

Лекции _ Вышка
.pdfПусть количественный признак X распределен нормально. Требуется оценить неизвестное среднеквадратическое отклонение по исправленному выборочному среднеквадратическому отклонению S . То есть, найти доверительный интервал, покрывающий параметр σ с надёжностью γ :
P ( |
|
σ - S |
|
< δ ) = γ ; |
P (S -δ < σ < S +δ ) = γ |
|
|
|||||
|
|
|
|
|||||||||
æ |
æ |
- |
|
δ ö |
< σ < |
æ |
+ |
δ öö |
= γ ; полагая q = |
δ |
, получим для q < 1 |
|
P ç S ç1 |
÷ |
S ç1 |
÷÷ |
S |
||||||||
è |
è |
|
|
S ø |
|
è |
|
S øø |
|
|
||
S(1- q) < σ < S(1+ q)
q = q(γ ,n) ищем по таблице
S = 
 nn-1 Dв .
nn-1 Dв .
Замечание: Если q > 1 , то, учитывая, что σ > 0 , имеем:
0 < σ < S(1+ q)
Пример1: Количественный признак X распределен нормально, n = 25 , S = 0,8 . Найти доверительный интервал, покрывающий генеральное среднеквадратичное отклонение σ с надёжностью 0,95.
Решение:
Согласно условию задачи γ = 0,95; n = 25; q = q(0,95;25) = 0,32 По формуле для оценки неизвестного σ имеем
0,8(1- 0,32) < σ < 0,8(1+ 0,32) 0,544 < σ <1,056
Пример 2: Произведено 12 измерений одним прибором (без систематических ошибок) некоторой физической величины, причем исправленное среднее квадратическое отклонение S случайных ошибок измерений оказалось равным 0,6. Найти точность прибора с надежностью 0,99.
Решение:
Точность прибора характеризуется средним квадратическим отклонением случайных ошибок измерений. Поэтому задача сводится к отысканию доверительного интервала, покрывающего параметр σ с заданной надежностью
γ = 0,99 .
S (1- q) < σ < S (1+ q) |
(**) |
90
По данным γ = 0,99 и n = 12 по таблице найдем q = 0,9 . Подставив S = 0,6 и q = 0,9 в соотношение (**), окончательно получим
0,06 < σ < 1,14
91

Лекция 18
Выборочный коэффициент корреляции. Условные средние.
Выборочные уравнения регрессии. Корреляционная таблица. Простейшие случаи криволинейной корреляции
Точечной характеристикой коэффициента корреляции служит выборочный коэффициент корреляции.
Если наблюдаемые значения признака X ,
|
X |
|
x1 |
|
|
x2 |
|
K |
|
|
xn |
|
||||
|
nx |
|
nx1 |
|
nx2 |
|
K |
|
|
nxn |
|
|||||
|
а наблюдаемые значения признака Y |
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Y |
|
y1 |
|
|
y2 |
|
K |
|
|
ym |
|
||||
|
ny |
|
ny1 |
|
ny 2 |
|
K |
|
|
nym |
|
|||||
|
а |
nxi y j |
– |
частота пары |
(xi , yj ) , тогда выборочный коэффициент |
|||||||||||
корреляции определяется по формуле |
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
m |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
åånxi y j |
xi y j |
− n xв yв |
|
|||||
|
|
|
|
|
|
|
rв = |
i=1 |
j =1 |
|
|
|
; |
|
||
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
nσ xвσ yв |
|
|||||
|
Здесь: |
xi |
– варианты признака |
X , |
yj – варианты признака Y , xв – |
|||||||||||
среднее выборочное признака X , yв – среднее выборочное признака Y , |
σ xв |
– выборочное среднеквадратичное отклонения признака X , σ yв |
– |
выборочное среднеквадратичное отклонение признака Y . |
|
Доверительный интервал для оценки генерального коэффициента корелляции нормального распределения
Можно показать, что если случайные величины X и Y имеют нормальное распределение, то для оценки генеральной корреляции служит интервал:
rв − 3 |
1+ rв2 |
≤ rГ ≤ rв + 3 |
1+ rв2 |
|
, |
||||
|
|
|
|
|
|
||||
|
n |
|
n |
||||||
|
|
|
|
|
|
||||
|
|
|
|
91 |
|
|
|
|
|
Формула применяется при объеме выборки n ³ 50 .
Условные средние.
Определение: Условным средним yx называется среднее арифметическое
наблюдаемых значений признака Y при условии, что признак X примет значение, равное x .
Найдем условные средние при следующих наблюдаемых значениях X иY
|
x1 = 2 |
x2 = 3 |
x3 = 4 |
yx1 |
= |
2 + 3+ 5 |
= |
10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
y1 |
2 |
4 |
-1 |
|
3 |
|
|
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
4 +1+ 0 |
|
|
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
y2 |
3 |
1 |
2 |
yx2 |
|
= |
= |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
3 |
|
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
y3 |
5 |
0 |
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
yx3 |
|
= |
−1+ 2 + 6 |
= |
7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
3 |
|
|
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
10 |
|
5 |
|
7 |
|
y = |
2 + 4 −1+ 3+1+ 2 + 5 + 0 + 6 |
= |
22 |
|
||||||||||||||||||||
yx |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
3 |
3 |
3 |
|
|
|
|
|
|
|
|
9 |
|
|
|
|
|
|
|
|
|
|
9 |
|
||||||||
i |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10 + 5 + |
7 |
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
yx |
+ yx |
+ yx |
|
|
|
|
|
22 |
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
y = |
|
= |
3 3 |
|
3 |
= |
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
1 |
|
2 |
|
3 |
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
3 |
|
|
|
3 |
|
|
|
9 |
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
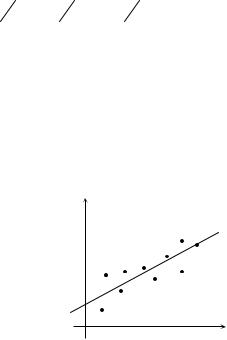
Выборочные уравнения регрессии.
Как |
видим |
yx |
является функцией от x . |
Уравнение |
yx = f *(x) |
называется выборочным уравнением регрессии Y |
на X , f *(x) |
– регрессия |
|||
a её |
график |
– |
линия регрессии. Уравнение |
xy = ϕ *(y) |
называется |
y
x
Рис. 1
выборочным уравнением регрессии X на Y . Если величины X и Y имеют линейную корреляцию, то линией регрессии будет прямая (рис.1).
92

Выборочное уравнение прямой линии регрессии.
Уравнением регрессии Y на X является зависимость yx = f *(x) . Пусть выборочное уравнение регрессии является линейным, то есть имеет вид yx = ρyx x + b . Найдем b . Запишем условные средние Y при различных значениях признака X .
ìy |
x1 |
= ρ |
yx |
× x + b |
ï |
|
1 |
||
ïyx2 |
= ρyx × x2 + b |
|||
í |
|
|
|
; |
ï... |
|
|
|
|
ï |
|
= ρyx × xn + b |
||
îyxn |
||||
|
yx |
+ yx |
+...+ yx |
|
x +...+ x |
||
Тогда |
1 |
2 |
n |
= ρyx |
1 |
n |
+ b , или yв = ρyx × xв + b; |
|
|
n |
|
|
|||
|
|
|
|
|
n |
||
Отсюда следует, что b = yв - ρyx × xв . Тогда yx = ρyx × x + yв - ρyx × xв . Запишем это уравнение в виде
yx - yв = ρyx (x - xв ) .
Можно показать, с помощью метода наименьших квадратов можно найти коэффициент ρyx , который называется коэффициентом регрессии.
|
ρyx = rв |
σ y |
|
, где rв – выборочный коэффициент корреляции. |
|||||||||
σ x |
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
||
Таким образом, получаем выборочное уравнение прямой линии |
|||||||||||||
регрессии Y на |
X . |
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
y |
|
- y |
|
= r |
σвy |
(x - x ) |
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
x |
|
в |
в σвx |
в |
|
||
Аналогично, выборочное уравнение прямой линии регрессии X на
Y .
xy - xв = rв σвx ( y - yв ) σвy
93

|
σвy |
|
|
σвx |
|
2 |
|
|
Замечание 1. Учитывая, что ρyx = rв |
|
, |
ρxy = rв |
|
, получим: |
ρxy ρyx = rв |
– |
|
σвx |
σвy |
|||||||
|
|
|
|
|
|
выборочный коэффициент корреляции является средним геометрическим коэффициентов регрессии.
Замечание 2. Уравнение прямой линии регрессии Y на X можно записать в симметричном виде:
|
|
yx − yв |
= rв |
x − xв |
|
|
|||
|
|
σвy |
|
σвx |
|||||
|
|
|
|
|
|
||||
а уравнение прямой линии регрессии X на Y соответственно в виде: |
|||||||||
|
|
xy − xв |
= rв |
|
y − yв |
|
|||
|
|
σвx |
|
|
σвy |
||||
|
|
|
|
|
|
||||
Пример: Написать |
уравнение прямой |
|
линии регрессии, если x = 4,1, |
||||||
σ x = 0,3 , σ y = 0,5 , |
rв = 0,1 , y = 8,1 |
|
|
|
|
|
|
|
|
|
yx −8,1 = 0,1 |
0,5 |
(x − 4,1) |
||||||
|
|
||||||||
|
|
|
0,3 |
|
|
|
|||
yx −8,1 = 16 (x − 4,1)
Корреляционная таблица.
При большом числе наблюдений одно и то же значение x может встретиться nx раз, одно и то же значение y – ny раз, одна и та же пара чисел (x, y) может наблюдаться nxy раз. Поэтому данные наблюдений группируют, т. е. подсчитывают частоты nx , ny , nxy . Все сгруппированные данные
записывают в виде таблицы, которую называют корреляционной. Поясним устройство таблицы на примере.
|
|
x1 =10 |
x2 = 20 |
x3 = 30 |
x4 = 40 |
ny |
||||
y1 |
= 0,4 |
nx1 y1 |
= 5 |
- |
nx3 y1 |
= 7 |
nx4 y1 |
= 14 |
26 |
|
y2 |
= 0,6 |
|
|
nx2 y2 |
= 2 |
nx3 y2 |
= 6 |
nx4 y2 |
= 4 |
12 |
y3 |
= 0,8 |
nx1 y3 |
= 3 |
nx2 y3 |
= 19 |
- |
- |
22 |
||
|
nx |
8 |
|
21 |
13 |
18 |
n = 60 |
|||
В первой строке таблицы указаны наблюдаемые значения признака X , в первом столбце – наблюдаемые значения признака Y . На пересечении строк
94

и столбцов находятся частоты nxy наблюдаемых пар значений признаков. В
последней строке записаны суммы частот столбцов. В клетке, расположенной в нижнем правом углу таблицы, помещена сумма всех частот.
ånxy = 60 = n; åny = n; ånx = n
Методика вычисления выборочного коэффициента корреляции по данным корреляционной таблицы.
Можно упростить вычисление выборочного коэффициента
|
|
x - C |
|
yj - C2 |
|
||
корреляции, если перейти к условным вариантам ui = |
i 1 |
; vj |
= |
|
|
. |
|
|
|
hy |
|||||
|
|
hx |
|
|
|
||
C1 ,C2 |
– ложные нули – варианты, имеющие наибольшую частоту, |
hx |
– шаг |
||||
по x , |
hy – по y . |
|
|
|
|
|
|
Выборочный коэффициент корреляции вычисляется по формуле:
rв = ånuvuv - nu v nσuσv
u,v - выборочные средние u и v . σu ,σv - выборочные средние
квадратические отклонения.
x = u ×hx + C1 , y = u ×hy + C2 , σ x = σu ×hx , σ y = σv ×hy
При вычислении ånuv ×uv можно воспользоваться формулами:
ånuv ×uv =åv ×U, |
где |
U = ånuv ×u или |
ånuv ×uv = åu ×V , |
где |
V = ånuv ×V |
Для контроля вычисляют по обеим формулам, совпадение результатов свидетельствует о правильности вычислений.
Простейшие случаи криволинейной корреляции
Определение: Если линией регрессии yx = f *(x) или xy = ϕ(y) является кривая порядка выше первого, то корреляцию называют криволинейной.
Например, yx = ax2 + bc + c (параболическая корреляция второго порядка). yx = ax3 + bx2 + cx + d (параболическая корреляция третьего порядка).
Теория криволинейной корреляции решает те же задачи, что и теория линейной корреляции, то есть установление тесноты связи между случайными величинами. Форма кривой регрессии находится методом
95

наименьших квадратов. Для оценки тесноты связи служат выборочные корреляционные отношения ηyx : 0 ≤ ηyx ≤ 1; η = σмежгруповое .
96
Лекция 19
Проверка статистических гипотез. Ошибки первого и второго рода. Критическая область. Область принятия гипотез.
Проверка гипотезы о значимости выборочного коэффициента корреляции.
Проверка статистических гипотез.
Часто необходимо знать закон распределения генеральной совокупности. Если закон распределения неизвестен, то имеются основания предположить, что он имеет определённый вид. То есть выдвигается гипотеза о виде распределения или о параметрах распределения.
Определение: Статистическими называются гипотезы о виде неизвестного распределения или о параметрах распределения.
Например, статистическими явлениями гипотезы:
1)генеральная совокупность распределена нормально.
2)генеральная совокупность имеет показательное распределение.
3)математическое ожидание генеральной совокупности равно 5 .
Гипотеза “ на Луне есть жизнь” не является статистической, так как не имеет отношения ни к виду распределения, ни к параметрам.
Наряду с выдвинутой гипотезой рассматривают и противоречащую ей гипотезу. Если выдвинутая гипотеза будет отвергнута, то будет принята противоречащая гипотеза.
Определение: нулевой (основной) гипотезой называют выдвинутую гипотезу
H0 .
Определение: конкурирующей (альтернативной) называют гипотезу H1 , которая противоречит основной.
Например, если нулевая гипотеза H0 : a = 4 , то H1 : a ¹ 4 .
Различают гипотезы, которые содержат одно или больше одного предположения:
Простой называют гипотезу, содержащую только одно предположение. Если λ – параметр показательного распределения, то H0 : λ = 5 – простая гипоте-
за.
Сложной гипотезой называют гипотезу, которая состоит из конечного или бесконечного числа простых гипотез. Например: H : λ > 5 состоит из беско-
96
нечного количества простых гипотез H0 : λ = bi , где bi > 5 . Гипотеза H0 :
математическое ожидание нормального распределения равно 3 (σ неизвестно) – сложная.
Ошибки первого и второго рода.
Выдвинутая гипотеза может быть правильной или неправильной, поэтому возникает необходимость её проверки. Поскольку проверку производят статистическими методами, то проверку называют статистической. При проверке гипотезы может быть сделаны ошибки: отвергнута правильная гипотеза и принята неправильная.
Ошибка первого рода состоит в том, что будет отвергнута правильная гипотеза H0 и принята неправильная гипотеза H1 , в то время как верна гипотеза
H0 .
Ошибка второго рода состоит в том, что будет принята неправильная гипотеза H0 , в то время как верна гипотеза H1 .
Определение: Вероятность совершить ошибку первого рода называется уров-
нем значимости α :
α = PH0 (H1 ) , где PH0 (H1 ) – вероятность принять гипотезу H1 , в то время как верна гипотеза H0 .
Наиболее часто его принимают равным α = 0,05 или α = 0,01. α = 1− γ , где γ – надежность.
Вероятность ошибки второго рода определяется параметром β :
β = PH1 (H0 ) , где PH1 (H0 ) – вероятность того, что будет принята гипотеза H0 , в то время как верной является гипотеза H1 .
Статистический критерий проверки нулевой гипотезы
Для проверки нулевой гипотезы используют специально подобранную случайную величину.
Определение: Статистическим критерием называют случайную величину K , которая служит для проверки нулевой гипотезы.
97