

Файловые структуры. Классификация методов доступа
Прежде всего, дадим несколько определений.
Файл. Именованная структура данных, представляющая множество аналогично построенных (имеющих одинаковый формат) экземпляров хранимых записей одного типа.
Физическая база данных (БД на физическом уровне). Совокупность совместно хранимых взаимосвязанных данных, представляющая один или несколько типов хранимых данных, упакованных в один или несколько файлов.
Блок записей. Группа последовательно хранимых записей, которая используется при операциях обмена как единое целое. Обмен с внешней памятью блоками записей позволяет сократить время доступа, однако требует большего размера буфера в оперативной памяти. Вопрос о выборе размера блока будет рассмотрен ниже.
В каждой СУБД по-разному организовано хранение и доступ к данным; однако, существуют некоторые файловые структуры, использующиеся для хранения информации во внешней памяти, которые имеют общепринятые способы организации и широко применяются во всех СУБД. На рис.21. приведена возможная классификация подобных структур.
Способы последовательной организации
Физически последовательная организация
На рис.22. представлена простейшая для анализа организация, при которой записи размещаются в смежных областях (блоках):
Предполагается, что записи имеют постоянный размер и могут быть как неупорядоченными, так и упорядоченными по возрастанию или убыванию значений первичного ключа.
Последовательный метод доступа, заключающийся в последовательном переборе записей (с начала или конца файла) используется, в подавляющем большинстве случаев, для реализации операторов поиска всех или большинства записей. Однако, возможность упорядочивания записей позволяет в рамках физически-последовательной организации осуществлять достаточно эффективно и поиск уникальных записей, используя, например, алгоритм двоичного поиска.
Основной недостаток физически-последовательной организации связан со сложностью расширения файла.
Связная последовательная организация
Позволяет размещать записи в несмежных участках памяти (рис.23.).
Таким образом, участки файла образуют список. Такая организация существенно облегчает процесс модификации файла (рис.24.).
На рисунке пунктирной линией обозначена связь, которая разрывается при добавлении новой записи с ключем 04.
Список может быть двусвязным (рис.25.). При такой организации появляется возможность эффективной реализации поиска предшествующей записи.
Главным недостатком связанной последовательной организации является большая сложность при необходимости упорядочивания записей.
Прямые методы доступа. Хеширование
Файлы с прямым методом доступа обеспечивают механизм поиска записей по первичному ключу, отличный от последовательного просмотра. Прямой доступ к записи реализуется с помощью какого-либо метода отображения значения ключа в адрес. Наиболее распространенными методами отображения являются хеширование и индексирование.
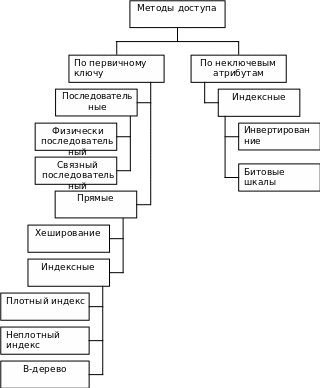
Рис.21. Классификация методов доступа
01 Иванов … |
02 Петров … |
03 Сидоров … |
… |
01, 02, 03 – значения первичного ключа.
Рис.22. Пример физически последовательной организации

Рис.23. Пример связной последовательной организации
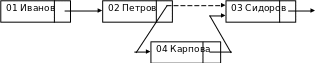
Рис.24. Механизм добавления записи в связную последовательную структуру

Рис.25. Двусвязная последовательная организация
Общей идеей методов хэширования является применение к значению ключа некоторой функции свертки (Хэш-функции), вырабатывающей значение меньшего размера. Свертка значения ключа затем используется для доступа к записи. В самом простом случае свертка ключа используется как адрес в таблице, содержащей ключи и записи.
В реальности записи файла разделяются между участками, каждый из которых содержит один или несколько блоков памяти. В этом случае хеширование обеспечивает прямую адресацию записи путем преобразования значения первичного ключа в абсолютный или относительный адрес участка.
Пусть v есть значение ключа записи и h – Хеш-функция. Тогда h (v) - адрес участка, в котором должна находиться искомая запись (в том случае, если она присутствует вообще). Общая схема организации хешированного файла представлена на рис.26.
Проблема синонимов
Очевидно, что при реализации Хеш-функции отношения 1:1 между значениями ключей и номерами участков размер справочника участков становиться неприемлемо большим, а величина самих участков неприемлемо малой, что приводит к нерациональному расходу памяти.
Реальным выходом из этой ситуации является принятие соглашения, при котором в общем случае Хеш-функции осуществляет отображение типа 1:M; однако в этом случае фиксируется эффект возникновения синонимов, когда записи с различными значениями ключей направляются для хранения в один участок, что приводит, в конечном счете, к различной степени загруженности участков.
И, если при использовании связанной последовательной организации блоков внутри участков (именно такая организация представлена на рис.26.) наличие синонимов приводит, в основном, только к различию во времени поиска в пределах отдельных участков, то при использовании физически последовательной организации могут возникнуть дополнительные проблемы, связанные с необходимостью введения области переполнения (рис.27.).
Очевидно, что возникновение слишком большого количества цепочек переполнения ведет к потере главное преимущества хэширования - доступа к записи практически всегда за одно обращение. Переход на использование новой хэш-функции (со значением свертки большего размера) требует перестройки всех участков основного файла, что в случае баз данных являются абсолютно неприемлемым. Поэтому обычно вводят промежуточные таблицы-справочники, содержащие значения ключей и адреса записей, а сами записи хранятся отдельно. Тогда при переполнении справочника требуется только его переделка, что вызывает меньше накладных расходов.
Замечание. Конечно, структура самой области переполнения может быть связанной последовательной или физически последовательной.
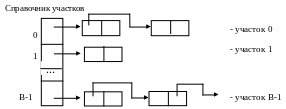

Рис.26. Общая схема организации процесса хеширования
Первичная область участков Область переполнения
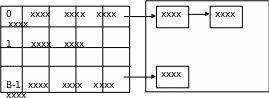
хххх – заполненные блоки.
Рис.27. Схема использования физически последовательных участков при хешировании
Итак, ключевым моментом выбора Хеш-функции является требование равномерного распределения синонимов по участкам.
Пример. Пусть исходные записи имеют следующие значения ключей:
36 |
26 |
12 |
5 |
95 |
Вариант 1. Значением Хеш-функции является выражение: <значение_ключа> (mod10) +1
Распределение синонимов по участкам примет вид:
-
№ уч-ка
Записи
1
2
3
12
4
5
6
5 95
7
36 26
8
9
10
Вариант 2. Значение Хеш-функции - это выражение: {сумма цифр ключа} (mod10) +1
Распределение синонимов по участкам примет вид:
-
№ уч_ка
Записи
1
2
3
4
12
5
95
6
5
7
8
9
26
10
36