

1) , 4) ,
2) , 5) ,
3) , 6) ,
7)
![]() ,
,
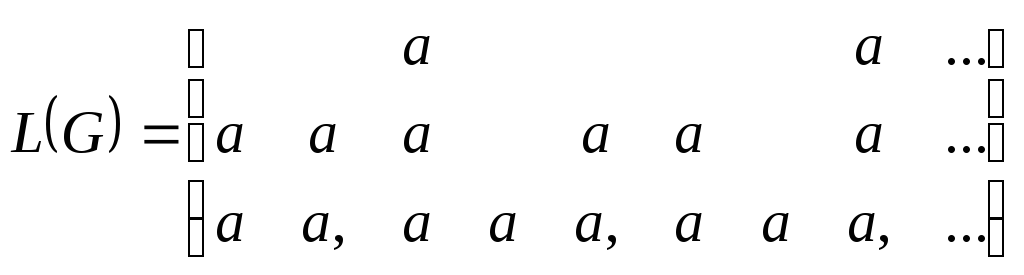 .
.
Например,
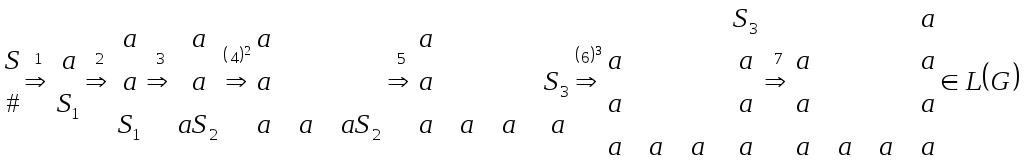 .
.
Символы алфавита в грамматиках деревьев соответствуют деревьям, конкатенация производится в узлах деревьев. В грамматиках сетей символы алфавита соответствуют помеченным графам — сетям с произвольным числом точек, в которых сети могут сцепляться друг с другом. Еще более сложную структуру представляют собой грамматики графов [28, 43]. Для всех вышеперечисленных типов грамматик проведена классификация по Хомскому. Как в случае строковых грамматик, годными к практическому использованию являются контекстно-свободные и регулярные грамматики таблиц, сетей, деревьев, графов [28, 43, 47].
Синтактико-семантические методы. Синтаксическая модель позволяет эффективно учитывать структуру и контекст (сочетаемость примитивов) изображения. Однако, решая задачу описания объекта, желательно иметь еще некоторую качественную информацию о подобразах, т. е. учитывать и семантический аспект изображения. Этого можно достичь, описав каждый примитив и отношения между ними с помощью набора характеристик (признаков, атрибутов) и установив соотношения, по которым получают атрибуты производных подобразов. Такой сннтактико-семантический подход позволяет сделать описание объекта более гибким и эффективным. Для формализации синтактико-семантического подхода к описанию используют атрибутные грамматики [28, 43, 45].
Введение атрибутных грамматик
основано на следующих утверждениях
[45]. Пусть есть объект S,
состоящий из двух примитивов X
и Y с отношением R
между ними:
![]() .
Примитивы X,
Y и
отношение R
можно описать через наборы (векторы)
признаков (атрибутов), т. е.
.
Примитивы X,
Y и
отношение R
можно описать через наборы (векторы)
признаков (атрибутов), т. е.
![]() ,
,
![]() ,
,
![]() .
.
Вектор атрибутов объекта S представим в виде функции атрибутов X, Y и R:
A(S) = f(A(X), A(Y), A(R)).
Рассмотрим
некоторую одномерную грамматику. Пусть
среди продукций из множества P
имеется правило
![]() .
В этом случае отношение
R между символами есть
простая конкатенация, тогда A(S)
= f(A(X),
A(Y)).
Атрибутная строковая грамматика
представляет собой обычную строковую
грамматику с добавлением семантических
правил для вычисления атрибутов.
.
В этом случае отношение
R между символами есть
простая конкатенация, тогда A(S)
= f(A(X),
A(Y)).
Атрибутная строковая грамматика
представляет собой обычную строковую
грамматику с добавлением семантических
правил для вычисления атрибутов.
Формально атрибутная строковая
грамматика определяется как четверка
G = (VN,
VT,
Р, S),
где VN —
множество нетерминалов;
VT —
множество терминалов;
S —
начальный символ [45]. Для каждого символа
![]() существует конечное множество атрибутовА(X),
и атрибут
существует конечное множество атрибутовА(X),
и атрибут
![]() имеет конечный или бесконечный набор
возможных значенийDxj.
Каждая продукция из множества P
состоит из двух частей: синтаксического
правила и семантического правила, где
синтаксическое правило в форме для
КС-грамматик имеет вид:
имеет конечный или бесконечный набор
возможных значенийDxj.
Каждая продукция из множества P
состоит из двух частей: синтаксического
правила и семантического правила, где
синтаксическое правило в форме для
КС-грамматик имеет вид:
![]() .
Пусть
.
Пусть![]() ,
где
,
где![]() — словарь языка, для
всех i от 1 до k.
Тогда семантическое (атрибутное) правило
можно записать как отображение
— словарь языка, для
всех i от 1 до k.
Тогда семантическое (атрибутное) правило
можно записать как отображение
![]() ,
,
или
![]() .
.
Чтобы проиллюстрировать процесс установления семантических правил, рассмотрим следующий пример [45]. Пусть имеется некоторая дискретная кривая с уже выделенными примитивными элементами — последовательностью отрезков кривой. Предположим, что существует строковая КС-грамматика, описывающая данную конфигурацию. Определим для каждого отрезка кривой с вектор атрибутов А (с):
![]() .
.
где
![]() —вектор
прямолинейного отрезка, соединяющего
начало и конец примитива; L
— длина примитива;
— угол изменения наклона кривой: Z
—мера симметрии примитива с.
В качестве атрибута отношения
конкатенации между примитивами возьмем
угол
между ними. Тогда отрезок линии N,
состоящий из двух примитивов с1
и c2,
сцепленных под углом ,
будет выражен так:
—вектор
прямолинейного отрезка, соединяющего
начало и конец примитива; L
— длина примитива;
— угол изменения наклона кривой: Z
—мера симметрии примитива с.
В качестве атрибута отношения
конкатенации между примитивами возьмем
угол
между ними. Тогда отрезок линии N,
состоящий из двух примитивов с1
и c2,
сцепленных под углом ,
будет выражен так:
![]() ,
,
![]() ,
,
где
![]() обозначает вычисление атрибутов по
соотношениям (см. рис. 3.11):
обозначает вычисление атрибутов по
соотношениям (см. рис. 3.11):
![]() ;
;
LN = L1 + L2;
N = 1 + + 2;
![]() .
.
Д алее,
если
алее,
если
![]() ,
то
,
то
![]() .
Существенное свойство операции
.
Существенное свойство операции
![]() — ее ассоциативность.
— ее ассоциативность.
Важнейшим свойством атрибутных грамматик является то, что семантическая информация, дополняя синтаксическое описание, компенсирует его синтаксическую слабость, позволяя, например, для контекстно-зависимых грамматик без атрибутов строить эквивалентные контекстно-свободные или регулярные атрибутные грамматики. Это свойство достигается благодаря тому, что семантические правила помимо вычисления атрибутов, устанавливают ограничения на применение следующего правила подстановки.
Использование одномерных атрибутных грамматик, а также атрибутных грамматик более высокой размерности (грамматик деревьев, графов) [28, 45] делает возможным введение процедуры синтаксического анализа в качестве описывающей и распознающей процедуры. Методы разбора атрибутных грамматик усложнены по сравнению с простыми КС-грамматиками применением на каждом шаге подстановки семантических правил, поэтому для атрибутных грамматик могут использоваться модифицированные алгоритмы разбора КС-грамматик (например, алгоритм Эрли) [28, 43].
Синтаксический анализ (грамматический разбор) входного предложения может выполнять две функции. Процедура распознавания выявляет факт корректности организации входной строки в соответствии с правилами грамматики, порождающей «модельный» язык. Таким образом, может решаться как простейшая задача классификации, так и задача узнавания в рамках определенного класса форм. Широкое распространение получили методы грамматического разбора, корректирующего ошибки, иными словами, применимые к измененным входным данным (например, вследствие воздействия шумов, ошибок сегментации, неправильного распознавания примитивов) [28, 43]. Продукт синтаксического анализа — дерево разбора — может использоваться для полного описания входного изображения через его примитивные составляющие. Процесс грамматического разбора осуществляет, таким образом, синтез иерархической реляционной дескриптивной структуры. Особенно выпукло эта сторона процесса проявляется при использовании атрибутных грамматик, так как описание, получаемое при построении дерева раэбора, привносит большую долю семантической информации об изображении [28, 43, 45].
Вообще говоря, процедура синтаксического анализа в задачах распознавания недостаточно определена и считается вычислительно трудоемкой. Эффективные процедуры разбора могут быть получены для специальных классов языков либо выведены эвристически. Наиболее известный алгоритм разбора для класса КС-языков—алгоритм Эрли [43 ].
Реляционные структуры. Альтернативным подходом к синтезу структурных описаний кривых является полный отказ от формализма, заимствованного из теории формальных грамматик и языков. В рамках данного направления описание объекта строится с использованием реляционных структур, устанавливающих пространственные отношения между примитивами либо отношения типа часть— целое [37, 47].
В качестве структурной модели, отражающей пространственные отношения между частями объектов, используют графы (часто помеченные графы) и их табличные представления. Характерный пример подобной структуры – RSE-граф (region-segment-endpoint graph) [15]. Наибольшей эффективности применение аналогичных структур достигает для хорошо семантически определенных примитивов, поэтому при описании границ объектов их используют реже, чем при описании областей. Обычно в качестве отношений для контурных примитивов применяют отношения коллинеарности, «следует за», «слева (справа) от» и т. д.
Другим типом реляционных структур являются так называемые «деревья полосок» [32, 37]. Описание контура с использованием дерева полосок, с одной стороны, является аппроксимационным по отношению к описываемой кривой, а с другой — реализует на этой кривой отношение типа «часть — целое» и отношение следования, т. е. является иерархическим структурным описанием [32, 37]. Построение дерева полосок не требует предварительной процедуры выделения примитивов, так как каждый узел дерева сам по себе представляет аппроксимацию некоторого отрезка контура, который описывается фрагментом полоски (рис. 3.12) [32, 37].
Точки cb и ce на рис. 3.12,а соответствуют начальной и конечной точкам аппроксимируемого отрезка контура. Ориентация прямоугольника — фрагмента полоски — определяется прямой, соединяющей начальную и конечную точки отрезков. Ширина полоски w — минимальная ширина всех возможных прямоугольников, заданных длиной отрезка прямой [cb, ce] и содержащих целиком отрезок контура {cb, ce}.
Дерево полосок — бинарное дерево, таким образом, каждый узел дерева имеет двух «сыновей», соответствующих двум частям отрезка контура, представленного их «отцом». Каждый узел дерева полосок описывается восемью параметрами, из которых первые шесть служат для представления фрагмента полоски (это координаты начальной и конечной точек и две составляющие ширины wl и wr), а последние два указывают адреса «сыновей», если они существуют. Алгоритм, описываемый ниже, дает способ построения дерева полосок для дискретной кривой DC= (c1, ..., cN} посредством рекурсивного обращения к процедуре формирования узла дерева.
О писание
замкнутого контура с помощью дерева
полосок производится аналогично, в
соответствии с этим
алгоритмом.
писание
замкнутого контура с помощью дерева
полосок производится аналогично, в
соответствии с этим
алгоритмом.