

3. Сглаживание временного ряда с использованием модели тренда. Оценка точности прогнозирования уровня показателя.
Так как при анализе абсолютных приростов было обнаружено, что рост показателя можно охарактеризовать как рост с качественными показателями, то для построения тренда целесообразно использовать следующие модели:
-
Линейно-логарифмическая функция 2-го порядка:
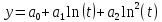
-
Парабола третьего порядка:
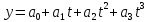
-
Логистическая функция:
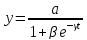 ,
где
,
где
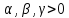
-
Первая функция Торнквиста:
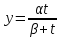 , где
, где
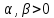
-
Кривая Гомперца:
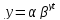 , где
, где
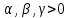
Также рассмотрим модель линейного тренда.
Выбор модели
Модели были построены в приложении 8, а спрогнозированные значения представлены в сводной таблице (приложение 8 п. 8). Все коэффициенты моделей и модели в целом значимы с вероятностью 95%. Для определения прогностических характеристик выведем остатки моделей (приложение 9).
Прогностические и информационные характеристики представлены в таблице 7.
|
модель |
Характеристики модели |
||||||
|
R^2 |
s^2 |
s |
DW |
Kt |
Kt2 |
Ut |
|
|
линейного тренда |
28,4786 |
20869,27 |
144,462 |
0,110215 (P=0,0000) |
0,022749 |
0,015921 |
0,011258 |
|
Линейно-логарифмическая функция 2-го порядка |
27,4358 |
21001,52 |
144,919 |
0,117019 (P=0,0000) |
0,029717 |
0,021009 |
0,014855 |
|
Парабола третьего порядка |
31,4408 |
20170,25 |
142,022 |
0,115369 (P=0,0000) |
0,084498 |
0,0618 |
0,043726 |
|
Логистическая функция |
97,9494 |
20540,05 |
143,318 |
0,111105 |
0,031349 |
0,022194 |
0,015693 |
|
Первая функция Торнквиста |
97,302 |
27025,72 |
164,395 |
0,0900128 |
0,124169 |
0,092443 |
0,065464 |
|
Кривая Гомперца |
97,9222 |
20813,26 |
144,268 |
0,10961 |
0,02457 |
0,017116 |
0,012104 |
Таблица 7
Наилучшие
прогностические характеристики
(наименьшее значение коэффициентов
Тейла) имеют модели линейного тренда и
кривая Гомперца. Лучшие информационные
характеристики имеют логистическая
функция и кривая Гомперца. R^2
кривой Гомперца намного превосходит
R^2 линейной функции, а
также стандартная ошибка кривой Гомперца
немного меньше, чем у модели линейного
тренда. Поэтому целесообразно выбрать
кривую Гомперца:
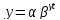 (Y= 832,081*1.09^(0.03*t)). Стоит отметить значительный
автокорреляционный эффект во всех
моделях. Он может быть исправлен
построением модели ARIMA
для остатков.
(Y= 832,081*1.09^(0.03*t)). Стоит отметить значительный
автокорреляционный эффект во всех
моделях. Он может быть исправлен
построением модели ARIMA
для остатков.
Проанализируем зависимость точности прогноза от длительности ретроспективного периода, перестроив логистическую модель (приложение 10). Оценим прогностические и информационные характеристики полученных моделей:
|
n (n<=T) |
модель |
характеристика модели |
|||||
|
R^2 |
s |
s^2 |
Kt |
Kt2 |
Ut |
||
|
124 |
Y= 832,081*1.09^(0.03*t) |
97,9222 |
144,268 |
20813,26 |
0,048163483 |
0,03355294 |
0,023728 |
|
110 |
Y= 830,49*1.09^(0.03*t) |
97,7667 |
151,933 |
23083,64 |
0,046936954 |
0,03273072 |
0,023146 |
|
100 |
Y = 828,155*1.09^(0.03*t) |
97,6608 |
157,046 |
24663,45 |
0,045238255 |
0,03159181 |
0,02234 |
|
90 |
Y = 833,784*1.09^(0.03*t) |
97,5596 |
163,605 |
26766,6 |
0,049522289 |
0,03446327 |
0,024372 |
|
80 |
Y = 841,442*1.09^(0.03*t) |
97,4645 |
170,525 |
29078,78 |
0,056217195 |
0,03893752 |
0,027539 |
|
60 |
Y = 852,086*1.09^(0.03*t) |
97,1608 |
187,915 |
35312,05 |
0,066655808 |
0,04586481 |
0,032443 |
|
40 |
Y = 790,103*1.09^(0.03*t) |
97,6248 |
163,672 |
26788,52 |
0,043003566 |
0,03074668 |
0,021743 |
|
30 |
Y =761,061*1.09^(0.03*t) |
97,7766 |
155,001 |
24025,31 |
0,068435405 |
0,04981643 |
0,035241 |
|
20 |
Y = 830,343*1.09^(0.03*t) |
99,58 |
73,647 |
5423,881 |
0,046829181 |
0,03265856 |
0,023095 |
Таблица 8
Из таблицы 8 видно, что лучшими прогностическими характеристиками обладает модель, построенная по последним 40 наблюдениям.
Построим доверительный интервал по формуле:
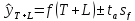
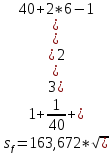
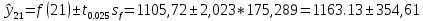
Значение индекса в 130 периоде находится в интервалах от 808,52 до 1517,74.