач занимают задачи, содержащие в себе данные в матричном виде и их обработку в процессе решения. При использовании вычислительной техники в решении тех или иных задач предпочтительно их представление в матричной форме. Во-первых, данные в матричном виде удобно хранить и обрабатывать. Во-вторых, при использовании высокопроизводительных ЭВМ матричное представление допускает гибкую организацию балансировки нагрузки на вычислительные узлы. В-третьих, очень широкий круг задач допускает представление данных именно в матричной форме.
1.1. Основные классы современных параллельных вычислительных систем
Классифицируя современные параллельные системы, принадлежащие классу MIMD по Флинну, чаще всего основываются на анализе используемых в них способах организации оперативной памяти. На рис. 1.1 изображена классификация современных параллельных вычислительных систем с точки зрения организации оперативной памяти [4].
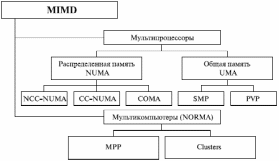
Рис. 1.1. Классификация современных параллельных вычислительных систем класса MIMD с точки зрения организации оперативной памяти
Для мультипроцессоров характерно использование (централизованной) памяти. Такой подход обеспечивает однородный доступ к памяти и служит основой для построения векторных суперкомпьютеров (PVP) и симметричных мультипроцессоров (SMP).
Общий доступ к данным может быть обеспечен и при физически распределенной памяти, при этом длительность доступа будет различаться для всех элементов памяти. Этот подход получил название неоднородный доступ к памяти (NUMA). Среди таких систем выделяют ряд подсистем, различающихся особенностями поддержания общей памяти на логическом уровне.
Мультикомпьютеры не обеспечивают общий доступ ко всей имеющейся в системе памяти. Этот подход используется при построении таких типов многопроцессорных вычислительных систем, как массивно-параллельные системы и кластеры. Последние получили широкое распространение в силу сравнительной дешевизны и легкости наращивания дополнительных мощностей [1, 4]. Традиционно в списке самых мощных высокопроизводительных вычислительных систем (TOP-500) лидируют системы именно с распределенной памятью.
Для достижения ожидаемого эффекта при использовании параллельных вычислительных систем необходимо придерживаться модели параллельного программирования, адекватной архитектуре вычислительной системы.