

Глава 3. Методы организации данных
3.1 Методы организации данных в памяти эвм
Под организацией значений данных понимают относительно устойчивый порядок расположения записей данных в памяти ЭВМ и способ обеспечения взаимосвязи между данными.
Организация данных может быть линейной и нелинейной.
Среди линейных методов выделяются последовательная и цепная организации данных.
К нелинейным относятся древовидная, в том числе бинарное дерево.
Наиболее важными и часто применяемыми алгоритмами обработки данных являются формирование данных, поиск и корректировка. Поэтому для анализа эффективности каждого метода организации данных будем анализировать следующие критерии:
а) время формирования данных, или упорядочение данных по ключевому атрибуту;
б) время поиска данных (поиск по совпадению). Нахождение значения ключевого атрибута равного заранее известной величине;
в) время корректировки данных, т.е. включение или исключение одной записи;
г) объем дополнительной памяти. Например, для адресов связи.
3.2. Последовательная организация данных.
При последовательной организации данных записи располагаются в памяти строго одна за другой, без промежутков, в той последовательности, в которой они обрабатываются. Записи массива могут быть упорядоченными или неупорядоченными по значениям ключевого атрибута.
а)Формирование данных.
Процедура упорядочения состоит из серии сравнений ключевых атрибутов и тех или иных перераспределений записей по результатам сравнения. Массив из М записей, обладающий неопределённостью состояния называется случайным массивом. Для него возможны М! состояний.
Таким образом, минимальное число сравнений, необходимое для упорядочения массива из М записей, определяется как С = log М!.
Справедлива запись выражения для времени сортировки Т ~ М • log М.
б) Поиск в последовательном массиве.
Поиском называется процедура выделения из некоторого множества записей определенного подмножества, записи которого удовлетворяют некоторому заранее поставленному условию. Условие поиска часто называют запросом на поиск.
Простейшим условием поиска является поиск по совпадению, т. е. равенство значения ключевого атрибута i-й записи p(i) и некоторого заранее заданного значения q..
Базовым методом доступа к массиву является ступенчатый поиск, он предполагает упорядоченность обрабатываемых записей. Простейшим вариантом одноступенчатого поиска является последовательный поиск. Искомое значение q сравнивается с ключом первой записи и последовательно с каждой последующей записью до совпадения. Количество сравнений С пропорционально М (С ~ М).
Для ускорения поиска используется двухступенчатый поиск в массиве. Для заданного М выбирается константа dl, называемая шагом поиска. Если необходимо отыскать запись со значением ключевого атрибута, равным q, производятся следующие действия. Значение q последовательно сравнивается с рядом величин р(1), p(l+dl), p(l+2*dl), ..., p(l+k*dl) до тех пор, пока будет впервые достигнуто неравенство p(l+m*dl)=>q. На второй ступени q последовательно сравнивается со всеми ключами найденного интервала
Эффективность поиска измеряется количеством произведенных сравнений. Для двухступенчатого поиска среднее число сравнений примерно составит:
C=M/(2*dl)+dl/2.
Ступенчатый поиск имеет важный частный вариант -бинарный поиск. Для бинарного поиска вводятся граница интервала поиска. Вычисляется середина интервала по формуле i=(A+B)/2, сравнивается с искомым значением, выбирается та половина, где находится искомое значение. Алгоритм повторяется. Количество вариантов поиска уменьшается в арифметической прогрессии. Среднее число сравнений при бинарном поиске составляет C=log(M) -1.
Определение лучшего метода поиска (из рассмотренных выше последовательного, двухступенчатого и бинарного) опирается на следующие рассуждения. Во всех трех случаях время поиска является функцией от числа записей М. Конкретные выражения составляют:
для последовательного поиска Т1=k1*М;
для двухступенчатого поиска T2~ k2*lnM;
для бинарного поиска T3=k3*logM.
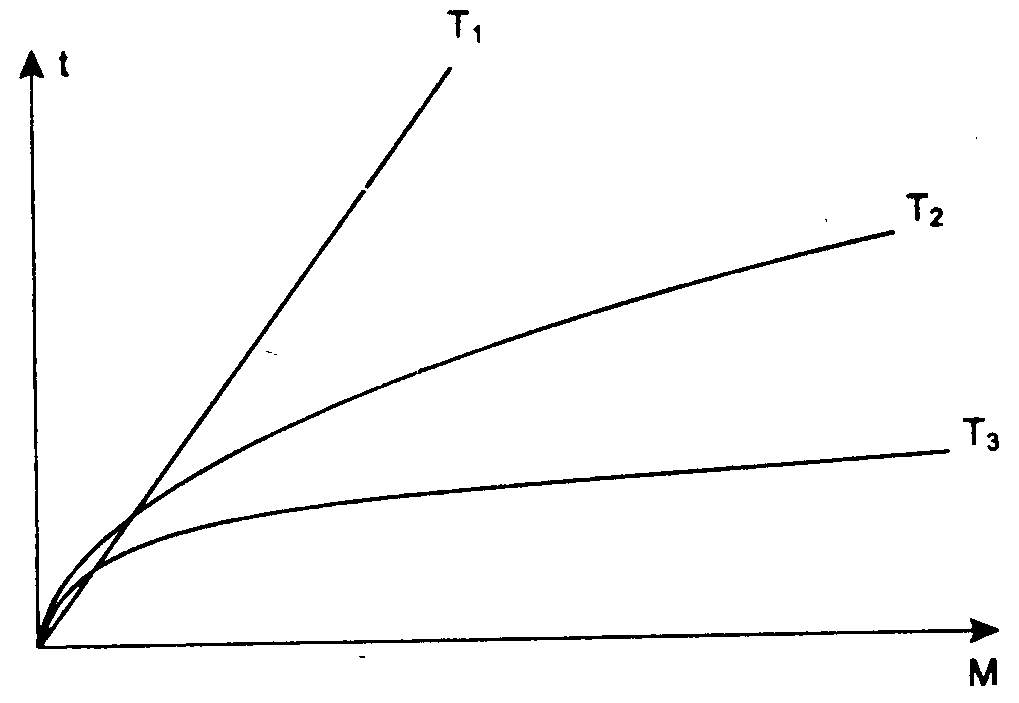
Рис. 3.1. Сравнение методов поиска данных в массиве
При больших массивах данных преимущество бинарного поиска, безусловно.
в) Корректировка последовательного массива
Включение и исключение записей по одиночке является длительной процедурой. Поэтому корректирование записи накапливаются в специальном массиве изменений, который составляет какой-то процент от основного массива. При необходимости обработки основного массива он объединяется с массивом изменений.
При объединении основного массива с массивом изменений выполняются следующие операции (алгоритм слияния):
-ключ очередной записи основного массива сравнивается с ключом очередной записи массива изменений, и запись с меньшим значением ключа добавляется в новый массив (результат слияния);
-когда все записи одного из массивов будут перезаписаны полностью, оставшиеся записи другого массива добавляются в результирующий массив, и алгоритм заканчивается.
Время корректировки Т ~М.