

Глава 9. Стратегия вывода с использованием байесовского подхода
9.1. Обработка свидетельств в условий неуверенности и нечеткости
В области экономики типичными являются ситуации, когда решения приходится принимать на основе неточных данных. Элементы данных, с которыми имеют дело эксперты в процессе принятия решений, могут быть неполными, неточными, неотчетливыми, взаимно несовместимыми и изменяющимися во времени.
Предположим,
что для любого объекта![]() некоторого
множества X
и
любого
свойства из некоторого множества Y
можно
оценить количественное или
качественное свойства значения
некоторого
множества X
и
любого
свойства из некоторого множества Y
можно
оценить количественное или
качественное свойства значения![]() Благодаря
этому возникает
возможность
определить объект, точнее подмножество
объектов через оператор
(квантор)
Благодаря
этому возникает
возможность
определить объект, точнее подмножество
объектов через оператор
(квантор)
![]() ,
т.е. тот объект
,
т.е. тот объект![]() для
которого выполняется свойство
Y(x).
Фактически
процесс оценки значения свойства можно
рассматривать
как отображение (морфизм) (рис. 9.1).
для
которого выполняется свойство
Y(x).
Фактически
процесс оценки значения свойства можно
рассматривать
как отображение (морфизм) (рис. 9.1).

Рис. 9.1. Оценка значений свойств объекта
В
общем случае высказывание р(х)
об
индивидах (объектах) определяет некоторое
множество х:р(х),
а
именно множество всех индивидов, для
которых это высказывание истинно.
Истинное значение предложения зависит
от уровня
знания в то время, когда оно рассматривается.
Таким образом, для каждого
уровня знания q
может
быть определена совокупность pq(x):
известно,
что на уровне знания q
верно
р(х).
Эту
совокупность pq
будем
называть
объемом
р
на
уровне q.
Таким
образом, для данной шкалы уровней знания
сопоставление
уровню q
множества
pq
определяет
отображение q
![]() set,
где
set—
некоторое множество, более того, если
истинность сохраняется во времени,
то из того, что х0
pq
и
q
r
вытекает,
что хо
рг.
Поэтому
если q
r,тo
pq
pr.
set,
где
set—
некоторое множество, более того, если
истинность сохраняется во времени,
то из того, что х0
pq
и
q
r
вытекает,
что хо
рг.
Поэтому
если q
r,тo
pq
pr.
Неопределенность и неточность данных могут рассматриваться как две противоположные точки зрения на одну и ту же реальность — неполноту информации. В этих условиях мы определим информационную единицу четверкой (объект, свойство, значение, уверенность). Неточность относится к содержанию информации, а неопределенность — к ее истинности, понимаемой в смысле соответствия действительности («уверенности»). Степень неопределенности информации отражают с помощью квалификаторов (модальностей) типа «вероятно», «возможно», «необходимо», «правдоподобно» и др. Правдоподобность и доверие имеют чисто эпистемологическую интерпретацию и связаны с возможностью и необходимостью. Каждое из этих понятий соответствует некоторому способу вывода из заданной суммы знаний: заслуживает доверия все, что непосредственно дедуктивно выводится из базы знаний, а правдоподобно все, что не противоречит ей.
Будем называть информационное данное точным, если подмножество его значений является синглетоном. Мы будем называть предложение неопределенным, если его справедливость или ложность не может быть определенно установлена. Предложение, содержание которого суть высказывание о значении некоторой переменной, является неточным, если это значение недостаточно точно определено по отношению к данной шкале. Для заданного множества сведений противоречие между неточностью и неопределенностью выражается в том, что с повышением точности содержания возрастает его неопределенность, и наоборот, неопределенный характер точной информации приводит в общем случае к некоторой неточности окончательных заключений, выводимых из этой информации.
Одним из существенных достоинств ИИС является создание методов, позволяющих быть точными в отношении неточных данных. Нечеткая логика создана Л. Заде, который распространил булеву логику на действительные числа. В нечеткой логике используются все значения между 0 и 1, чтобы указать частичную истину. Так, запись: Р(конкурентноспособный (х)) = 0,75 говорит о том, что предложение «х— конкурентноспособный» в некотором смысле на три четверти истинно. Точно так же оно на одну четверть ложно.
В основе нечеткой логики лежит определение нечеткого множества, т.е. «класса» с континуумом степеней принадлежности. Пусть X— пространство точек (объектов) с порождающим элементом х, обозначаемым х. Таким образом, X = {х}. Нечеткое множество (класс) А в X характеризуется функцией принадлежности, которая связывает с каждой точкой в X реальное число в интервале [0,1] со значением А(х) в точке х, представляющее степень принадлежности х к А. Когда А есть множество в обычном смысле слова, его функция принадлежности может принимать только два значения 0 и 1, причем (х) = 1 или 0 согласно тому, принадлежит ли х А или нет. Таким образом, в этом случае (x) сводится к характеристической функции множества.
Необходимо отметить, что хотя функция принадлежности нечеткого множества имеет некоторое сходство с функцией плотности вероятности, между ними имеются существенные различия. Множество, состоящее из точек х, для которых имеет ненулевое значение, называется базой А.
Среди обычных множеств, описывающих нечеткое множество А часто используются следующиедва множества:

![]() —
база (носитель)
нечеткого множества. Нечеткое
множество является нормальным,
если
его функция принадлежности
достигает значения 1 по крайней мере в
одной точке области. Оно называется
регулярным,
если
и только если функция принадлежности
имеет только
один пик, т.е. для
—
база (носитель)
нечеткого множества. Нечеткое
множество является нормальным,
если
его функция принадлежности
достигает значения 1 по крайней мере в
одной точке области. Оно называется
регулярным,
если
и только если функция принадлежности
имеет только
один пик, т.е. для
![]()
Над нечеткими множествами возможно выполнение теоретико-множественных операций. Объединение нечетких множеств определяемы следующим образом:

Множеством α-уровня или α-срезом нечеткого множества А называется множество
![]()
где I — интервал [0,1]. Любое нечеткое множество может быть представлено объединением своих а-уровневых множеств по всем αL. Иными словами:
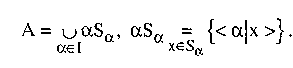
Степенью включения множества А в В называется величина

где операция импликации —> определяется согласно логике Лукасевича:
![]()
или согласно Заде:
![]()
Степень равенства нечетких множеств

Степенью ε множества А называется нечеткое множество
![]()
При ε = 2 получаем операцию концентрации, подчеркивания центральных элементов. Это осуществляется уменьшением периферийных значений
![]()
При ε = 0,5 получается операция размывания, растяжения центрального элемента:
![]()
Декартовым, произведением нечетких множеств Ai, i = l,n называется множество

Нечеткие
отношения. Определим
в общем случае n-арное
нечеткое отношение
как нечеткое подмножество в произведении
пространств Х![]() ...Х
.
...Х
.
Нечетким
отношением R
на множестве X
называется
нечеткое подмножество
декартова произведения Х![]() ...Х
,
характеризующееся функцией принадлежности
в случае бинарного отношения
...Х
,
характеризующееся функцией принадлежности
в случае бинарного отношения![]() Значение
Значение
![]() этой
функции понимается как субъективная
мера или степень выполнения
отношения xRy.
этой
функции понимается как субъективная
мера или степень выполнения
отношения xRy.
Если множество X, на котором задано нечеткое отношение R, конечно, то
функция принадлежности R этого отношения представляет собой квадратную матрицу. Если элемент rij этой матрицы равен α, то это означает, что степень выполнения отношения xirxj равна α.
Операции над нечеткими отношениями.
Пусть
на множестве X
заданы
два нечетких отношения А
и
В,
т.е.
в декартовом
произведении X
![]() X
заданы
два нечетких подмножества А
и
В.
Нечеткие
множества
X
заданы
два нечетких подмножества А
и
В.
Нечеткие
множества
![]() называются
соответственно
объединением
и
пересечением
нечетких
отношений А
и
В
на
множестве X
с
функциями принадлежности:
называются
соответственно
объединением
и
пересечением
нечетких
отношений А
и
В
на
множестве X
с
функциями принадлежности:

Говорят,
что нечеткое отношение В
включает в
себя нечеткое отношение
А,
если
для нечетких множеств А
и В выполнено
условие A![]() В.
Для функций
принадлежности
этих
множеств
неравенство
В.
Для функций
принадлежности
этих
множеств
неравенство
![]() выполняется при любых
выполняется при любых
![]()
Если R — нечеткое отношение на множестве X, то нечеткое отношение R, характеризующееся функцией принадлежности
![]()
называется дополнением в X отношения R.
Обратное к R нечеткое отношение R -1 на множестве X определяется следующим образом:
![]()
Максиминное
произведение А
![]() В нечетких отношенийА
и
В
на
множестве
Охарактеризуется
функцией принадлежности вида
В нечетких отношенийА
и
В
на
множестве
Охарактеризуется
функцией принадлежности вида
![]()
Минимаксное произведение нечетких отношений А и В на Х определяется функцией принадлежности вида
![]()
Максмультишгакативное произведение нечетких отношений А и В определяется функцией принадлежности вида
![]()
Пример расчета различного вида произведений нечетких отношений

Проекции
нечетких отношений. Пусть
R—
нечеткое отношение на множестве
X
с функцией принадлежности
![]() R(x,y).
Для произвольного
у
X
нечеткое множество R(y)
представляет собой нечеткое множество
элементов
х множества X,
связанных с выбранным у отношением R.
Функция
принадлежности
этого множества имеет вид
R(x,y).
Для произвольного
у
X
нечеткое множество R(y)
представляет собой нечеткое множество
элементов
х множества X,
связанных с выбранным у отношением R.
Функция
принадлежности
этого множества имеет вид![]() ,
где у — фиксированный
элемент множества X.
,
где у — фиксированный
элемент множества X.
Например, для нечеткого отношения R=(«близко к») заданного на числовой оси, множество R(y) можно понимать как нечеткое множество чисел, близких к выбранному числу у.
Объединение нечетких множеств R(y) по всем уХ называется первой проекцией R(1) нечеткого отношения R.
Согласно определению первой проекции R(1) функция принадлежности и R1 имеет вид:

Вторая проекция R(2) нечеткого отношения R определяется аналогичным образом:
![]()
Если
R
= R(l)![]() R(2)
— декартово произведение первой и
второй проекций нечеткого
отношения R,
то R
R
. Этот факт следует из определения
функции
принадлежности декартова произведения
нечетких множеств
R(2)
— декартово произведение первой и
второй проекций нечеткого
отношения R,
то R
R
. Этот факт следует из определения
функции
принадлежности декартова произведения
нечетких множеств

Пример.
Пусть матрица нечеткого отношения
R
на
множестве
![]() ,
имеет вид:
,
имеет вид:

Тогда функции принадлежности первой и второй проекций этого отношения таковы:

Свойства нечетких отношений.
1. Рефлексивность.
Нечеткое отношение R на множестве X называется рефлексивным, если для любого х Х выполнено равенство
![]()
В случае конечного множества X главная диагональ матрицы рефлексивного нечеткого отношения R состоит целиком из единиц. Примером рефлексивного нечеткого отношения может служить отношение «примерно равны» в множестве чисел.
2. Антирефлексивность.
Функция
принадлежности антирефлексивного
нечеткого отношения обладает
свойством![]() при
любом хХ.
Антирефлексивно,
например, отношение «много больше» в
множестве чисел. Дополнение рефлексивного
отношения
антирефлексивно.
при
любом хХ.
Антирефлексивно,
например, отношение «много больше» в
множестве чисел. Дополнение рефлексивного
отношения
антирефлексивно.
3. Симметричность. Нечеткое отношение R на множестве X называется симметричным, если для любых х, у X выполнено равенство
![]()
Матрица симметричного нечеткого отношения, заданного в конечном множестве, симметричная. Пример симметричного нечеткого отношения — отношение «сильно различаться по величине».
4. Антисимметричность. Функция принадлежности антисимметричного нечеткого отношения обладает следующим свойством:
![]()
Это свойство можно описать следующими двумя эквивалентными способами:

Антисимметричным, например, является нечеткое отношение «много больше».
5. Транзитивность.
Нечеткое
отношение R
на
множестве X
называется
транзитивным,
если R![]() RR.
RR.
Всюду ниже под транзитивностью нечеткого отношения мы будем понимать максиминную транзитивность, т.е. считать, что при любых х,уХ функция принадлежности транзитивного нечеткого отношения R на множестве X удовлетворяет неравенству

6. Транзитивное замыкание R нечеткого отношения

Отображение нечетких множеств.
1. Образ нечеткого множества при обычном (четко описанном отображении).
Пусть φ: X→Y— заданное отображение и пусть А— нечеткое подмножество множества X с функцией принадлежности А(х).
Образ А при отображении φ определяется как нечеткое подмножество множества Y, представляющее собой совокупность пар вида
![]()
где B : Y →[0,1] — функция принадлежности образа. Функцию принадлежности lB(y)можно записать

где множество φ-1(у)для любого фиксированного yY имеет вид
![]() т.е.
представляет собой множество всех
элементов х Х,
образом каждого из которых при отображении
φ
является
элемент y.
т.е.
представляет собой множество всех
элементов х Х,
образом каждого из которых при отображении
φ
является
элемент y.
Нечеткое отображение можно описать как отображение, при котором элементу хХ ставится в соответствие не конкретный элемент множества Y, а нечеткое подмножество множества Y.
Описывается
нечеткое отображение функцией вида![]() гак,
гак,
что функция (хо,у)(при фиксированном х = х0 есть функция принадлежности нечеткого множества в Y, представляющего собой нечеткий образ элемента х0 при данном отображении.
Итак,
пусть![]() —
заданное нечеткое отображение, и пусть
—
заданное нечеткое отображение, и пусть
А(х)
— заданное нечеткое множество в X.
Если применить принцип обобщения
в форме
![]() для
нахождения образа этого
нечеткого
множества при отображении φ,
то получим совокупность пар вида
для
нахождения образа этого
нечеткого
множества при отображении φ,
то получим совокупность пар вида![]() при
каждом фиксированном хХ
(т.е. в
каждой такой паре) представляет собой
нечеткое подмножество множества Y.
Образ нечеткого множества А
представляет
собой нечеткий подкласс класса
всех нечетких подмножеств множества
Y.
при
каждом фиксированном хХ
(т.е. в
каждой такой паре) представляет собой
нечеткое подмножество множества Y.
Образ нечеткого множества А
представляет
собой нечеткий подкласс класса
всех нечетких подмножеств множества
Y.
Определив размытые отношения, перейдем к определению понятия нечеткой реляционной базы данных.
Нечеткая
реляционная база данных —
это множество отношений, составленных
из кортежей (строк), содержащих n
элементов. Пусть tj
— j-я
строка,
она принимает вид![]() —
значение домена, выбранное
из домена Dj.
В любой обычной реляционной базе
данных
—
значение домена, выбранное
из домена Dj.
В любой обычной реляционной базе
данных![]() Для
размытой
реляционной базы данных dij
не обязательно является синглетоном,
т.е.
Для
размытой
реляционной базы данных dij
не обязательно является синглетоном,
т.е.![]() Вторая
особенность нечеткой реляционной базы
данных
состоит
в том, что для каждого домена Dj
определяется отношение сходства Sj,
определенное на декартовом произведении
Вторая
особенность нечеткой реляционной базы
данных
состоит
в том, что для каждого домена Dj
определяется отношение сходства Sj,
определенное на декартовом произведении
![]()
Отношение сходства есть обобщение отношения эквивалентности такое, что если a,b,c D., то имеют место свойства

Интерпретация
![]() кортежа
кортежа
![]() есть
любое
приписывание
значения такое, что aj,
dij
для всех j.
Для множества i
кортежа tj
существует q
возможных интерпретаций, где αi
равно
мощности декартова
произведения значений доменов
есть
любое
приписывание
значения такое, что aj,
dij
для всех j.
Для множества i
кортежа tj
существует q
возможных интерпретаций, где αi
равно
мощности декартова
произведения значений доменов![]() Ответ
на запрос
есть отношение, образованное из области,
релевантной запросу. В обычной
базе данных каждый кортеж в отношении
ответа полностью совместим
с критерием выдачи, определенным в
запросе. В нечеткой базе данных
каждый кортеж получает некоторое
значение функции принадлежности.
Обычно коэффициент степени принадлежности
является мерой соответствия
(пригодности) кортежа как реакции на
данный размытый запрос.
Ответ
на запрос
есть отношение, образованное из области,
релевантной запросу. В обычной
базе данных каждый кортеж в отношении
ответа полностью совместим
с критерием выдачи, определенным в
запросе. В нечеткой базе данных
каждый кортеж получает некоторое
значение функции принадлежности.
Обычно коэффициент степени принадлежности
является мерой соответствия
(пригодности) кортежа как реакции на
данный размытый запрос.
Ответ на размытый запрос будет иметь меру принадлежности, заключенной между нулем и единицей. Способность специфического запроса различать кортежи в отношении реакции пропорционально степени, с которой запрос экстремизирует значения функции принадлежности кортежа множеству релевантных записей. В данном случае термин «экстремизирует» имеет смысл приближения к концам интервала значений декартова произведения значений доменов области
![]()
лингвистическими формами, выражающими соответствие кортежа запросу, являются такие формы, как «нет», «очень», «более или менее», «не очень» соответственно им используются лингвистические модификаторы, выражаемые, в частности, с помощью функций CON — концентрации и DIL — размывания.
Пусть![]() —
произвольный элемент. Значение функции
принадлежности
—
произвольный элемент. Значение функции
принадлежности![]() ,
где определяется
,
где определяется
![]() как.
как.![]() Запрос
Q(.)
индуцирует значения
функции принадлежности Q(t)для
строки t
в
выдаче r
следующим
образом:
каждая интерпретация
Запрос
Q(.)
индуцирует значения
функции принадлежности Q(t)для
строки t
в
выдаче r
следующим
образом:
каждая интерпретация
![]() определяет
значение а(а`j)для
каждого элемента домена
определяет
значение а(а`j)для
каждого элемента домена![]() .
Оценка модификаторов и операторов в Q
на
основе
значений функции принадлежности a
(аj)
дает q(I)
,
значение функции принадлежности
по отношению к запросу. Наконец,
.
Оценка модификаторов и операторов в Q
на
основе
значений функции принадлежности a
(аj)
дает q(I)
,
значение функции принадлежности
по отношению к запросу. Наконец,
![]()
Нечеткая
переменная определяется
кортежем
![]() —
—
наименование
нечеткой переменной, X
= х — область определения нечеткой
переменной (базовое множество),![]() —
нечеткое подмножество
множества X,
описывающее
ограничения на возможные значения
нечеткой
переменной α
.
—
нечеткое подмножество
множества X,
описывающее
ограничения на возможные значения
нечеткой
переменной α
.
Лингвистическая переменная характеризуется набором
![]() ,
в котором β — название лингвистической
переменной, Т(β)—
термин-множество лингвистической
переменной β, т.е. множество лингвистических
(вербальных) значений переменной, причем
каждое из этих значений
является нечеткой переменной с областью
определения X:
G
—
,
в котором β — название лингвистической
переменной, Т(β)—
термин-множество лингвистической
переменной β, т.е. множество лингвистических
(вербальных) значений переменной, причем
каждое из этих значений
является нечеткой переменной с областью
определения X:
G
—
синтаксическое правило (имеющее обычно форму грамматики), порождающее наименования αТ(β) вербальных значений лингвистической переменной β, М — семантическое правило, которое ставит в соответствие каждой нечеткой переменной α Т(β) нечеткое множество С(α) —смысл нечеткой переменной а.
Заметим,
что Т— множество значений лингвистической
переменной (терм-множество),
представляет собою наименования нечетких
переменных, областью определения которых
является множество X.
G
— синтаксическая процедура
(грамматика), позволяющая оперировать
элементами терм-множества
Т, в частности генерировать новые
осмысленные термы. Множество
![]() называется
лингвистической переменной, образуемой
процедурой
G.
G
позволяет
осуществить отображение лингвистической
переменной
в нечеткую переменную, т.е. приписать
нечеткую семантику путем формирования
соответствующего нечеткого множества.
называется
лингвистической переменной, образуемой
процедурой
G.
G
позволяет
осуществить отображение лингвистической
переменной
в нечеткую переменную, т.е. приписать
нечеткую семантику путем формирования
соответствующего нечеткого множества.
Синтаксис
G
задается
в виде бесконтекстной грамматики
![]() где
VN
— множество нетерминальных символов,
VT
—множество
терминальных символов, W
— начальный символ, П — множество
продукций. Множество терминальных
символов включает множество базовых
значений Т, логические операции и
модификаторов И, ИЛИ, ОЧЕНЬ, НЕ, СЛЕГКА
и др. Семантическую процедуру можно
задать правилами
где
VN
— множество нетерминальных символов,
VT
—множество
терминальных символов, W
— начальный символ, П — множество
продукций. Множество терминальных
символов включает множество базовых
значений Т, логические операции и
модификаторов И, ИЛИ, ОЧЕНЬ, НЕ, СЛЕГКА
и др. Семантическую процедуру можно
задать правилами

где C1 и С2 нечеткие множества, соответствующие значениям а1 и а2 рассматриваемой лингвистической переменной.
Лингвистические переменные, у которых процедура образования новых значений G зависит от множества базовых значений Т, назовем синтаксически зависимыми лингвистическими переменными.
Нечеткими высказываниями назовем высказывания следующего вида:
высказывание <β есть α>, где β— наименование лингвистической переменной, отражающей некоторый объект или параметр реальной действительности, относительно которой производится утверждение α, являющееся ее нечеткой оценкой (нечеткой переменной), например: «Величина задолженности равна 14 млн.руб.», здесь α =14 является оценкой лингвистической переменной β <задолженность>:
< β есть α >;
< β есть mα>, где m — модификатор «очень», «более или менее», «не значительный»;
< β есть Qα >;
< Qβ есть mα >;
<mβ есть Qα >, где Q — квантификатор («большинство», «несколько», «много», «немного»);
высказывания, образуются из вышеперечисленных с использованием союзов И, ИЛИ, ЕСЛИ ... ТО, ИНАЧЕ.
Пусть![]() —
множество признаков, значениями которых
описывается
состояние объекта управления. Каждый
признак
—
множество признаков, значениями которых
описывается
состояние объекта управления. Каждый
признак
![]() описывается
соответствующей лингвистической
переменной
уi(набор
лингвистических значений признака, mi
—
число значений признака),
D
— базовое множество признака уi
Для описания термов
описывается
соответствующей лингвистической
переменной
уi(набор
лингвистических значений признака, mi
—
число значений признака),
D
— базовое множество признака уi
Для описания термов
![]() соответствующих
значениям признака yi,
используются
нечеткие переменные
соответствующих
значениям признака yi,
используются
нечеткие переменные![]() ,
т.е. значение Тij
описывается нечетким множеством
CJi
в базовом множестве Di:
,
т.е. значение Тij
описывается нечетким множеством
CJi
в базовом множестве Di:
![]()
Нечеткой ситуацией S называется нечеткое множество второго уровня

Пример 9.1. Нечеткая ситуация.
{<<0,1 / «большая»>, <0,8 / «средняя»>, <0,4 / «малая»> / «рентабельность производства»>, <0,6/ «большая»>, <0,8/ «небольшая»>, <1,0/ «средняя»»/ «величина прибыли)>}.
Рассмотрим пример применения правил нечеткой логики к выбору ценных бумаг.
Предположим, что имеются ценные бумаги, возможность приобретения которых представлена в виде следующих данных в таблице 9.1:
Таблица9.1

Заметьте, что сумма возможностей не равна 1. Когда неопределенность представляется возможностью, может быть применена размытая логика. Возможность того, что ценная бумага даст высокий доход, обозначается s(high(x)) функция 5(х) является в данном случае функцией принадлежности, причем 0 < s(x) < 1.
Подход с позиций размытой логики может быть применен в ИИС для представления правил вывода в условиях нечеткости. Предположим, что существует два правила с нечеткими условиями.
Пример 9.2.
Правило 1.
IF <x> хорошо экспортируется(0,6)
AND <x> принадлежит к электронной отрасли (1,0)
THEN <х> обеспечивает высокий доход.
Правило 2.
IF<x> принадлежит большому объединению (0,5)
AND <x> имеет высокую активность в проведении научных исследований (0,25).
THEN <x> обеспечивает высокий доход, где переменная <х> заменяет название фирмы.
Любые ценные бумаги, которые удовлетворяют правилам 1 и 2 могут быть отнесены к системам с высоким доходом с данной степенью уверенности, следовательно интеграция двух условий должна производиться связкой ИЛИ (OR).
Так как каждое правило содержит конъюнкцию свидетельств, то общая оценка возможности события, определяемого правилом, определяется следующим образом:
Правило 1: Min(l,0; 0,6)=0,6
Правило 2: Min(0,5; 0,25)=0,25
Далее два правила интегрируются посредством связки OR
Правило 1 или 2
Мах(0,6; 0,25)=0,6.
Согласно правилам нечеткого множества, мы можем заключить, что ценная бумага <х>, которая удовлетворяет либо правилу 1, либо правилу 2 обеспечивает значение возможности получения высокого дохода, равное 0,6.
При использовании правил нечеткой логики нужно следить за тем, чтобы не было потеряно много информации в процессе интеграции свидетельств. В примере 9.2 информация
<x> хорошо экспортируется (0,6)
<x> принадлежит большому объединению (0,5)
вовсе не использовалась. Чтобы компенсировать это дефект, может быть использована следующая формула редактирования, предложенная Шортли-фом:
![]()
Шортлиф первым назвал величину, определяемую формулой (9.1), мерой уверенности. Но так как его определение меры уверенности перекликается с определением величины MB, которое приводится в последующих разделах, более правильно определить формулу (9.1) как компенсаторное правило размытой логики. В соответствии с этим правилом, получим:

До сих пор мы предполагали, что правила сами по себе не являются неопределенными, они являются твердо установленными фактами. Если имеются сомнения относительно самих правил вывода, чтобы ослабить возможность заключения благодаря такой неопределенности, введем меру доверия правилу CR . В этом случае:
