

17. Линейная модель работы информационно-поисковой системы.
Считаем, что в системе имеется t дескрипторов (иначе говоря объем тезауруса равен t). Тогда любой документ (точнее его поисковый образ) можно идентифицировать с помощью битового (двоичного) вектора X=(x1,…..,xt), где xj=1, если j-й дескриптор присутствует в описании документа, в противном случае xi=0.
Если в системе d документов, то вся информация может быть представлена с помощью матрицы Cdt:
//расписать матрицу (3)
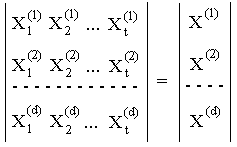
i-я строка матрицы является описанием i-го документа.
Запрос
(точнее его поисковое предписание) также
можно представить в виде битового
вектора Q=(q1,…,qt).
![]()
(формула
ri)
(4)
![]() - количество дескрипторов, которые
одновременно присутствуют и в запросе
и в i-м
документе. Эта величина называется
критерием релевантности i-го
документа относительно запроса
- количество дескрипторов, которые
одновременно присутствуют и в запросе
и в i-м
документе. Эта величина называется
критерием релевантности i-го
документа относительно запроса
![]() Q.
Q.
R![]() =(r1,….,rd)
- вектор релевантностей для запроса
Q.
=(r1,….,rd)
- вектор релевантностей для запроса
Q.
Результатом поиска обычно признаются документы, релевантность которых выше заданного порога r*, который должен зависеть от числа дескрипторов в запросе и в документе, что не очень удобно.
Выражение для R можно записать в матричной форме: R=C Q.
Пример. Пусть в системе имеется 6 дескрипторов и 2 документа имеющих описания (1,1,1,0,0,0) и (1,1,1,1,1,1). Подается запрос Q=(1,1,1,0,0,0). Тогда r1=r2=3, хотя очевидно, что 1-й документ лучше соответствует запросу.
Другой критерий: (формула ri)
Для нашего примера в этом случае r1=1, r2=1/2.
Как видим, второй критерий более совершенен, что объясняется учетом не только совпадений дескрипторов в описаниях, но и несовпадений.
К сожалению, в силу человеческого фактора, однотипные документы часто характеризуют разными ключевыми словами, и это необходимо учесть в поисковой модели. Целесообразно учитывать степень похожести дескрипторов и документов.
Вычислим матрицы A, D:
Att=СTtdCdt, Ddd= CdtCTtd.
Элемент ajm матрицы A показывает количество одновременных присутствий j-го и m-го дескрипторов в описаниях документов, а элемент dik матрицы D– количество общих дескрипторов в i-м и k-м документах. Таким образом, матрица A показывает степень похожести дескрипторов, а матрица D – степень похожести документов. С помощью определения порогов a* и d* эти матрицы приводятся к бинарному виду:
//формулы бинаризации матриц A и D (получаем A' и D') (5)
Пусть:
-
1
7
3
5
6
2
A
=
8
4
6
D
=
9
4
3
2
3
5
7
6
8
a٭ = 3
d٭ = 3
aij ≤ a*=> aij' = 0
aij > a* => aij = 1
dij ≤ d*=> dij' = 0
dij > d* => dij = 1
|
|
0 |
1 |
0 |
|
|
|
1 |
1 |
0 |
A |
= |
1 |
1 |
1 |
|
D |
= |
1 |
1 |
0 |
|
|
0 |
0 |
1 |
|
|
|
1 |
1 |
1 |
Имеем смысл использовать критерий: R=D'(C(A' Q)) (6)
R=D'(C (A' Q))
Фактически в этом случае все похожие дескрипторы автоматически добавляются к запросу, по расширенному запросу производится поиск, а затем к множеству полученных документов добавляются похожие.