

Доступ с неплотным индексом
Доступ с неплотным индексом (индексно-последовательный метод доступа) строится на основе физически упорядоченного по возрастанию значения ключей последовательного файла и совокупности пронумерованных индексных элементов (индексе), каждый из которых содержит ключ подобно записям основного файла; элементы в индексе упорядочиваются по возрастанию значений ключей. Значение ключа в индексном элементе представляет наибольший (или наименьший) из значений ключей записей, входящих в блок основного файла с номером, совпадающим с номером индексного элемента.
Структура индексно-последовательного файла представлена на рис.29.
Алгоритм поиска при данной организации файла очевиден и включает два этапа:
Поиск в индексе элемента, указывающего на блок, в котором должна находиться искомая запись, используя максимальное (или минимальное) значение ключей записей, размещенных в блоках основного файла.
Последовательный просмотр записей найденного блока.
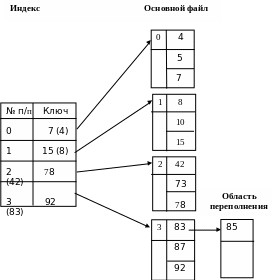
Рис.29. Схема организации индексно-последовательного файла
Таким образом, к записям индексно-последовательного файла с помощью индекса осуществляется прямой доступ к блоку (странице), включающему требуемую запись, и последовательный доступ в соответствии с упорядоченностью записей по этому ключу индексирования.
Использование индексно-последовательной организации наиболее эффективно, когда модификация исходного файла не предполагает его расширения. В противном случае, как праавило, необходимо введение области переполнения, существование которой принципиально ломает простоту алгоритм поиска, присущую индексно-последоватльному методу доступа
Сравнение метода полного индекса с индексно-последовательной организацией
В методе полного индекса не предусмотрена обработка переполнения; вместо этого всякий раз при включении новой записи в основной файл выполняется переупорядочивание индекса.
При отсутствии переполнения поиск всех записей в обоих методах имеют одинаковую производительность.
В обоих методах достаточно эффективно выполняется операция поиска записей с уникальными ключами.
Вследствие физически последовательного размещения записей операции типа ПОЛУЧИТЬ СЛЕДУЮЩУЮ и ПОЛУЧИТЬ ПРЕДЫДУЩУЮ выполняются гораздо эффективнее в методе неплотного индекса.
Добавление, а так же изменение значений первичных ключей в основном файле в обоих методах трудоемко, поскольку, как правило, влечет обновление индекса.
Организация индексов в виде в-деревьев
Построение В-деревьев связано с простой идеей создания индекса над уже построенным индексом. Например, при построении индексно-последовательного файла сама индексная область может быть рассмотрена как основной файл, над которым можно построить неплотный индекс, и так далее, пока индексную область не будет представлять только один блок.
В общем случае, может быть построено некоторое дерево, каждый родительский блок которого связан с одинаковым количеством подчиненных блоков, количество которых равно количеству индексных записей, размещенных в родительском блоке. Число шагов при этом для поиска любой записи основного файла одинаково и равно количеству уровней в дереве.
Такие деревья называют сбалансированными (путь от корня до любого листа одинаков) Таким образом, термин В-дерево происходит от английского balance (баланс). Пример организации В-дерева представлен на рис.30.
Использование техники B-деревьев в настоящее время, скорее всего, является наиболее популярным подходом к организации индексов в базах данных. С точки зрения внешнего логического представления, B-дерево - это сбалансированное, сильно ветвистое дерево во внешней памяти. Ветвистость дерева - это свойство каждого узла дерева ссылаться на большое число узлов-потомков. С точки зрения физической организации, B-дерево представляется как мультисписочная структура страниц внешней памяти, то есть каждому узлу дерева соответствует блок внешней памяти (страница, см. п.7.3.2.). Внутренние и листовые страницы обычно имеют разную структуру.
Поиск в B-дереве - это прохождение от корня к листу в соответствии с заданным значением ключа.
B-деревья универсальны и обеспечивают хорошую скорость доступа как при просмотрах по диапазонам, так и при выборке единичной записи по значению ключа, однако характеризуются относительно большим объемом памяти для хранения и затратами на поддержание в актуальном состоянии, включающими обычно балансировку дерева.