

Деревья
Дерево – одна из наиболее распространённых структур данных, используемых в программировании. Формально дерево определяется рекурсивно следующим образом: это конечное множество Т, состоящее из одного или более узлов таких, что:
-
Имеется один узел, называемый корнем дерева.
-
Остальные узлы, исключая корень, содержатся в m≥0 попарно непересекающихся множествах Т1, Т2,….Тm, каждое из которых в свою очередь является деревом. При этом деревья Т1, Т2,….Тm называются поддеревьями (потомками) данного корня.
Поддеревья некоторой вершины еще иногда называют кустами, а конечные вершины дерева из которых больше не выходит ни одной связи (т.е. для такого узла m=0), называют листьями.
Наиболее распространены в программировании бинарные (двоичные) деревья, в которых каждый узел может иметь не более двух потомков. Рекурсивное определение бинарного дерева задает его как корень и два бинарных поддерева: левое и правое, – причем любое из них может быть пустым. Бинарные деревья используются как структура данных в том случае, когда в каждой точке процесса должно быть принято одно из двух возможных решений. Например, они применяются для синтаксического анализа, поиска, сортировки, управления базами данных и в других приложениях.
Пример 37. Приведем пример бинарного дерева (рис.44), которое может использоваться для вычисления алгебраического выражения (A*B+C*D)/(B*C), если двигаться от листьев дерева к корню.
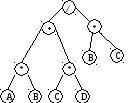
Рис.44.
Пример бинарного дерева
Бинарные деревья наиболее часто используются в программировании. Это основывается на том факте, что любое дерево может быть приведено к бинарному. Основное правило такого преобразования: левая ветвь каждого узла соединяет его с первым узлом следующего уровня, а правая – с другими узлами следующего уровня (братьями). Рис.45 демонстрирует первый шаг преобразования дерева A к его бинарному представлению. На втором шаге тоже самое делается с поддеревом B и т.д.
|
|
|
|
Рис.45. Шаг преобразования дерева к бинарному |
|


Бинарное дерево на языке Си может быть описано следующими структурами данных:
struct tree
{
Int info; //информационное поле
tree ltree,rtree; //указатели на левое и правое поддерево
}
К бинарным деревьям применяют следующие типовые операции:
-
Создание нового бинарного дерева, состоящего из одного узла с информационным полем .
-
Создание нового левого или правого «сына» (узла) для текущего узла.
-
Чтение информационного содержимого узла.
-
Определение указателя на левое или правое поддерево.
-
Удаление куста или листа дерева.
-
Удаление левого или правого поддерева для узла.
-
Обход дерева.
-
Сравнение деревьев.
-
Соединение деревьев.
Пример 40. Рассмотрим реализацию основных процедур и функции для работы с деревьями.
tree MakeTree(tree node, int x)
{
if(node.value == NULL)
{
tree* p = new tree;
p->value = x;
node = *p;
}
else
{
if((node).value > x) MakeTree(*node.pleft, x);
else MakeTree(*node.pright, x);
}
return node;
}
void SetLeft (tree *p,int x) // создание левого сына для узла с указателем p
{
*p->ltree = NewNode(x);
}
void SetRight(tree *p,int x) // создание правого сына для узла с указателем p
{
*p->rtree = NewNode(x);
}
int GetInfo (tree *p) // чтение значения информационного поля узла p
{
if (p != NULL) return p->info;
else return(0);
}
tree GetLeftTree (tree *p) // выдать значение указателя на левое поддерево
// узла p
{
if (p != NULL) return *p->ltree;
//else return(NULL);
}
tree GetRightTree (tree *p) //выдать значение указателя на правое поддерево
// узла p
{
if (p != NULL) return *p->ltree;
// else return (tree)NULL;
}
void DelLeaf (tree *p) // Удалить в дереве «лист»
{
if (p != NULL) free(p);
}
Рассмотрим более подробно задачу обхода дерева. Обход дерева – это последовательный обход всех узлов дерева. Фактически во время обхода нужно составить список всех узлов дерева. Поскольку дерево по определению является рекурсивной структурой данных, то и обход дерева как правило осуществляется рекурсивно. Существует три способа рекурсивного обхода бинарного дерева: обход с префиксным порядком; обход с инфиксным порядком; обход с суффиксным (или постфиксным) порядком.
Префиксный порядок обхода дерева определяется в виде списка узлов следующим образом:
Если дерево не пусто, то префиксный порядок это:
-
Корень дерева.
-
Узлы левого поддерева в префиксном порядке.
-
Узлы правого поддерева в префиксном порядке.
Например, пусть дано дерево, указанное вна рис. примере 48, тогда префиксный обход дерева это следующая последовательность узлов: /+*AB*CD*BC. Иногда префиксный порядок называют обходом дерева сверху вниз.
Инфиксный порядок обхода дерева определяется в виде списка узлов следующим образом:
Если дерево не пусто, то инфиксный порядок это:
-
Узлы левого поддерева в инфиксном порядке.
-
Корень дерева.
-
Узлы правого поддерева в инфиксном порядке.
Для нашего примера это будет: A*B+C*D/B*C
Суффиксный порядок обхода дерева определяется в виде списка узлов следующим образом:
Если дерево не пусто, то суффиксный порядок это:
-
Узлы левого поддерева в суффиксном порядке.
-
Узлы правого поддерева в суффиксном порядке.
-
Корень дерева.
Для нашего примера это будет: AB*CD*+BC*/. Суффиксный порядок обхода иногда называют обходом дерева снизу вверх.
Заметим, что инфиксный порядок обхода бинарного дерева в нашем примере совпал с самим алгебраическим выражением, только без скобок, суффиксный порядок – совпал с ОПЗ выражения, а результат префиксного обхода является обратным инфиксному, т.е. сначала указывается операция, затем операнды, – именно так записываются функции и процедуры на языке Паскаль. С обходом дерева как правило совмещаются некоторые действия над проходимой вершиной. Например, в случае суффиксного обхода, можно совместить обход с операцией удаления куста дерева.
void PrefixObhod (tree *p)
{
if (p !=NULL) // Если дерево не пусто, то префиксный порядок это:
{
printf ("%d", p->info); //обработка узла, например напечатем его инф.часть
PrefixObhod (p->ltree); // Узлы левого поддерева в префиксном порядке
PrefixObhod (p->rtree); // Узлы правого поддерева в префиксном порядке
}
}
void InfixObhod (tree *p)
{
if (p != NULL) // Если дерево не пусто, то инфиксный порядок это:
{
InfixObhod (p->ltree); // Узлы левого поддерева в инфиксном порядке
printf ("%d", p->info); //обработка узла, например напечатем его инф.часть
InfixObhod (p->rtree); // Узлы правого поддерева в инфиксном порядке
}
}
void DelSubTree (tree *p) //процедура удаление куста p с использованием суффиксного обхода
{
if (p != NULL) // Если дерево не пусто, то суффиксный порядок это:
{
DelSubTree (p->ltree); // Узлы левого поддерева в суффиксном порядке
DelSubTree (p->rtree); // Узлы правого поддерева в суффиксном порядке
free(p); //обработка узла, например удалим узел
}
}
void DelLeftTree (tree *p) //удаление левого поддерева для узла p
{
if (p != NULL)
{
DelSubTree (p->ltree);
p->ltree = NULL;
}
}
void DelRightTree (tree *p) //удаление правого поддерева для узла p
{
if (p != NULL)
{
DelSubTree (p->rtree);
p->ltree = NULL;
}
}
Сравнение деревьев производится путём сравнения информационной части (информационных полей) соответствующих деревьев, начиная с корня. Функция должна сравнивать информационные части узлов дерева, а далее рекурсивно сравнивать левые и правые поддеревья. Фактически функция осуществляет обход дерева сверху вниз. Выходом из рекурсии в данном случае будет сравнение значений указателей (в том числе и пустых). Для равных деревьев одновременно указатели будут обнулены и станут равными. В случае различия, это равенство не пройдет. Если же оба указателя отличны от пустых, т.е. указывают на поддеревья, то сравниваются их информационные части и соответственно левые и правые потомки. Если все эти три сравнения совпадают, то делается заключение о совпадении сравниваемых деревьев.
Напишем функцию, которая будет выдавать истинное значение, если два дерева равны, и ложное значение в противном случае.
bool TreeEqual(tree *p1, tree *p2)
{
if (p1 == p2) return true;
else
if ((p2 != NULL) && (p1 != NULL))
return ((p1->info = p2->info) && TreeEqual(p1->ltree, p2->ltree) &&
TreeEqual(p1->rtree, p2->rtree));
else return false;
}