

2.3.3 Генерирование случайных воздействий
В процессе имитации функционирования сложных систем приходится моделировать различные случайные воздействия, которым всегда подвергается система в реальных условиях. Кроме того, процесс функционирования любой системы также носит случайный характер, и его имитация требует выработки большего числа случайных чисел. Алгоритмы формирования последовательностей случайных чисел, распределенных по некоторому закону, предполагают наличие базовой последовательности случайных чисел. В качестве такой принята последовательность случайных чисел, равномерно распределенных в интервале (0,1). Действуя на эту последовательность специально подобранными функциями, можно получить случайную величину с любым заданным законом распределения.
Как известно, плотность вероятности равномерно распределенной в интервале (0,1) случайной величины имеет следующий вид:
![]()
![]()
а функция распределения
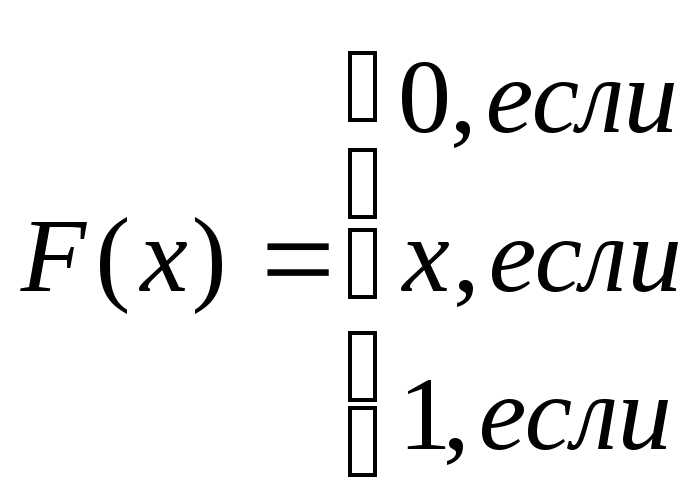
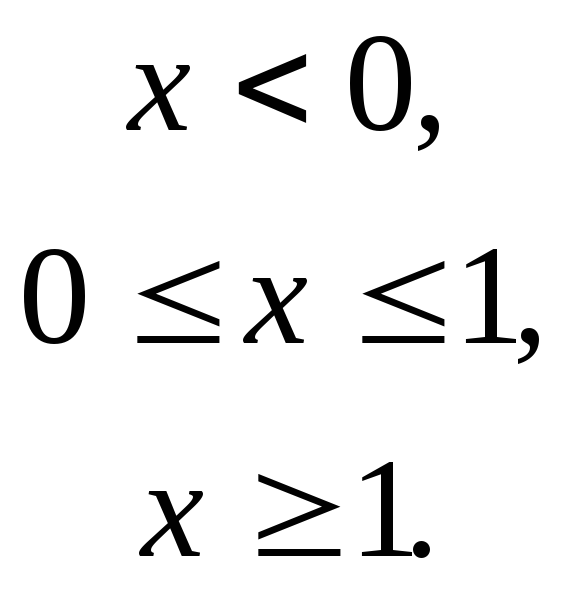
При этом математическое ожидание и дисперсия равны соответственно:
M[X]=1/2 , D[X]=1/12.
Идея формирования равномерно распределенной случайной величины заключается в следующем.
Пусть дискретная случайная величина Zi принимает только два значения 0 и 1 с равными вероятностями, т.е.
P(Zi =0)=P(Zi =1)=1/2.
Рассмотрим бесконечную последовательность Z1 ,..., Zn ,...таких величин, независимых между собой, и будем считать их двоичными знаками некоторого числа X, равного
![]()
Очевидно, что все значения X лежат в пределах 0x1.
При этом
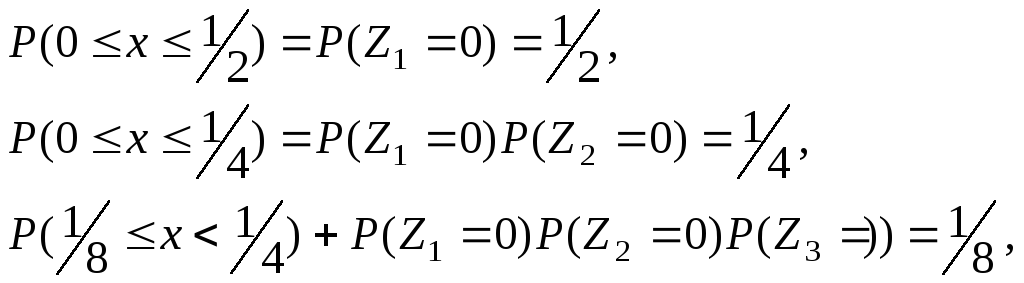
. . . . . . . . . . . . . . . . . . . . . . . . . . .
![]()
Следовательно, величина X равномерно распределена в (0,1). Таким образом, для формирования значений случайной величины, равномерно распределенной в (0,1), нужно сформировать бесконечную последовательность случайных чисел, с равной вероятностью принимающих значения 0 и 1, и считать их двоичными знаками дроби X, являющейся искомым значением.
В ЭВМ, где для записи числа предусмотрено не более k разрядов, нельзя записать бесконечную двоичную дробь. Поэтому каждое число X, представляемое в виде k- последовательности из 0 и 1, нельзя считать значением равномерно распределенной случайной величины. Это распределение называется квазиравномерным. Чем оно больше, тем точнее приближает равномерное распределение.
Существует два способа формирования случайных чисел на ЭВМ. Первый способ предполагает их выработку с помощью специальных электронных приставок, датчиков, связанных с ЭВМ. Вторым способом является генерирование чисел самой машиной специальным алгоритмом.
Программное генерирование случайных чисел. Известно множество методов машинной имитации равномерно распределенной случайной величины. Соответствующие программы-генераторы вычисляют так называемые псевдослучайные числа, которые, не являясь случайными, обладают статистическими свойствами случайных чисел, равномерно распределенных в интервале (0,1).
Последовательность чисел, полученная с помощью идеального генератора, должна состоять: 1) из равномерно распределенных, 2) статистически независимых, 3) воспроизводимых, 4) неповторяющихся чисел. Кроме того, идеальный генератор должен работать быстро и занимать минимальный объем машинной памяти.
Большинство алгоритмов, используемых на практике для получения псевдослучайных чисел, представляет собой рекуррентные формулы первого порядка:
![]() (2.3)
(2.3)
где начальное число X0 задано. Рекуррентный характер алгоритмов генерирования случайных чисел порождает при их реализации на ЭВМ периодические последовательности. Так как код любой ЭВМ содержит всегда конечное число разрядов, то в этом коде можно записать лишь конечное число N чисел, заключенных между 0 и 1. Поэтому рано или поздно некоторое значение XL совпадает с получением XR . Тогда исходя из формулы (2.3),
XR+i = XL+i (i=1,2,...). (2.4)
Если L – наименьшее число, удовлетворяющее условию (2.4) при некотором R (R<L), то множество чисел X0 ,X1 ,...,XL-1 называется отрезком апериодичности, L - длиной отрезка апериодичности, а P=L-R – периодом последовательности.
Так как одним из условий идеального генератора является неповторяемость чисел, то необходимо знать значения L и P для каждой последовательности и использовать для расчетов не более L чисел из нее.
Конгруэнтные методы генерирования случайных чисел. В настоящее время широкое распространение получили конгруэнтные методы генерирования псевдослучайных чисел, которые используют фундаментальное соотношение конгруэнтности, выражаемое следующей формулой:
![]() (2.5)
(2.5)
где
Xi
–i-ый
элемент последовательности; ,
,
m - неотрицательные целые числа. Выражение
![]() означает, что z есть остаток от деления
y на m. Два целых числа Xi+1
и Xi
конгруэнтны по модулю m (m – целое) тогда
и только тогда, когда существует такое
целое к, что Xi+1-
Xi =
, т.е., если разность Xi+1-
Xi
делится на m и если числа Xi+1
и Xi
дают одинаковые остатки от деления на
m.
означает, что z есть остаток от деления
y на m. Два целых числа Xi+1
и Xi
конгруэнтны по модулю m (m – целое) тогда
и только тогда, когда существует такое
целое к, что Xi+1-
Xi =
, т.е., если разность Xi+1-
Xi
делится на m и если числа Xi+1
и Xi
дают одинаковые остатки от деления на
m.
Если задано начальное значение X0 , множитель и аддитивная константа , то по формуле (2.5) можно определить последовательность целых чисел { X1 ,X2 ,...,Xi ... }, равномерно распределенных в интервале (0,m). Поделив все числа на m, легко получить последовательность псевдослучайных чисел с равномерным в (0,1) распределением.
Существуют различные конгруэнтные преобразования, которые можно разделить на три группы: 1) мультипликативные, 2) аддитивные, 3) смешанные. Каждый тип преобразования определяет способ генерирования псевдослучайных чисел.
Мультипликативный метод.
Мультипликативный конгруэнтный алгоритм задает последовательность неотрицательных целых чисел { Xi }, не превосходящих m, по формуле
![]() (2.6)
(2.6)
представляющей собой частный случай формулы (2.5) при =0. Последовательность, полученная по этому методу, обладает достаточно хорошими статистическими характеристиками. Выбирая параметры и X0, с его помощью можно получить последовательность равномерно распределенных некоррелированных псевдослучайных чисел. Более того, при выполнении определенных условий, накладываемых на эти параметры, генерируемая мультипликативная последовательность обладает максимальным при данном модуле m периодом.
Мультипликативный алгоритм требует минимального объема машинной памяти, и с вычислительной точки зрения сводится к подсчету произведения двух целых чисел - операции, которая очень быстро выполняется современными ЭВМ.
Для
численной реализации наиболее удобна
версия алгоритма, в которой модуль m
равен
![]() ,
где p - основание системы счисления,
используемой в ЭВМ, а l
- длина машинного слова.
,
где p - основание системы счисления,
используемой в ЭВМ, а l
- длина машинного слова.
Выбор m=pl удобен по двум причинам. Во-первых, вычисление остатка от деления на m сводится к выделению l младших разрядов делимого. Во-вторых, преобразование целого числа Xi в рациональную дробь из интервала (0,1) осуществляется подстановкой слева от него двоичной или десятичной запятой. Таким образом, специальный выбор числа m позволяет исключить из процесса счета две операции деления.
Для ЭВМ с p=2 (внутренний алфавит – двоичный) формулу (2.6) удобнее представить в следующем виде:
![]()
где d – число десятичных цифр в машинном слове. Алгоритм построения последовательности будет иметь вид:
-
Выбрать в качестве X0 любое нечетное.
-
Вычислить
 по формуле
по формуле
![]() ,
,
где t - любое целое положительное число.
-
Вычислить произведение X0 содержащее не более 2d значащих разрядов.
-
Взять d младших разрядов полученного числа в качестве X1 , остальные отбросить.
-
Поставить десятичную запятую слева от найденного числа Xi . Полученную дробь считать за Xi , то есть
![]()
-
Принять X0= X1.
-
Вернуться к п.3.
Пример.
Пусть d=4. Мультипликативный генератор определит в этом случае p=5*24-2=200 различных чисел.
-
Возьмем n0 =5379.
-
Для t=0 и z=91 можно взять =91. Пусть =91.
-
n0 =91*5379=00489489. Отсюда n1 =9489, x1 =0,9489.
-
n1 =91*9489=00863499. Отсюда n2 =3499, x2 =0,3499.
-
n2 =91*3499=00318409. Отсюда n3 =8409, x3 =0,8409 и тек далее.
(n4 =5219,n5 =4929,n6 =8539,...).
Из примера видно, что младшие разряды полученных чисел не напоминают случайные. Мультипликативная процедура обеспечивает полный период высшему разряду генерируемых значений, и с понижением порядка период уменьшается. Таким образом, если эксперимент позволяет ограничиться выборкой, состоящей из чисел, включающих меньше значащих цифр, чем укладывается в машинное слово, надо использовать высшие порядки чисел мультипликативного генератора.
Аддитивный метод.
Аддитивный конгруэнтный алгоритм базируется на следующей формуле:
Xi=( Xi-1+ Xi-k)(modm)
Аддитивные
методы используются редко, и характеристики
получаемых последовательностей изучены
слабо. Модуль m выбирается так же, как
и в мультипликативных методах. Период
последовательности, получаемый аддитивным
алгоритмом, равен
![]() ,
где pk
- постоянная величина, зависящая от k и
p. Например, при l=35, p=2, pk
=255, k=16 период равен 255*234
.
,
где pk
- постоянная величина, зависящая от k и
p. Например, при l=35, p=2, pk
=255, k=16 период равен 255*234
.
Смешанный метод
Смешанная конгруэнтная процедура вычисляет последовательность неотрицательных целых чисел {Xi}, не превосходящих заданную величину m, по формуле (2.5).
В отличие от мультипликативного метода здесь 0. Преимущество смешанной процедуры в том, что при данном m можно подобрать параметры и , для которых по формуле (2.5) получается последовательность чисел, с малой степенью корреляции. С вычислительной точки зрения смешанный метод сложнее мультипликативного на одну дополнительную операцию сложения.
Комбинационный метод
Конгруэнтные методы не всегда дают статистически удовлетворительные последовательности. Элементы получаемых последовательностей часто являлись статистически зависимы. Поэтому возникли новые разновидности конгруэнтных алгоритмов, названы комбинационными методами, объединяющими два или более конгруэнтных алгоритма.
Комбинация алгоритмов может быть проведена, например, следующим образом. С помощью мультипликативного алгоритма вычисляется последовательность из p чисел. Затем с помощью смешанного алгоритма формируется целое число i из интервала (0,p). Из набора псевдослучайных чисел извлекается число с номером i, и процедура повторяется дальше. Этот комбинационный метод успешно выдержал все проверки, но он является сравнительно сложным, и из двух генерируемых последовательностей в конечном счете используется только одна.
На практике обычно используется мультипликативный конгруэнтный алгоритм, параметры которого выбираются в соответствии с рядом дополнительных условий, уменьшающих автокорреляцию чисел.
2.3.4 Проверка качества генерируемых последовательностей
Качество генерируемых последовательностей определяется их статистическими свойствами, а именно случайностью получаемых чисел, их равномерной распределенностью в интервале (0,1) и независимостью. Поэтому все последовательности псевдослучайных чисел, полученные с программ-генераторов, должны быть проверены с помощью специальных тестов на случайность, равномерность и некоррелированность. В основе многих тестов проверки качества получаемых последовательностей лежит критерий 2 Пирсона, позволяющий проверить соответствие эмпирического распределения случайной величины X и предполагаемого теоретического. Схема применения критерия следующая. Выборка объема n из значений случайной величины X разбивается на интервалов одинаковой длительности. Затем определяются значения ni - количество попаданий величины X в i-ый из разрядов. С помощью таблиц вычисляется значение pi теоретической вероятности попадания случайной величины в i-ый интервал. Далее подсчитывается наблюдаемое значение критерия по формуле:
![]() ,
,
Известно, что случайная величина 2 распределена по закону 2 с числом степеней свободы k, где - число разрядов выборки, а k -число неизвестных параметров предполагаемого распределения. Критическая область для критерия – правосторонняя. Критическая точка 2кр определяется из таблиц 2 - распределения по уровню значимости и числу степеней свободы исходя из условия
P(2 >2кр )=.
Если
![]() >2кр
, то гипотеза о соответствии распределений
отвергается. Если
>2кр
, то гипотеза о соответствии распределений
отвергается. Если
![]() <2кр
, то она не противоречит опытным данным.
<2кр
, то она не противоречит опытным данным.
Проверка случайности. Для того, чтобы проверить, насколько хорошо генерируемая последовательность имитирует последовательность случайных чисел, наиболее часто используется тест серий. С его помощью проверяется один из разрядов (обычно старший) чисел полученной последовательности. При более тщательной проверке исследуются независимо друг от друга несколько старших разрядов.
Пусть получена последовательность x1 ,..., xn псевдослучайных чисел из интервала (0,1). Обозначим символами 1 ,..., n цифры старшего разряда чисел последовательности. Цифры k+1,...,k+ образуют серию длины , если k+1 =k+2 =...= k+.k++1 . Количество серий длины во всей последовательности обозначим K (=1,n), а общее число серий
![]() .
.
Известно, что длина последовательности подчинена биномиальному закону. Для того, чтобы установить случайность последовательности, нужно проверить гипотезу о законе распределения с помощью одного из критериев (тестов) согласия, например 2.
Критерий 2 в данном случае имеет следующий вид:
![]() .
.
При этом
p=P(k+1 =k+2 =...= k+.k++1)=9*10- .
Так как, начиная с некоторой длины m серии с длиной, большей m, встречаются мало, то все серии длины m+1 объединяют в одну группу. Число серий этой группы обозначим Km+1 . Получено pm+1=10-m , а критерий 2 принимает вид:
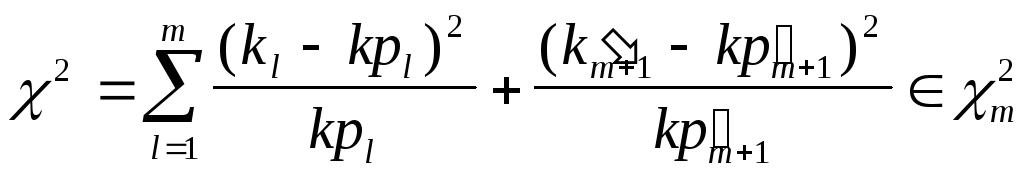 .
.
Проверка
равномерности. Для
проверки гипотезы о равномерности
распределения псевдослучайных чисел
в интервале (0,1) обычно используется так
называемый частотный тест. При этом
гипотеза равномерности проверяется
критерием
![]() .
Интервал (0,1) разбивается на m
равных интервалов. Далее определяется
количество чисел
.
Интервал (0,1) разбивается на m
равных интервалов. Далее определяется
количество чисел
![]() , попавших в i
-ыи интервал. Так как предполагаемое
распределение равномерно, т.е. теоретические
вероятности
, попавших в i
-ыи интервал. Так как предполагаемое
распределение равномерно, т.е. теоретические
вероятности
![]() попадания в i-
ый интервал равны
попадания в i-
ый интервал равны
![]() , критерий
, критерий
![]() можно записать в следующем виде:
можно записать в следующем виде:
![]() .
.
Здесь n -число элементов исследуемой последовательности.
Проверка независимости. Для практического использования псевдослучайных чисел вполне достаточно их некоррелированности. Некоррелированность случайных чисел можно проверить с помощью коэффициента корреляции:
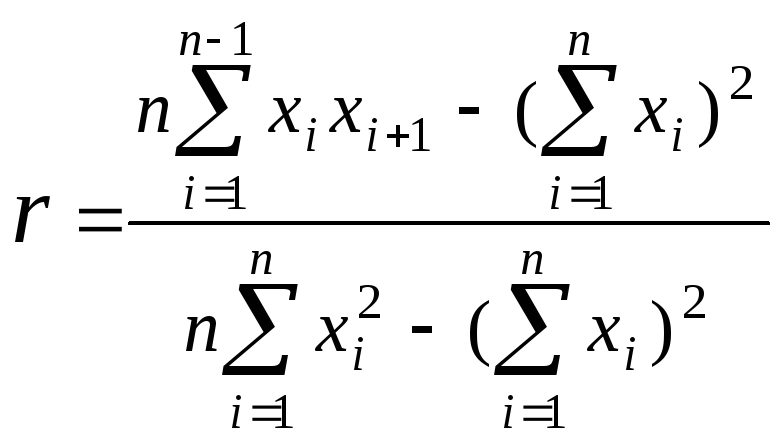 .
.
Если
полученное число
![]() близко к 0, то элементы последовательности
считаются некоррелированными.
близко к 0, то элементы последовательности
считаются некоррелированными.
Например, если
![]() ,
,
то можно считать, что генератор выдержал тест.
2.3.5. Имитация случайных событий
Если
требуется имитация случайного события
А ,
наступающего с вероятностью p,
то очевидно, что Р(А)
совпадает с вероятностью
![]() ,
где
,
где
![]() -
случайное число из равномерной в
интервале (0,1) последовательности:
-
случайное число из равномерной в
интервале (0,1) последовательности:
![]() .
.
Это следует из того, что функция распределения равномерной в (0,1) величины Х есть
![]()
![]() .
.
Следовательно,
событию
![]() соответствует событие
соответствует событие
![]() в том смысле, что
в том смысле, что
![]() .
.
Отсюда
легко видна схема имитации случайного
события. Сначала генерируется
псевдослучайное число
![]() ,
для которого проверяется выполнение
неравенства
,
для которого проверяется выполнение
неравенства
![]() .
Если неравенство выполняется, то
считается, что событие А
наступило, в противном случае – нет.
Такая схема имитации называется имитацией
по жребию.
.
Если неравенство выполняется, то
считается, что событие А
наступило, в противном случае – нет.
Такая схема имитации называется имитацией
по жребию.
Эта
схема может быть обобщена на группу
событий. Пусть требуется смоделировать
полную группу попарно несовместных
событий
![]() ,
вероятности которых
,
вероятности которых
![]() ,
где
,
где
![]()
![]() .
Очевидно, что событие
.
Очевидно, что событие
![]() можно определить как
выполнение двойного неравенства
можно определить как
выполнение двойного неравенства
![]() ,
,
так как тогда
![]() .
.
Имитируя
полную группу, мы считаем события
![]() несовместными. Рассмотрим теперь способ
имитации совместных событий, независимых
и зависимых.
несовместными. Рассмотрим теперь способ
имитации совместных событий, независимых
и зависимых.
Допустим,
требуется имитация двух независимых
совместных событий
![]() с вероятностями соответственно
с вероятностями соответственно
![]() и
и
![]() .
Здесь возможны два подхода. В первом
имитируются два псевдослучайных числа
.
Здесь возможны два подхода. В первом
имитируются два псевдослучайных числа
![]() и
и
![]() ,
с помощью которых независимо друг от
друга имитируются два события
,
с помощью которых независимо друг от
друга имитируются два события
![]() (по
(по
![]() )
и
)
и
![]() (с
помощью
(с
помощью
![]() ).
Тогда, если
).
Тогда, если
![]() ,
то произошло
,
то произошло![]() ,
если еще
,
если еще
![]() ,
то и
,
то и
![]() ;
если
;
если
![]() но,
но,
![]() ,
то
,
то
![]() ;
если
;
если
![]() ,
но
,
но
![]() ,
то
,
то
![]() ;
если
;
если
![]() ,
,
![]() ,
то
,
то
![]() .
.
Второй
путь предполагает имитацию по ранее
приведенной схеме группы попарно
несовместных событий
![]() ,
,
![]() ,
,
![]() ,
,
![]() с вероятностями соответственно
с вероятностями соответственно
![]() ,
,
![]() ,
,
![]() ,
,
![]() .
.
Аналогичный
подход используется в
случае, когда
совместные события
![]() и
и
![]() являются зависимыми. В этом случае для
их имитации должны быть заданы три
вероятности:
являются зависимыми. В этом случае для
их имитации должны быть заданы три
вероятности:
![]() ,
,
![]() и
и
![]() .
Еще одна вероятность
.
Еще одна вероятность
![]() вычисляется с помощью формулы полной
вероятности:
вычисляется с помощью формулы полной
вероятности:
![]() ,
,
откуда
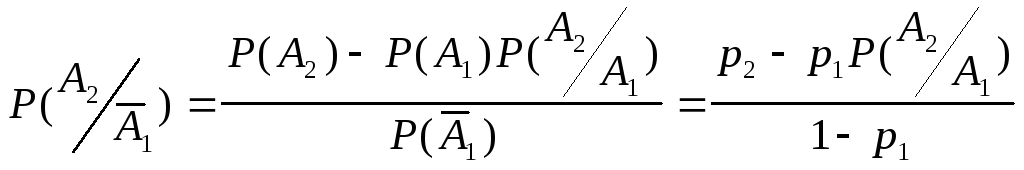 .
.
При
имитации зависимых совместных событий
![]() и
и
![]() тоже существует два подхода. В первом
случае генерируются два псевдослучайных
числа
тоже существует два подхода. В первом
случае генерируются два псевдослучайных
числа
![]() и
и
![]() и имитируются события
и имитируются события
![]() (по
(по
![]() )
и
)
и
![]() (по
(по
![]() ).
).
Второй
вариант решения предполагает имитацию
полной группы попарно несовместных
событий
![]() ,
,
![]() ,
,
![]() ,
,
![]() .
.
Первый вариант опять предполагает меньшее число сравнений и в этом смысле является более экономичным.
2.3.6 Имитация случайных величин
Для имитации случайные величины должны быть заданы в виде своих распределений: случайная дискретная величина – ряд или функция распределения, непрерывная – функция распределения или плотность вероятности. При этом предполагается, что область определения случайной величины конечна, в противном случае для нее должно быть построено усеченное распределение, с помощью которого производится имитация. Усечение производится следующим образом.
Если
Y есть
дискретная случайная величина, заданная
распределением вида
![]() ,
то соответствующее усеченное распределение
примет вид:
,
то соответствующее усеченное распределение
примет вид:
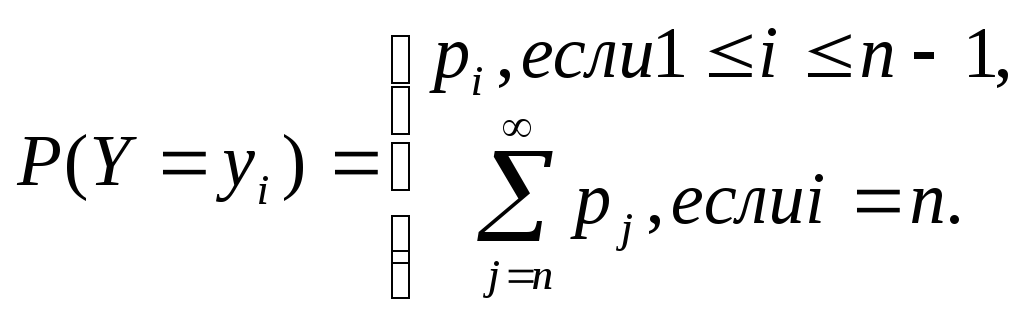
Если
Y -
непрерывная случайная величина с
плотностью
![]() ,
где
,
где
![]() ,
то плотность вероятности соответствующего
усеченного распределения имеет вид:
,
то плотность вероятности соответствующего
усеченного распределения имеет вид:
![]()
![]() ,
,
где
![]() .
.
Имитация дискретных случайных величин, заданных рядом распределения. Имитация дискретных случайных величин производится по аналогии с имитацией событий. Допустим, что нужно смоделировать случайную величину Y, заданную следующим рядом распределения:
![]()
![]() .
.
Определяется
событие
![]()
![]() .
.
Очевидно,
что события
![]() ,…,
,…,![]() образуют полную группу попарно
несовместных событий. Отсюда следует
способ имитации дискретной случайной
величины, заданной рядом распределения.
образуют полную группу попарно
несовместных событий. Отсюда следует
способ имитации дискретной случайной
величины, заданной рядом распределения.
Для
имитации двух дискретных случайных
величин
![]() и
и
![]() с заданными распределениями можно
использовать процедуры имитации
совместных зависимых и независимых
событий.
с заданными распределениями можно
использовать процедуры имитации
совместных зависимых и независимых
событий.
Имитация случайных величин, заданных функцией распределения. Имитация случайных величин, заданных функцией распределения, может быть выполнена с помощью точных или приближенных методов. Из точных методов наиболее распространен метод обратной функции, который базируется на следующей теореме.
Теорема 1
Пусть
![]() – функция распределения некоторой
случайной величины, а X
– случайная величина, равномерно
распределенная в (0,1). Тогда случайная
величина, определенная соотношением
– функция распределения некоторой
случайной величины, а X
– случайная величина, равномерно
распределенная в (0,1). Тогда случайная
величина, определенная соотношением
![]() ,
где
,
где
![]() - функция, обратная
- функция, обратная
![]() ,
имеет функцию распределения
,
имеет функцию распределения
![]() .
.
Из теоремы 1 вытекает следующий способ преобразования случайных чисел с равномерным в интервале (0,1) распределением в последовательность случайных чисел с функцией распределения F(y). Для получения значения у случайной величины , функция распределения которой F(y), нужно из последовательности псевдослучайных чисел выбрать одно x и разрешить относительно у уравнение
![]() .
(2.7)
.
(2.7)
Полученное решение и есть искомое число.
Примеры.
1. Имитация экспоненциальной случайной величины
Плотность вероятности
![]()
![]()
Функция распределения
![]()
![]() .
.
Тогда уравнение (2.7) запишется в виде
![]() ,
,
откуда
![]() .
.
Если x распределено равномерна в интервале (0,1), то 1-x тоже имеет равномерное в (0,1) распределение, т.е. можно записать
![]() .
.
2. Имитация случайной величины, распределенной по закону Паскаля
Функция распределения случайной дискретной величины, распределенной по закону Паскаля, имеет вид
![]()
![]() .
.
Значениями величины y являются 0,1,2,...
Очевидно, что решение уравнения (2.7) запишется так:
![]() .
.
Так как у должно быть целым, считаем
![]() .
.
Имитация непрерывной случайной величины, методом Неймана (исключения). Метод Неймана состоит в том, что из равномерно распределенной последовательности отбираются случайные числа, удовлетворяющие некоторому условию таким образом, чтобы отобранные числа имели заданный закон распределения.
Теорема 2
Случайная
величина
![]() имеет плотность вероятности g(x),
если
имеет плотность вероятности g(x),
если
![]() .
.
Метод Неймана, базирующийся на теореме 2, формулируется следующим образом:
-
из исходной совокупности псевдослучайных чисел выбираются пары
![]() ;
;
-
для этих чисел проверяется справедливость условия
![]() ;
(2.8)
;
(2.8)
-
если неравенство (2.8) выполняется, то очередное значение случайной величины Y, имеющей плотность распределения f(y), получено:
![]() .
.
Методом
Неймана целесообразно пользоваться,
если f(y)=0,
когда
![]() и легко подсчитывается на
и легко подсчитывается на
![]() .
Недостатком метода является то, что он
приводит в среднем к
.
Недостатком метода является то, что он
приводит в среднем к
![]() отброшенным точкам.
отброшенным точкам.
Пример.
Требуется получить случайные числа, распределенные с плотностью вероятности следующего вида:
![]()
![]() .
.
При
этом
![]() .
.
Условие (2.8) имеет вид
![]() .
.
и при этом
![]() .
.
Имитация
нормального распределения. На
основе центральной предельной теоремы
можно построить алгоритм имитации
нормальной случайной величины с
математическим ожиданием a
и дисперсией
![]() .
Для этого достаточно просуммировать M
равномерно распределенных случайных
чисел. Процедура получается особенно
простой, если в качестве М
взять число 12. При этом, суммируя 12
псевдослучайных чисел, в соответствии
с центральной предельной теоремой
получаем нормально распределенную
случайную величину z
с параметрами
.
Для этого достаточно просуммировать M
равномерно распределенных случайных
чисел. Процедура получается особенно
простой, если в качестве М
взять число 12. При этом, суммируя 12
псевдослучайных чисел, в соответствии
с центральной предельной теоремой
получаем нормально распределенную
случайную величину z
с параметрами
![]() .
Преобразуя z
следующим образом:
.
Преобразуя z
следующим образом:
![]() ,
,
мы
получаем искомую величину
Y с
математическим ожиданием
a и
дисперсией
![]() .
.
Имитация
распределения Эрланга
![]() порядка
(
порядка
(![]() -распределение).
Плотность вероятности
-распределение).
Плотность вероятности
![]() – распределения имеет вид
– распределения имеет вид
![]() .
.
Распределение
Эрланга – это распределение суммы К
независимых случайных величин, каждая
из которых распределена по экспоненциальное
закону с параметром
![]() .
Так как методом обратной функции
экспоненциальную случайную величину
можно имитировать с помощью выражения
.
Так как методом обратной функции
экспоненциальную случайную величину
можно имитировать с помощью выражения
![]() ,
,
то случайную величину, распределенную по закону Эрланга, можно получить, вычисляя выражение
![]() .
.
Распределения
![]() имитируются с помощью процедуры имитации
нормальной случайной величины. Известно,
что если
имитируются с помощью процедуры имитации
нормальной случайной величины. Известно,
что если
![]() и взаимно независимы,
то
и взаимно независимы,
то
![]() ,
т.е. для имитации
распределения
,
т.е. для имитации
распределения
![]() достаточно просуммировать квадраты
нормальных величин.
достаточно просуммировать квадраты
нормальных величин.
Если
![]() ,
а
,
а
![]() ,
и Y не
зависит от Z,
то
,
и Y не
зависит от Z,
то
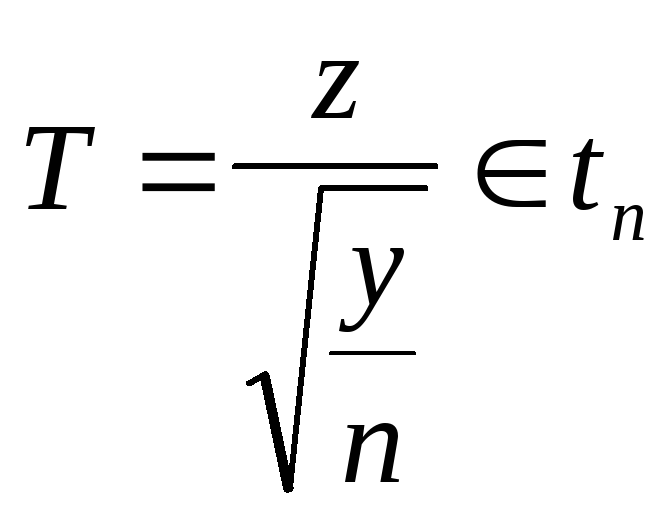 .
.
Наконец,
если
![]() и
Z и
Y
независимы, то
и
Z и
Y
независимы, то
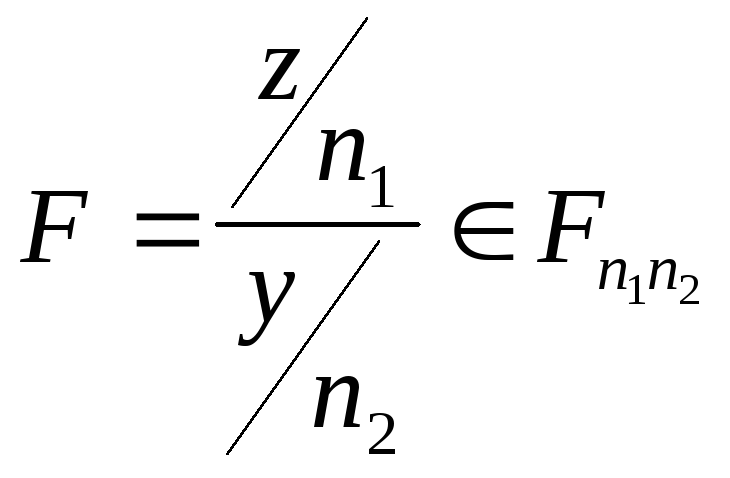 .
.
Имитация
случайных потоков. Как
правило, потоки событий имитируются с
использованием распределений случайного
времени между двумя соседними событиями.
Если рассматриваемый поток является
стационарным и известна плотность или
функция распределения времени между
событиями, то методами имитации случайных
величин вычисляются значения
![]() случайного времени между событиями.
Тогда момент наступления i-го
события вычисляется по формуле
случайного времени между событиями.
Тогда момент наступления i-го
события вычисляется по формуле
![]()
![]() .
.
При
этом
![]() должно быть задано. Если поток является
нестационарным, то для формирования
каждого
должно быть задано. Если поток является
нестационарным, то для формирования
каждого
![]() используется свой закон распределения.
используется свой закон распределения.
Если
поток событий является многомерным, то
процедура имитации осуществляется
методами имитации случайных векторов.
При этом, получив случайный вектор
![]() и определив моменты наступления событий
и определив моменты наступления событий
![]()
![]() ,
,
следует упорядочить события потока по времени наступления.
Если
многомерный поток является стационарным
и ординарным с .многомерной плотностью
![]() ,
то его можно имитировать следующим
образом. Моделируется одновременный
поток событий с плотностью
,
то его можно имитировать следующим
образом. Моделируется одновременный
поток событий с плотностью
![]() принадлежность события i-й
составляющей потока определяется
по жребию с вероятностью
принадлежность события i-й
составляющей потока определяется
по жребию с вероятностью
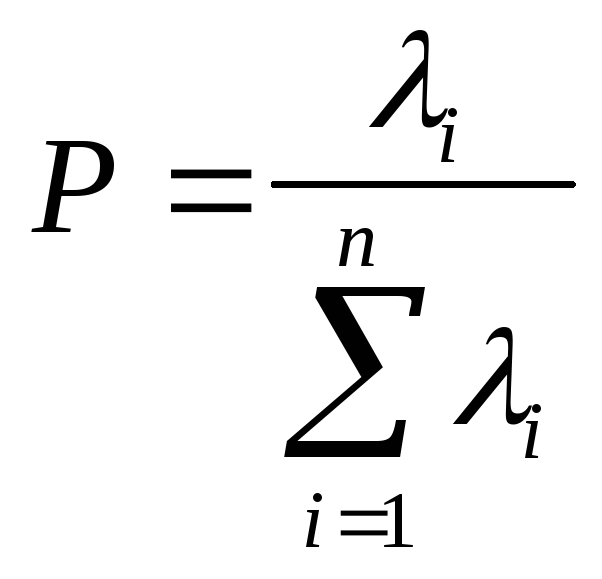 .
.
При
этом
![]() есть величина, обратная среднему времени
между заявками.
есть величина, обратная среднему времени
между заявками.