

4. Сглаживание временного ряда с использованием авторегрессионной модели. Оценка точности прогнозирования уровня показателя.
По графику ACF в приложении 11 можно предположить наличие автокорреляции 7-го порядка. Проверим эту гипотезу, используя критерий Бокса-Пирса и Бокса-Льюинга.
Н0: значения временного ряда не являются автокоррелированными с порядком автокорреляции до 7 включительно.
Критерий
Бокса-Пирса:
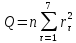
Критерий
Бокса-Льюинга:
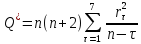
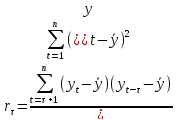
В приложении 12 были посчитаны значения r, суммы r^2 и суммы r^2/(122). Таким образом:
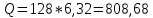
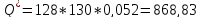

Каждая из расчетных статистик больше критического значения, поэтому первые 7 значений ACF не могут игнорироваться и быть признаны несущественными.
Рассчитаем статистики для 7-го значения ACF:
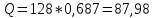
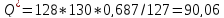
Каждая из расчетных статистик больше критического значения, поэтому 7-е значение ACF не может игнорироваться и быть признано несущественными.
Из этого можно сделать вывод о наличии автокорреляции7-го или большего порядка.
По графикам автокорреляции и частной корреляции в приложении 11 можно сделать вывод о наличии смешанного процесса, так как функции ACF и PACF бесконечны. Так как дисперсии и средние двух частей выборки не равны, то следует проинтегрировать (использовать разности d-го порядка). Интегрирование применяется для того, чтобы привести ряд к стационарному виду.
Рассмотрим разности 1го, 2го, 3го и 4го порядка:
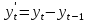
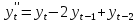
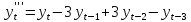
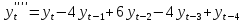
Посчитаем разности и проверим гипотезы о равенстве дисперсий и средних (приложение 13). Для разностей первого и второго порядка наблюдается неравенство дисперсий двух выборок. То есть эти ряды не являются стационарными. Дисперсии и средние рядов разностей третьего и четвертого порядка равны, то есть ряды стационарны. Значит, для построения модели ARIMA следует использовать порядок интегрирования 3 или 4.
В приложении 14 было построено несколько моделей ARIMA(p,d,q). Параметры подбирались по следующим критериям:
-
Значимость всех коэффициентов
-
Модели должны пройти тесты на случайность (Test for excessive runs up and down и Test for excessive runs above and below median), тест на автокорреляцию Бокса-Пирса и на различия в дисперсиях и средних (приложение 12 п.6)
В сводной таблице (приложение 14 п.7) представлены спрогнозированные значения по моделям.
Посчитаем прогностические и информационные характеристики:
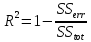 , где
, где
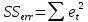 ,
,
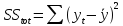
|
|
ARIMA(4,3,1) |
ARIMA(3,3,1) |
ARIMA(3,4,2) |
ARIMA(4,4,2) |
ARIMA(4,4,1) |
|
SSer |
297167,355 |
350748,418 |
364327,3543 |
362869,726 |
446664,03 |
|
s^2 |
2476,39463 |
2898,74725 |
3061,574406 |
3075,16717 |
3753,47924 |
|
s |
49,7633864 |
53,8400154 |
55,33149561 |
55,4541898 |
61,2656449 |
|
Kt1 |
0,03358903 |
0,01579395 |
0,023010374 |
0,02394742 |
0,00961631 |
|
Kt2 |
0,0233556 |
0,01108017 |
0,016084671 |
0,01673184 |
0,00676715 |
|
Ut |
0,01651716 |
0,0078351 |
0,011374316 |
0,01183202 |
0,00478515 |
|
SStot |
3591199,01 |
3591199,01 |
3573130,456 |
3573130,46 |
3573130,46 |
|
R^2 |
0,91725121 |
0,90233111 |
0,898036929 |
0,89844487 |
0,87499364 |
Таблица 9
Наилучшие прогностические характеристики имеет модель ARIMA(4,4,1), но она имеет худшие информационные характеристики. Наилучшие информационные характеристики (наибольший R^2) имеет модель ARIMA(4,3,1), но эта модель имеет худшие прогностические характеристики.
Также можно оценить модели с помощью таких информационных критериев, как критерий Акаике (AIC), Шварца (SIC) и критерий окончательной ошибки (FPE).
критерий
Акаике:
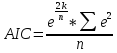
критерий
Шварца:
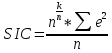
критерий
окончательной ошибки:
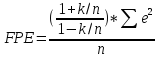
|
|
ARIMA(4,3,1) |
ARIMA(3,3,1) |
ARIMA(3,4,2) |
ARIMA(4,4,2) |
ARIMA(4,4,1) |
|
AIC |
2575,34042 |
2991,44178 |
3184,885646 |
3223,72175 |
3904,65838 |
|
SIC |
2884,73489 |
3274,81543 |
3568,471722 |
3695,07833 |
4374,93353 |
|
FPE |
2575,45041 |
2991,50717 |
3185,024987 |
3223,96558 |
3904,82921 |
Таблица 10
Исходя из этого, лучшей из рассмотренных моделей является ARIMA(3,3,1), так как она имеет лучшие прогностические характеристики после модели ARIMA(4,4,1) и лучшие информационные характеристики после модели ARIMA(4,3,1).
Полученная
модель имеет вид:
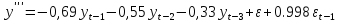 ,
где
,
где
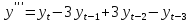
Если перестроить модель по всей выборке, то она имеет вид:
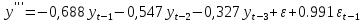
Точечный прогноз на 130 период = 1030,16, дисперсия остатков = 2625,29 с 122 степенями свободы.
Оценим доверительные интервалы для наилучшего варианта по формуле:
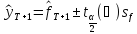 ,
где
,
где
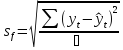
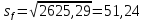
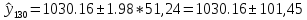
Значение индекса находится в интервале от 928,71 до 1131,61.