

Иерархическая модель
Основные понятия. Основным типом логической структуры, поддерживаемой иерархическими СУБД, является иерархическая (древовидная) структура (или просто иерархия).
Иерархическая структура определяется на соответствующих типах записей согласно схеме базы данных (дереву определений, типу дерева). В этом дереве типы записей являются узлами, а дуги представляют иерархические связи ("исходный-порожденный", "род-вид", "элемент-класс" и т.п.) между узлами дерева различных уровней. Тип дерева состоит из одного "корневого" типа записи и упорядоченного набора (из нуля или более) типов поддеревьев (каждое из которых является некоторым типом дерева). Тип дерева в целом представляет собой иерархически организованный набор типов записей.
Содержимое иерархической БД представляется упорядоченным набором нескольких экземпляров типа дерева.
В общем случае иерархия должна удовлетворять следующим условиям:
Одно дерево может иметь только один корень (исходный узел).
Узел должен иметь один или несколько атрибутов, описывающих семантику объекта.
У родительского узла может быть несколько потомков.
Потомок может быть связан только с одним родительским узлом.
Порожденные узлы могут быть добавлены как в горизонтальном, так и в вертикальном направлениях. Ограничения, например, на глубину иерархии, могут накладываться только требованиями конкретной иерархической СУБД.
Если разность уровней двух связанных узлов равна единице, связь является непосредственной; кроме того, любые две вершины дерева, принадлежащие одной его ветви, транзитивно связаны друг с другом.
Пример. На рис.14. представлена иерархическая база данных:
(а) - дерево определения с пятью узлами (типами записей) A, B, C, D и E, обозначенными прямоугольниками. Символы внутри прямоугольников задают атрибуты объектов,
(б) – загруженная база данных (экземпляры дерева определений R1, R2).
Пусть типы записей базы данных представляют следующие объекты предметной области:
A – "ДИСЦИПЛИНА",
B – "УЧЕБНЫЙ ПЛАН",
C – "СЕМЕСТР",
D – "ПРЕПОДАВАТЕЛЬ",
E – "СТУДЕНЧЕСКАЯ ГРУППА".
В такой трактовке экземпляры базы данных могут быть интерпретированы следующим образом:
Экземпляр R1. Дисциплина A1 включена в учебный план; больше о ней ничего не известно.
Э кземпляр
R2.
Дисциплина A2
включена в учебный план. Для нее
запланировано проведение занятий в
семестрах C1
и C2
преподавателем D1
в группах E1
и E2
и в семестре C3
в группе E3,
однако преподаватель еще не определен.
кземпляр
R2.
Дисциплина A2
включена в учебный план. Для нее
запланировано проведение занятий в
семестрах C1
и C2
преподавателем D1
в группах E1
и E2
и в семестре C3
в группе E3,
однако преподаватель еще не определен.

Рис.14. Иерархическая база данных
Принципы организации физического хранения записей. Набор всех экземпляров записей, подчиненных одному экземпляру корневой записи, называется физической записью. Порядок хранения экземпляров типов записей в физической записи зависит от особенностей реализации, определяющих способ отображения логических деревьев в физические структуры файлов конкретной СУБД. Наиболее простой способ состоит в линеаризации дерева; при этом экземпляры типов записей хранятся последовательно в порядке обхода дерева сверху вниз слева направо.
Пример. Физическая запись, хранящая экземпляры R1 и R2 при линеаризации, будет выглядеть следующим образом:
A1 B1 |
A2 B2 C1 D1 E1 E2 C2 D1 E1 E2 C3 E3 |
Запись 1 |
Запись 2 |
Ясно, что при этом в общем случае физические записи будут иметь различную длину, причем длина некоторых из них может оказаться недопустимо большой (как с точки зрения занимаемых ресурсов памяти, так и времени поиска нужной информации). Поэтому в иерархических СУБД широко используется аппарат разделения графа, представляющего дерево определений, на подграфы (поддеревья), хранящиеся (реализуемые) отдельно, но в целом (в совокупности) представляющие единую логическую структуру – дерево определений.
Такое расчленение обычно соответствует делению предметной области на фрагменты, каждый из которых описывается своим подграфом дерева определений.
Пример. Дерево определений, представляющее структуру университета (до определенного уровня), может быть представлено следующим графом (рис.15.):
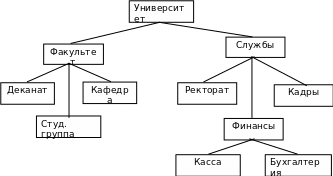
Рис.15. Упрощенный вид дерева определений ПО "Университет"
В данном дереве можно выделить такие фрагменты, как например, Деканат, Ректорат, Кадры, Финансы и т.п. Каждый из фрагментов предметной области представляется отдельной физической базой данных (ФБД).
Концептуальная модель. Совокупность взаимосвязанных ФБД образует концептуальную иерархическую модель данных. Очевидно, что в простейшем случае дереву определений ("бумажной" модели) соответствует одна ФБД. Каждая ФБД на физическом уровне реализуется отдельным набором физических записей. Для каждой ФБД на языке описания данных должно присутствовать как описание ее логической структуры, так и структуры хранения.
Внешняя модель. При работе с иерархической моделью внешняя представляет собой совокупность поддеревьев для физических баз данных, с которыми работает данное приложение. Каждое поддерево внешней модели в обязательном порядке должно содержать корневой тип сегмента соответствующей ФБД концептуальной модели.
Представление внешней модели часто называют логической базой данных и определяется она совокупностью блоков связи данного приложения с ФБД, входящими в состав концептуальной схемы иерархической базы данных.
Навигация в иерархических структурах. Язык манипулирования данными (ЯМД) в иерархической модели поддерживает в явном виде навигационные операции, связанные с перемещением указателя, который определяет текущий экземпляр конкретной записи. Поскольку в иерархических СУБД способ реализации операций поиска ориентирован на древовидную структуру, сам поиск должен начинаться с корня и продолжаться в направлении порожденных узлов. Очевидно, что отсутствие в конкретной реализации какого-либо иного способа доступа к требуемому типу записи, кроме последовательного, порождает проблему оптимального физического распределения узлов в дереве для минимизации времени поиска. Как правило, ЯМД иерархических СУБД включает операции прямого доступа к записям, то есть, "горизонтального" просмотра дерева.
Примеры типичных операторов манипулирования иерархическими данными:
найти указанное дерево БД (например, предмет “Информатика”);
перейти от одного дерева к другому;
перейти от одной записи к другой внутри дерева (например, от одной группы к другой);
перейти от одной записи к другой в порядке обхода иерархии;
вставить новую запись в указанную позицию;
удалить текущую запись.
Ограничения целостности. Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя. Заметим, что аналогичное поддержание целостности по ссылками между записями, не входящими в одну иерархию, не поддерживается.
Общие правила определения целостности БД отсутствуют. В некоторых системах поддерживают ограничения уникальности значений некоторых полей, но в основном все возлагается на прикладную программу.