

Тема 7. Ймовірносно - статистичні методи
Основні положення теорій ймовірностей та випадкових помилок. Типи помилок виміру. Закони великих чисел та зростання точності спостережень. Функція розподілу та його густина; математичне очікування, дисперсія та середньоквадратичне відхилення; закони розподілу випадкової величини. Кореляційний момент та коефіцієнт кореляції.
В наукових дослідженнях зустрічаються явища, які багаторазово повторюються в незмінних умовах. Незважаючи на постійність основного комплексу параметрів, результати спостережень завжди в більшому або в меншому ступені є відмінними один від одного, тобто мають випадкове розсіювання. Окремі факти являють собою вихідний матеріал, який потребує глибокої узагальнюючої обробки. Методи, правила і необхідні формули для обробки результатів спостережень дає математична статистика. Це наука про методи кількісного аналізу масових явищ і її основою є теорія імовірностей і теорія помилок.
Нагадаємо основні положення теорії імовірностей.
Випадкові події діляться на:
- достовірні, тобто події, які повинні відбутися невідмінно;
- події несумісні, якщо виникнення однієї з них цілковито виключає можливість виникнення хоча б однієї з інших;
- події єдино можливі, коли при появі умов, необхідних для виникнення подій, одна з них невідмінно здійснюється;
- події неможливі, які не можуть відбутися ні в якому разі;
- події незалежні, коли виникнення однієї або декількох з них не змінює імовірності виникнення кожної з інших;
- події протилежні, якщо число випадків, які сприяють виникненню і однієї, і другої події в підсумку дорівнює загальній кількості всіх можливих подій;
- імовірні події, коли деякі випадки сприяють їх появі, а решта – ні.
Імовірністю
сприятливої події
називають відношення можливого числа
всіх сприятливих подій до повного числа
подій, яке вміщує в себе як кількість
сприятливих подій п
, так і кількість несприятливих m: Р(n) =
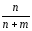 .
.
Імовірність
несприятливої події:
Р(m) =
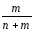 .
.
Очевидно, що сумарна імовірність дорівнює одиниці: Р(n) + Р(m) = 1
Якщо
виконано N спостережень і з цього числа
К разів з/являлася
сприятлива подія, то частота
появи сприятливої події
буде
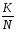 .
Основним законом теорії імовірностей
є закон
великих чисел,
який стверджує, що при достатньо великої
кількості спостережень N з імовірністю,
яка наближується до достовірності (
імовірність появи події наближується
до 1), частота появи події як завгодно
мало відрізняється від імовірності
цієї події: |Р(n) -
.
Основним законом теорії імовірностей
є закон
великих чисел,
який стверджує, що при достатньо великої
кількості спостережень N з імовірністю,
яка наближується до достовірності (
імовірність появи події наближується
до 1), частота появи події як завгодно
мало відрізняється від імовірності
цієї події: |Р(n) -
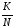 |
< ε, де ε – як завгодно мале позитивне
число, яке є відмінним від нуля.
|
< ε, де ε – як завгодно мале позитивне
число, яке є відмінним від нуля.
Це співвідношення дає можливість встановити дослідним шляхом з достатньо добрим наближенням імовірність невідомої випадкової події.
За теорією випадкових помилок ніякий вимір не може бути виконаний абсолютно точно, його результат завжди утримує помилку. Помилка виміру – це різниця між результатом виміру і істинним значенням. Оскільки істинне значення величини, що вимірюється, є невідомим, то і помилка виміру звичайно також невідома.
Розрізняють три основних типи помилок виміру: промахи, випадкові і систематичні помилки.
Грубі помилки або промахи виникають внаслідок порушення основних умов виміру і є недоліком уваги дослідника. Повне виключення грубих помилок і нехарактерних для процесу, що вивчається, дослідних даних є важливою умовою отримання надійних результатів.. Після виявлення грубої помилки результат такого виміру треба відкинути і вимір повторити.
Величина систематичних помилок є однаковою у всіх вимірах, які проведені одним і тим же методом за допомогою одних і тих же приладів. Систематичні помилки намагаються своєчасно виявити, знайти їх величину і усунути або зменшити шляхом введення відповідних поправок в результати виміру, оскільки їх накопичення може значно перекрутити результати досліду.
Систематичні помилки можна розділити на 4 групи:
а) помилки, природа яких відома і величина може бути достатньо надійно визначена. Такі помилки називають поправками. Прикладом може служити вплив температури холодного спаю термопари на результати виміру температури в об’єкті. Величина поправок, які ще має сенс вводити, встановлюється в залежності від значень інших помилок, які супроводжують досліди;
б)
помилки
відомого походження, але невідомої
величини.
Прикладом таких помилок є погрішність
вимірювання приладів, яка визначається
класом точності: δприладу
=
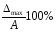 ,
де Δmax
– максимально припустима похибка
приладу; А – граничне значення шкали
приладу.
,
де Δmax
– максимально припустима похибка
приладу; А – граничне значення шкали
приладу.
За класом точності прилади ділять на робочі та зразкові. Робочі використовують для практичних вимірів; вони можуть бути технічні і лабораторні. Зразкові прилади використовують для перевірки і градуювання робочих.
Технічними приладами величину вимірюють один раз і поправок в результати не вносять. Максимально припустима помилка такого приладу Δmax дорівнює половині вартості поділки його шкали.
Лабораторні прилади мають підвищену точність завдяки виключенню з їх показників систематичних помилок шляхом внесення поправок. Цими приладами виконують багаторазові виміри для усереднення результатів.
В зразкових приладах виключення систематичних похибок здійснено заводом – виробником. В свідоцтві на такий прилад вказана залежність між дійсним значенням величини і показами приладу, а також клас його точності, який звичайно є на порядок вищим, ніж у аналогічного технічного приладу;
в) помилки, про існування яких немає відомостей, хоча величина їх може бути дуже значною. Найчастіше вони виникають при складних вимірах. Найбільш надійним засобом виявлення таких похибок є вимір однієї і той же величини різними методами і в різних умовах. Збіг отриманих результатів служить певною гарантією правильності вимірів.
г) помилки, які обумовлені властивостями об’єкту виміру. Ці помилки звичайно переводять до групи випадкових помилок, що дозволяє поліпшити точність отриманих результатів.
Випадкові помилки є різними навіть для вимірів, які виконані однаковим чином. Вони з/являються в дослідах незакономірно, випадково, а причину і величину їх передбачити неможливо. Випадкові помилки викликані великою кількістю таких факторів, ефекти дії яких настільки незначні, що їх неможливо виділити і врахувати окремо, а в підсумку вони можуть давати досить велику помилку. Оцінкою впливу цієї групи помилок на точність результатів і займається теорія випадкових помилок. В ній передбачається, що виміри є однаково точними і рівноцінними, а повторення події багаторазовим. За цією теорією при неодноразовому вимірюванні величини підпорядковані статистичним закономірностям, які визначаються залежністю між значеннями цих помилок та імовірною частотою їх виникнення. Цю залежність називають законом розподілу помилок. Зауважимо, що найбільш часто для випадкових помилок використовують нормальний закон розподілу Гауса, за яким виникнення однакових за величиною додатних і від’ємних помилок є однаково ймовірним.
Фундаментальний
закон зростання
точності
при збільшенні кількості спостережень
стверджує, що помилка середнього з n
незалежних спостережень в
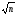 разів є меншою, ніж помилка поодинокого
виміру. Тобто при необхідності підвищення
точності виміру в 2 рази, треба провести
4 досліди замість одного; для підвищення
точності в 3 рази кількість вимірів
треба збільшити в 9 разів. Але при великих
значеннях випадкової помилки такий
прийом не завжди є ефективним, оскільки
може вимагати виконання сотень і тисяч
вимірів, що нереально. В таких випадках
більш доцільно радикально змінити
методику вимірів (дослідів) для зменшення
базового рівня випадкової помилки.
разів є меншою, ніж помилка поодинокого
виміру. Тобто при необхідності підвищення
точності виміру в 2 рази, треба провести
4 досліди замість одного; для підвищення
точності в 3 рази кількість вимірів
треба збільшити в 9 разів. Але при великих
значеннях випадкової помилки такий
прийом не завжди є ефективним, оскільки
може вимагати виконання сотень і тисяч
вимірів, що нереально. В таких випадках
більш доцільно радикально змінити
методику вимірів (дослідів) для зменшення
базового рівня випадкової помилки.
Звичайно результати спостережень утримують систематичну і випадкову помилки. Існують наступні практичні рекомендації:
а) якщо систематична помилка є визначальною, тобто її величина суттєво перебільшує величину випадкової помилки, то вимір достатньо виконати один раз;
б) якщо домінує випадкова помилка, то вимір треба виконати декілька разів.
Нагадаємо основні положення математичної статистики. Величина Х, яка в незмінних умовах досліду приймає одне або інше значення, заздалегідь невідоме, називають випадковою величиною. Якщо між будь – якими двома значеннями випадкової величини міститься лише кінцева кількість інших випадкових величин, то вона називається дискретною. Неперервні випадкові величини являють собою сукупність, яка щільно заповнює деякий проміжок.
Сукупність всіх можливих значень випадкової величини для всіх можливих умов досліду називають генеральною сукупністю. Сукупність обмеженого числа значень випадкової величини, яка отримана в конкретному досліді, називають вибіркою з генеральної сукупності.
Будь – яке співвідношення, яке встановлює зв’язок між можливими значеннями випадкової величини і відповідними їм імовірностями, називають законом розподілу. Кількісна оцінка властивостей генеральної сукупності здійснюється за допомогою функції розподілу, яка дорівнює імовірності прийняття випадковою величиною Х значення менш, ніж х : F(x) = P(X < x).
Похідну
цієї функції називають густиною
розподілу:
f(x) =
 .
.
Центр групування значень випадкової величини називають математичним очікуванням, яке визначається за формулами:
-
для неперервної величини М[X] =
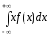 ;
; -
для дискретної величини М[X] =
 .
.
Дисперсія характеризує ступінь розсіювання випадкової величини навколо центру угрупування і визначається за формулами:
-
для неперервної величини D[x] =
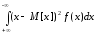 ;
; -
для дискретної величини D[x] =
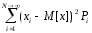 .
.
Величину, яка дорівнює квадратному кореню з дисперсії, називають середнім квадратичним відхиленням.
Характеристики розподілу, які отримані за даними вибірки, називають вибірковими оцінками. Вибіркові оцінки аN є випадкові величини і залежать від закону розподілу випадкових величин Х і кількості дослідів N. Вибіркова оцінка має практичну цінність, якщо вона характеризується незміщеністю, самостійністю та ефективністю.
Незміщеність означає, що при будь – якому N математичне очікування оцінки аN дорівнює істинному значенню параметра а: М[aN] = a.
Оцінка
аN
є самостійною,
якщо при необмеженому зростанні N її
значення з імовірністю одиниця
наближується до істинного значення
параметру a:
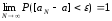 ,
де ε – будь – яке мале число.
,
де ε – будь – яке мале число.
Оцінку аN називають ефективною, якщо серед інших оцінок того ж параметра вона володіє найменшою дисперсією: D[aN] = Dmin .
Розглянемо закони розподілу випадкових величин, які найбільш часто використовуються в дослідженнях з застосуванням апарату математичної статистики. Як вже зазначалося, в дослідженнях оперують з емпіричними розподілами і однією з перших задач статистики є вибір теоретичної кривої, яка відповідає даному емпіричному закону розподілу. Методика такого вибору полягає в обробці результатів п вимірів випадкової величини х1, х2, х3, …, хп . Для цього величини хі групують за інтервалами, встановлюють для кожного з інтервалів частоту gi і будують ступінчасту гістограму gi = f(xi). Потім обчислюють характеристики дослідної кривої розподілу і вибирають вид розподілу шляхом порівняння з теоретичною кривою.
Нормальний закон розподілу Гауса застосовують , якщо значення випадкової величини є результатом дії численних незалежних і приблизно однаково малих факторів. Густина імовірності нормального розподілу:
f(x)
=
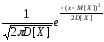 .
.
Числові
значення математичного очікування М[X]
та дисперсії D[X] повністю характеризують
генеральну сукупність нормального
розподілу випадкової величини. Характер
зміни густини цього розподілу (рис. 8)
показує, що функція f(x) досягає максимального
значення при х = М[X], тобто: f(x)max
=
 .
.
Таким чином, математичне очікування – це таке значення випадкової величини, при якому густина розподілу є максимальною. Слід зауважити, що переважна більшість параметрів процесів в техніці і технології мають розподіл, близький до нормального.
Біноміальний розподіл – це розподіл, в якому імовірність появи події залишається однією і тою ж для кожного окремого спостереження. Розподіл Пуасона використовують для аналізу рідкісних явищ. Експоненціальний закон розподілу використовують для аналізу надійності обладнання, якщо раптові його відмови виникають внаслідок пікових навантажень. Розподіл Вейбула використовується, наприклад, для оцінки надійності обладнання, відмови якого виникають внаслідок руйнування від втоми елементів та деталей агрегату. Гама – розподіл використовується в процесах з поступовим зниженням параметрів – погіршенням властивостей матеріалу в часі, деградацією обладнання, процесами старіння, зношування. Використовують і інші види розподілів - Пірсона, Шарльє, Гудрича, бета – розподіл і т. д.

Лише після визначення закону розподілу випадкової величини можна переходити до оцінки впливу її на об’єкт дослідження методами дисперсійного, кореляційного, регресивного аналізу, оскільки математичний апарат залежить від виду розподілу. Не можна, наприклад, до випадкової величини, яка підкорюється нормальному закону розподілу Гауса, застосовувати математичний апарат біноміального або експоненціального розподілу, або навпаки.
Розглянемо основні положення кореляційного аналізу.
Функцією розподілу системи двох випадкових величин (Х, У) називають функцію двох аргументів F(x, y), яка дорівнює імовірності сумісного виконання двох нерівностей: (Х < х); (У < у) або F(x, y) = P[(Х < х); (У < у)] .
Друга змішана часткова похідна функції F(x, y) за аргументами х та у називається густиною розподілу системи: f(x, y) = F//xy(x, y) .
Випадкові величини Х та У є незалежними, якщо закон розподілу кожної з них не залежить від того, яке значення приймає інша. В протилежному випадку вони є залежними.
Для
характеристики системи випадкових
величин, яка описує зв’язок між ними,
використовують кореляційний
момент. Для дискретних
випадкових величин він обчислюється
за формулою: Rxy
=
 (xi
– M[X]) (yj
– M[Y]) Pij
; для неперервних випадкових величин:
Rxy
=
(xi
– M[X]) (yj
– M[Y]) Pij
; для неперервних випадкових величин:
Rxy
=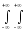 (x
– M[X]) (y – M[Y])f(x, y)dxdy.
(x
– M[X]) (y – M[Y])f(x, y)dxdy.
Характеристику
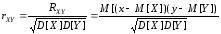 називають коефіцієнтом
кореляції величин Х та
У.
називають коефіцієнтом
кореляції величин Х та
У.
Коефіцієнт кореляції характеризує ступінь тісноти лінійного зв’язку між випадковими величинами і може змінюватися в межах [ - 1; + 1], тобто: 1 ≤ rxy ≤ + 1 .
Для незалежних величин він дорівнює нулю. Цю обставину завжди треба мати на увазі, бо для нелінійного зв’язку, навіть функціонального, висновки з кореляційного аналізу можна зробити абсурдні. Наприклад, для параболи другого порядку У = ± аХ2 коефіцієнт кореляції дорівнює нулю, але це зовсім не означає, що зв’язку між Х та У не існує.
Коефіцієнт кореляції є симетричним відносно досліджуваних випадкових величин, тобто rxy = rух . Якщо rxy > 0 , то величини Х і У з точністю до випадкових помилок одночасно зменшуються або зростають; якщо rxy < 0 , то ці величини одночасно змінюються в протилежних напрямках.