

23. Числовые характеристики выборки.
Вариационные ряды и графики эмпирических распределений дают наглядное представление о том, как варьируется признак в выборочной совокупности. Но они недостаточны для полной характеристики выборки , поскольку содержат много деталей, охватить которые невозможно без применения обобщающих числовых характеристик .
Числовые характеристики выборки дают количественное представление об эмпирических данных и позволяют сравнивать их между собой. Наибольшее практическое значение имеют характеристики положения, рассеяния и асимметрии эмпирических распределений.
Среднее арифметическое представляет собой такое значение признака, сумма отклонений выборочных значений признака от которого равна нулю.
Геометрический смысл среднего арифметического - точка на оси х, которая является абсциссой центра масс гистограммы.
Среднее арифметическое может вычисляться как по необработанным первичным данным, так и по результатам группировки этих данных.
Для несгруппированных данных:
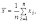
где n - объем выборки ; xi - варианты выборки. Для сгруппированных данных:

где n - объем выборки; k - число интервалов группировки; ni - частоты интервалов; xi - срединные значения интервалов.
Медианой (Ме) называется такое значение признака X, когда одна половина значений экспериментальных данных меньше ее, а вторая половина - больше.
Для
вычисления медианы несгруппированных
данных выборку ранжируют, т. е. располагают
данные в порядке возрастания или
убывания, и в ранжированной выборке,
содержащей n членов, ранг R (порядковый
номер) медианы определяется как
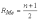 .
Если четное число членов в выборке, то
медианой будет среднее арифметическое
между двумя центральными значениями
членов выборки, порядковый номер которых
больше и меньше полученного значения
ранга медианы.
.
Если четное число членов в выборке, то
медианой будет среднее арифметическое
между двумя центральными значениями
членов выборки, порядковый номер которых
больше и меньше полученного значения
ранга медианы.
Для нахождения медианы в случае сгруппированных данных находят интервал группировки, в котором содержится медиана, путем подсчета накопленных частостей. Медианным будет тот интервал, в котором накопленная частота впервые окажется больше n/2 (n - объем выборки) или частость - больше 0,5. Внутри медианного интервала медиана определяется по следующей формуле:
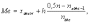
где хMeН - нижняя граница медианного интервала; h - ширина интервалов группировки; nxMe-1 - накопленная частота интервала, предшествующего медианному; nMe - частота медианного интервала.
Мода (Мо) представляет собой значение признака, встречающегося в выборке наиболее часто.
Интервал группировки с наибольшей частотой называется модальным.
Для несгруппированных данных мода - это значение признака с наибольшей частотой появления.
Для определения моды сгруппированных данных используется следующая формула:
 ,
,
где xMoH - нижняя граница модального интервала, nMo - частота интервала.
В случае, когда все значения в группе встречаются одинаково часто, принято считать, что группа оценок не имеет моды.
Когда два соседних значения имеют одинаковую частоту и они больше частоты любого другого значения, мода есть среднее этих двух значений.
Если два несмежных значения в группе имеют равные частоты и они больше частот любого значения, то существуют две моды, а группа оценок является бимодальной.