

Перший кластер Другий кластер
Рис. 2.5. Об’єднання двох кластерів за методом середнього зв’язку
На другому етапі буде використаний один із ітеративних методів. Особливість більшості ітеративних методів полягає в тому, що формується наперед задана кількість кластерів. Саме в цьому і криється основний недолік ітеративних методів. Оскільки необхідно визначити оптимальну кількість кластерів та кроків, які задаються дослідником, то доцільно насамперед провести класифікацію, застосовуючи один із агломеративних методів і саме за результатами даного методу визначити кількість кластерів, необхідних для застосування ітеративного методу.
До групи ітеративних методів еталонного типу належить метод k-середніх, який не вимагає розрахунку матриць подібності. Алгоритм цього методу, як уже зазначалось, вимагає задати кількість кластерів, на які розбивається сукупність, тобто на першому кроці задається початкова розбивка об’єктів і визначаються центри ваги кластерів, так звані еталони. Потім за мірою подібності один із об’єктів входить у кластер, і центр ваги перераховується з урахуванням координат нового об’єкта. Процедура повторюється до повного групування об’єктів у кластерах. Кінцеве групування має центр тяжіння, який не збігається з еталонним. Внутрішня дисперсія в кластерах, що утворились за допомогою цього методу, є мінімальною.
Для визначення критерію якості класифікації використовують функціонали. Найкращим за вибраним функціоналом вважається групування, за умов якого досягається екстремальне (мінімальне чи максимальне) значення цільової функції – функціонала якості [134, 498]. Використовують такі функціонали якості: сума квадратів відстаней до центрів класів, сума внутрішньокласових відстаней між об’єктами, сумарна внутрішньокласова дисперсія, середня міжкласова відстань тощо. Найбільш поширеним функціоналом є сума квадратів відстаней до центрів класів, який розраховується за формулою
![]() , (12)
, (12)
де l – номер кластера (l = 1,2,..., k),
![]() -
центр l-го кластера,
-
центр l-го кластера,
Yi – вектор значень змінних для і-го об’єкта, який входить у l-й кластер,
d(Yi,
![]() )
– відстань між і-м об’єктом і центром
l-го кластера.
)
– відстань між і-м об’єктом і центром
l-го кластера.
Застосовуючи даний критерій, намагаються отримати таке групування сукупності об’єктів на k кластерів, за якого значення F1 було б мінімальним.
Отже, доцільність застосування кластерного аналізу полягає в його здатності використовувати велику кількість ознак для порівняння об’єктів між собою. Саме тому його було обрано для уточнення оцінки рівня ризику підприємств. Для порівняння економічного ризику підприємств були використані такі показники: коефіцієнт варіації доходів підприємств (CV); показники оцінки ризику банкрутства – Z та R, які водночас є інтегральними фінансовими показниками. Ці показники розраховані за квартальними фінансовими звітами та наведені на рис. 2.6 та додатку Е для таких промислових підприємств (цукрових заводів): ВАТ “Томашпільський цукровий завод” (I_7), ВАТ “Смілянський цукровий завод” (I_2), ВАТ “Бродецький цукровий завод” (I_8), ВАТ “Лохвицький цукровий завод” (I_5), ВАТ “Волочиський цукровий завод” (I_1), ВАТ “Яреськівський цукровий завод” (I_3), ВАТ “Гілея” (I_6), ВАТ “Іванопільський цукровий завод” (I_4). Слід зазначити, що мінімального рівня економічного ризику досягатиме підприємство за умови, коли значення показника CV буде якнайменше, тоді як значення показників Z та R повинні бути якнайбільшими.
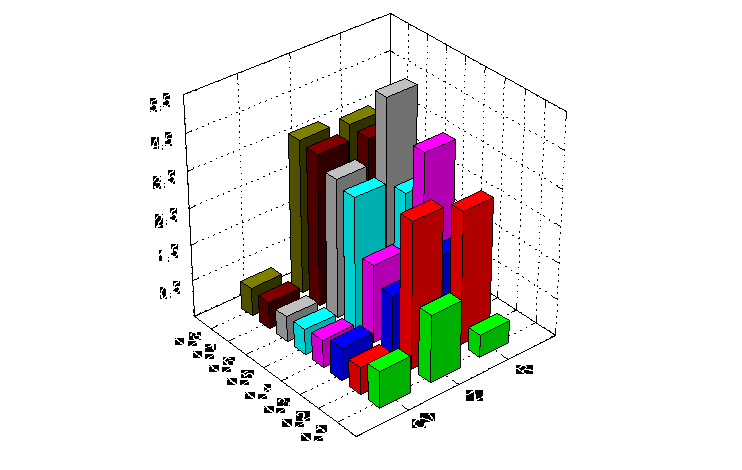
Рис. 2.6. Показники-індикатори економічного ризику підприємств
Кластерний аналіз проведений у два етапи (рис. 2.7) згідно пропозиції викладеною в праці. Спочатку було застосовано ієрархічний агломеративний метод, а саме метод середнього зв’язку, за допомогою якого встановлено кількість кластерів, на які розбито початкову сукупність.
 Зворотний
Зворотний
зв’язок
Так
Ні
Рис. 2.7. Процес кількісного аналізу економічного ризику з використанням методу кластерного аналізу
РОЗДІЛ 3