

Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
1 |
|
Глава 1. Особенности регрессионного анализа для стохастических объясняющих переменных
Как уже было указано во Введении, в начальных курсах эконометрики первоочередное внимание уделяется статистическим выводам в рамках классической
нормальной линейной модели наблюдений
yt = θ 1xt1+θ 2 xt2+ …+θ p xtp + ε t , t = 1, 2, …, n ,
в которой предполагается, что значения объясняющих переменных xt1, xt2, …, xtp , t = 1, 2, …, n , фиксированы, а случайные составляющие ε 1, ε 2, …, ε n (“ошибки”) являются независимыми случайными величинами, имеющими одинаковое нормальное распределение с нулевым математическим ожиданием и конечной дисперсией (такие предположения об ошибках мы называем “стандартными”). Далее анализируются последствия различного типа нарушений таких предположений об ошибках и рассматриваются методы коррекции статистических выводов о коэффициентах модели при наличии соответствующих нарушений стандартных предположений.
Предположение о фиксированности значений объясняющих переменных в совокупности со стандартными предположениями об ошибках удобно с чисто математической точки зрения: при таких предположениях оценки параметров, получаемые методом наименьших квадратов, имеют нормальное распределение, что, в свою очередь, дает возможность
•строить доверительные интервалы для коэффициентов линейной модели, используя квантили t -распределения Стьюдента;
•проверять гипотезы о значениях отдельных коэффициентов, используя квантили t -распределения Стьюдента;
•проверять гипотезы о выполнении тех или иных линейных ограничений на коэффициенты модели используя квантили F-распределения Фишера;
•строить интервальные прогнозы для “будущих” значений объясняемой переменной, соответствующих заданным будущим значениям объясняющих переменных.
Вместе с тем, используемое в классической модели предположение о фиксированности значений объясняющих переменных в n наблюдениях означает, что мы можем повторить наблюдения значений объясняемой переменной при том же наборе значений объясняющих переменных xt1, xt2, …, xtp , t = 1, 2, …, n ; при этом мы получим другую реализацию (другой набор значений) случайных составляющих ε t , t = 1, 2, …, n , что приведет к значениям объясняемой переменной, отличающимся от значений y1, y2, …, yn , наблюдавшихся ранее.
С точки зрения моделирования реальных экономических явлений, предположение о фиксированности значений объясняющих пременных можно считать реалистическим лишь в отдельных ситуациях, связанных с проведением контролируемого эксперимента. Между тем в реальных ситуациях по большей части нет возможности сохранять неизменными значения объясняющих переменных. Более того, и сами наблюдаемые значения объясняющих переменных ( как и “ошибки”) часто интерпретируются как реализации некоторых случайных величин. В таких ситуациях становится проблематичным использование техники статистических выводов, разработанной для классической нормальной линейной модели.
www.iet.ru/mipt/2/text/curs_econometrics.htm
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
2 |
|
Поясним последнее, обратившись к матрично-векторной форме записи классической линейной модели с p объясняющими переменными:
y= Xθ + ε ,
вкоторой
y = (y1, ..., yn)T - вектор значений объясняемой переменной в n наблюдениях, X – (n×p)-матрица значений объясняющих переменных в n наблюдениях, n > p,
θ= (θ 1, θ 2, …,θ p)T - вектор коэффициентов,
ε= (ε 1, ε 2, …,ε n)T - вектор случайных ошибок (возмущений) в n наблюдениях.
Если матрица X имеет полный ранг p , то матрица XTX является невырожденной, для нее существует обратная матрица (XTX) – 1 , и оценка наименьших квадратов для вектора θ неизвестных коэффициентов имеет вид
θˆ = (XTX) – 1XTy .
Математическое ожидание вектора оценок коэффициентов равно
E(θˆ ) = E ((XTX) – 1XT(Xθ + ε )) = E ((XTX) – 1XTXθ ) + E ((XTX) – 1XTε ) = θ + E (XTX) – 1XTε ).
Если матрица X фиксирована, то E ((XTX) – 1XTε ) = (XTX) – 1XT E (ε ) = 0, так что
E(θˆ ) = θ ,
т.е. θˆ – несмещенная оценка для θ .
Если же мы имеем дело со стохастическими (случайными,
недетерминированными) объясняющими переменными, то в общем случае E ((XTX) – 1XTε ) ≠ 0, так что
E(θˆ ) ≠ θ ,
и θˆ – смещенная оценка для θ , и, кроме того, эта оценка уже не имеет нормального распределения.
Если объясняющие переменные стохастические, то в некоторых случаях все же
остается возможным использовать стандартную технику статистических выводов,
предназначенную для классической нормальной линейной модели, по крайней мере,
васимптотическом плане (при большом количестве наблюдений).
Вэтом отношении наиболее благоприятной является Ситуация A
•случайная величина ε s не зависит (статистически) от xt1, xt2, …, xtp при всех t
и s ,
•ε 1, ε 2, …, ε n являются независимыми случайными величинами, имеющими одинаковое нормальное распределение с нулевым математическим ожиданием и
конечной дисперсией σ2 > 0. (Далее мы кратко будем обозначать это как ε t ~ i.i.d. N (0, σ2). Здесь i.i.d. – independent, identically distributed.)
При выполнении таких условий имеем
E ((XTX) – 1XTε ) = E ((XTX) – 1XT) ·E(ε ) = 0,
www.iet.ru/mipt/2/text/curs_econometrics.htm

Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
3 |
|
|
||
так что оценка наименьших квадратов для θ |
является несмещенной. |
|
Распределение статистик критериев (“тестовых статистик”) можно найти с помощью двухшаговой процедуры. На первом шаге находим условное распределение при фиксированном значении X ; при этом значения объясняющих переменных рассматриваются как детерминированные (как в классической модели). На втором шаге мы получаем безусловное распределение соответствующей статистики, умножая условное распределение на плотность X и интегрируя по всем возможным значениям
X .
Если применить такую процедуру для получения безусловного распределения
оценки наименьших квадратов θˆ , то на первом шаге находим:
θˆ | X ~ N(θ,σ 2 (X T X )−1).
Интегрирование на втором этапе приводит к распределению, являющемуся смесью
нормальных распределений N (θ , σ 2 (X T X )−1)по X . Это распределение, в отличие от классического случая, не является нормальным.
В то же время, для оценки j-го коэффициента имеем:
θˆj | X ~ N(θ j ,σ 2 (XT X )−j1j ),
где |
(X T X )−jj1 – j-й диагональный элемент матрицы (X T X )−1, |
||
так что |
|
|
|
θˆj |
−θ j |
|
X ~ N (0, 1) . |
|
|||
σ (XT X)−j1j |
|
||
|
|
||
Условным распределением отношения S2/σ2 , где S2 = RSS/(n – p), RSS – остаточная сумма квадратов, является распределение хи-квадрат с (n – p) степенями свободы,
S2/σ2 | X ~ χ2(n – p) .
Заметим теперь, что t-статистика для проверки гипотезы H0: θ j = θ *j определяется соотношением
|
θˆj −θ*j |
(θˆj −θ*j )σ (XT X)−j1j |
|
|
|
|
||
t = |
|
= |
|
|
. |
|
|
|
S (XT X)−j1j |
S2 σ 2 |
|
|
|
|
|||
Из предыдущего вытекает, |
что если гипотеза H0 |
верна, |
то |
условное |
||||
распределение этой |
t-статистики |
имеет t-распределение |
Стьюдента |
с |
(n – p) |
|||
степенями свободы, t | X ~ t(n – p) .
Это условное распределение одно и то же для всех X . Поэтому вне зависимости от того, какое именно распределение имеет X , безусловным распределением t-
статистики для H0: θ j = θ *j |
при выполнении этой гипотезы будет все то же |
распределение t(n – p) . |
|
www.iet.ru/mipt/2/text/curs_econometrics.htm

Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
4 |
|
Аналогичное рассмотрение показывает возможность использования стандартных F-критериев для проверки линейных гипотез о значениях коэффициентов.
Те же самые выводы остаются в силе при замене предположений ситуации A следующим предположением.
Ситуация A΄
•ε | X ~ N(0, σ2In) , где In – единичная матрица (размера n × n) .
Для краткости мы будем далее обозначать
xt = (xt1, xt2, …, xtp)T – вектор значений p объясняющих переменных в t-м наблюдении.
|
Ситуация B |
• |
случайная величина ε s не зависит (статистически) от xt1, xt2, …, xtp при всех t и |
|
s ; |
• |
распределение случайной величины ε t не является нормальным, но |
|
ε t ~ i.i.d., E(ε t) = 0, D(ε t) = σ2 > 0 и E(ε t4) = µ4 < ∞ ; |
•E(xt xtT) = Qt – положительно определенная матрица, (1/n)( Q1 + … + Qn) → Q
при n → ∞ , где Q – положительно определенная матрица;
• |
E(xit xjt xkt xst) < ∞ для всех i, j, k, s ; |
• |
(1/n)( x1 x1T + … + xn xnT) → Q по вероятности . |
В силу первого предположения, оценка наименьших квадратов вектора коэффициентов θ остается несмещенной, как и в ситуации A. Однако при конечном количестве наблюдений n из-за негауссовости (ненормальности) распределения ε t распределения статистики S2, а также t- и F-статистик, будут отличаться от стандартных, получаемых в предположении гауссовости. Чтобы продолжать пользоваться обычной техникой регрессионного анализа, мы должны здесь сослаться на следующие асимптотические результаты, строгий вывод которых можно найти,
например, в книге [Hamilton (1994)].
Пусть θˆ (n) – оценка наименьших квадратов вектора θ по n наблюдениям, Xn – матрица значений объясняющих переменных для n наблюдений, а Sn2 , tn , Fn -
статистики S2 , t , F , вычисляемые по n наблюдениям. Если выполнены предположения, перечисленные при описании ситуации B, то при n → ∞

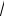 n (θˆ (n) – θ ) → N (0 , σ2 Q – 1),
n (θˆ (n) – θ ) → N (0 , σ2 Q – 1),

 n ( Sn2 – σ2 ) → N (0, µ4 – σ4), tn → N (0 , 1),
n ( Sn2 – σ2 ) → N (0, µ4 – σ4), tn → N (0 , 1),
qFn → χ2(q) , где q – количество линейных ограничений на компоненты вектора θ .
Здесь везде имеются в виду сходимости по распределению, т.е. распределения случайных величин, стоящих слева от стрелки, неограниченно сближаются при n → ∞ с распределениями, стоящими справа от стрелки. При этом имеют место приближенные соотношения
θˆ (n) ≈ N (θ , σ2 Q – 1 ⁄ n), или θˆ (n) ≈ N (θ , σ2 (XnT Xn) – 1) ,
(последнее аналогично точному соотношению в гауссовской модели),
www.iet.ru/mipt/2/text/curs_econometrics.htm
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
5 |
|
Sn2 ≈ N (σ2 , (µ4 – σ4) ⁄ n),
tn ≈ N (0, 1), qFn ≈ χ2(q).
Если в ситуации B при имеющемся количестве наблюдений n использовать не асимптотические распределения, а распределение Стьюдента t(n – p) для t-статистики (вместо N (0 , 1)) и распределение Фишера F(q, n – p) для F-статистики (вместо χ2(q) для qFn), то это приводит к более широким доверительным интервалам (по сравнению с интервалами, построенными по асимптотическим распределениям). Многие исследователи предпочитают поступать именно таким образом, учитывая это обстоятельство и то, что при конечных n распределения Стьюдента и Фишера могут давать лучшую аппроксимацию истинных распределений статистик tn и Fn .
Ситуация C
В рассмотренных выше ситуациях, как и в классической модели, предполагалось, что ε t | X ~ i.i.d. Теперь мы откажемся от этого предположения и предположим, что
•условное распределение случайного вектора ε относительно матрицы X является n-мерным нормальным распределением N (0 , σ2 V) ;
•V – известная положительно определенная матрица размера n×n.
Поскольку V – ковариационная матрица, она к тому же и симметрична; таковой же будет и обратная к ней матрица V –1 . Но тогда существует такая невырожденная (n×n)-матрица P , что V –1 = PTP . Используя матрицу P , преобразуем вектор ε к вектору
ε* = P ε .
При этом E (ε*) = 0 и условная (относительно X) ковариационная матрица вектора ε*
Cov (ε*| X ) = E (ε*ε*T | X ) = E (P ε (P ε)T | X ) = P E (ε εT | X ) PT = P σ2 V PT .
Но V = (V – 1) – 1 = (PTP) – 1 , так что
Cov (ε*| X ) = P σ2 V PT = σ2 P(PTP) – 1PT = σ2 In .
Преобразуя с помощью матрицы P обе части основного уравнения
y= Xθ + ε ,
получаем:
Py = PXθ + Pε ,
или
y* = X*θ + ε* ,
где
y* = Py , X* = PX , ε* = P ε .
В преобразованном уравнении
ε* | X ~ N (0 , σ2 In) ,
так что преобразованная модель удовлетворяет условиям, характеризующим ситуацию A΄. Это означает, что все результаты, полученные в ситуации A, применимы
кмодели y* = X*θ + ε* .
Вчастности, оценка наименьших квадратов
θ * = (X*TX*) – 1 X*T y* = (XTPTPX) – 1 XTPTPy = (XT V – 1X) – 1 XT V – 1y
www.iet.ru/mipt/2/text/curs_econometrics.htm
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
6 |
|
является несмещенной, т.е. E(θ*) = θ , ее условное распределение (относительно X) нормально и имеет ковариационную матрицу
Cov (θ * | X ) = σ2(X*TX*) – 1 = σ2(XT V – 1X) – 1.
Эта оценка известна как обобщенная оценка наименьших квадратов (GLS – generalized least squares).
В рамках модели y* = X*θ + ε* можно использовать обычные статистические процедуры, основанные на t- и F-статистиках.
Если ковариационная матрица V не известна априори, то обычно ограничиваются моделями, в которых она параметризована, так что V = V(β) , где β – векторный параметр, который приходится оценивать по имеющимся наблюдениям. При этом достаточно часто можно использовать стандартные выводы в асимптотическом плане,
заменяя |
в выражении для GLS оценки θ * |
= (XT V – 1X) – 1 XT V – 1y |
неизвестную |
||
матрицу |
V = V(β0) (V(β0) – истинная ковариационная матрица вектора |
ε ) матрицей |
|||
ˆ |
где |
ˆ |
– любая состоятельная |
оценка для β0 . Более |
того, такую |
V( β n ), |
β n |
||||
состоятельную оценку часто можно получить простым анализом остатков при оценивании обычной процедурой наименьших квадратов.
Рассмотренные ситуации не охватывают, однако, наиболее интересных для нас моделей стационарных и нестационарных временных рядов. Мы перейдем теперь к обсуждению основных понятий и фактов, касающихся стационарных и нестационарных временных рядов, и рассмотрению процедур регрессионного анализа временных рядов.
www.iet.ru/mipt/2/text/curs_econometrics.htm