

9. Моделирование работы двух узлов коммутации [6]
Необходимо провести моделирование с целью получения оценок вероятностно-временных характеристик процесса функционирования фрагмента сети передачи данных (СПД).
В рассматриваемой СПД реализован режим коммутации пакетов, представляющей собой такой способ передачи, при котором данные из сообщений пользователей разбиваются на отдельные пакеты, маршруты передачи которых в сети от источника к получателю определяются в каждом узле коммутации (УК), куда пакеты поступают. Под сообщениями понимается конечная последовательность символов, имеющая смысловое содержание. Пакет - это блок данных с заголовком, представленный в установленном формате и имеющий ограниченную максимальную длину. Эффективность различных вариантов построения СПД и ее фрагментов оценивается средними временами доставки данных пользователям и вероятностями отказа в установлении требуемого пользователю соединения в данный момент времени. Совокупность таких показателей для оценки эффективности процесса функционирования процесса СПД принято называть ее вероятностно-временными характеристиками.
Логическая схема моделируемой системы
Рассмотрим процесс функционирования фрагмента СПД, представляющий собой взаимодействие двух соседних узлов коммутации СПД, обозначенных УК1 и УК2. Эти узлы соединены между собой дуплексным дискретным каналом связи (ДКС), позволяющим одновременно передавать данные во встречных направлениях, т.е. имеется два автономных однонаправленных ДКС. Будем считать, что все сообщения, поступающие в СПД, являются однопакетными.

Рис. 5.11. Структурная схема варианта УК
На рис.5.11 обозначено: ВхБН и ВыхБН -входные и выходные буферные накопители соответственно; К - коммутаторы; ЦП - центральный процессор. Этот УК функционирует следующим образом. После поступления пакета из одного из входных КС узла он помещается в ВхБН. Затем ЦП на основе заголовка пакета и хранимой в УК маршрутной таблицы определяет требуемое направление дальнейшей передачи пакета и помещает его в соответствующий ВыхБН для последующей передачи по выходному КС.
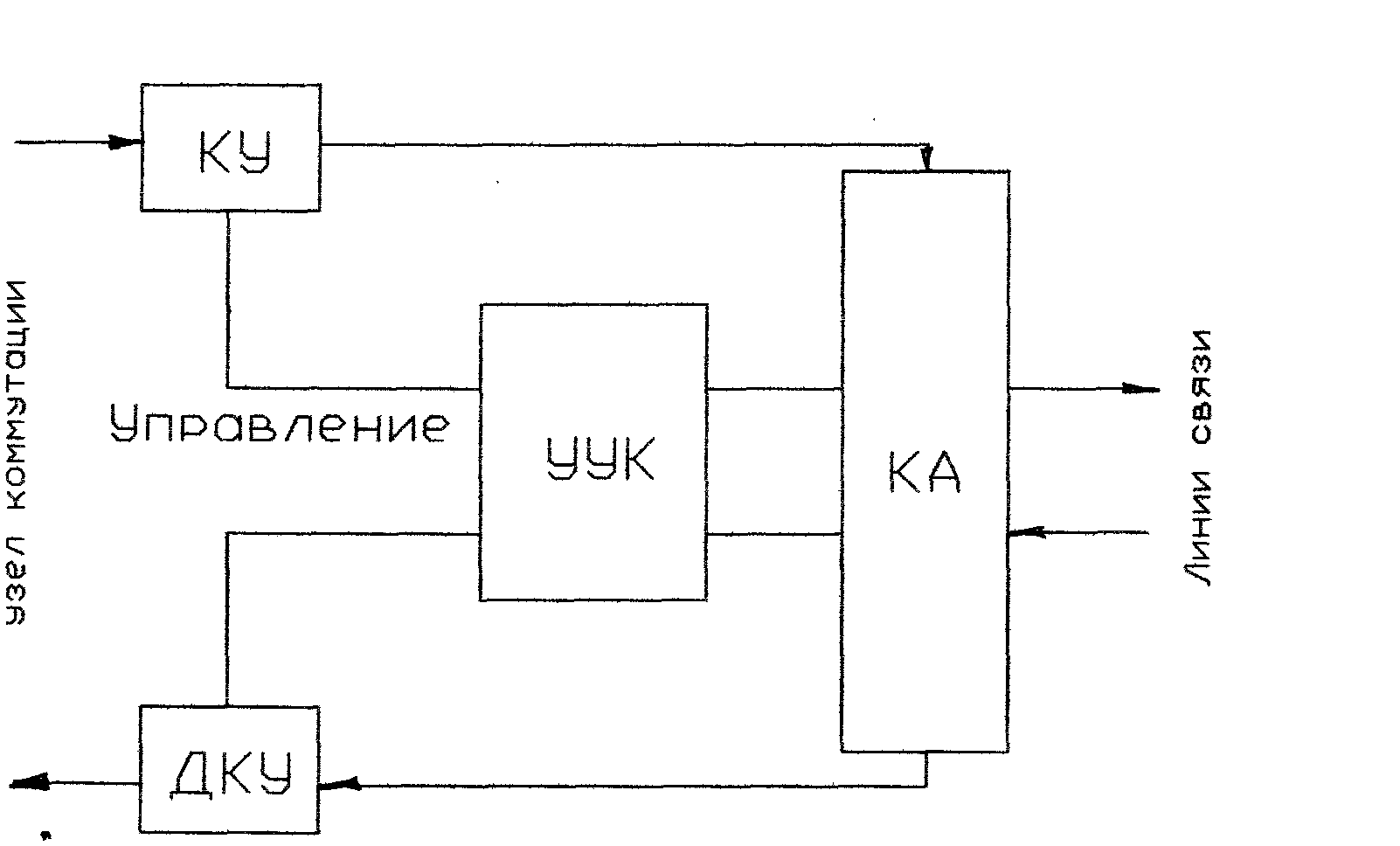
Рис. 5.12 Структурная схема варианта ДКС с решающей обратной связью.
На рис.5.12 обозначено: КУ и ДКУ - кодирующее и декодирующее устройства соответственно; УУК -устройство управления каналом; КА - каналообразующая аппаратура. На передающей стороне пакет из ВыхБН узла коммутации попадает в КУ, где производится кодирование, т.е. внесение избыточности, необходимой для обеспечения помехоустойчивой передачи по КС. Согласование с конкретной средой распространения реализуется КА. На приемной стороне из КА пакет попадает в ДКУ, которое настроено на обнаружение и/или исправление ошибок. Все функции управления КУ, ДКУ (в том числе и принятие решений о необходимости повторного переспроса копии пакета с передающего УК) и взаимодействия с центральной частью узла реализуются УУК, которое является либо автономным, либо представляет собой часть процедур, выполняемых ЦП узла.
Таким образом, общая структурная схема модели процесса взаимодействия двух узлов коммутации (УК1 и УК2) через дискретный канал связи (ДКС) будет выглядеть следующим образом (рис. 5.13),
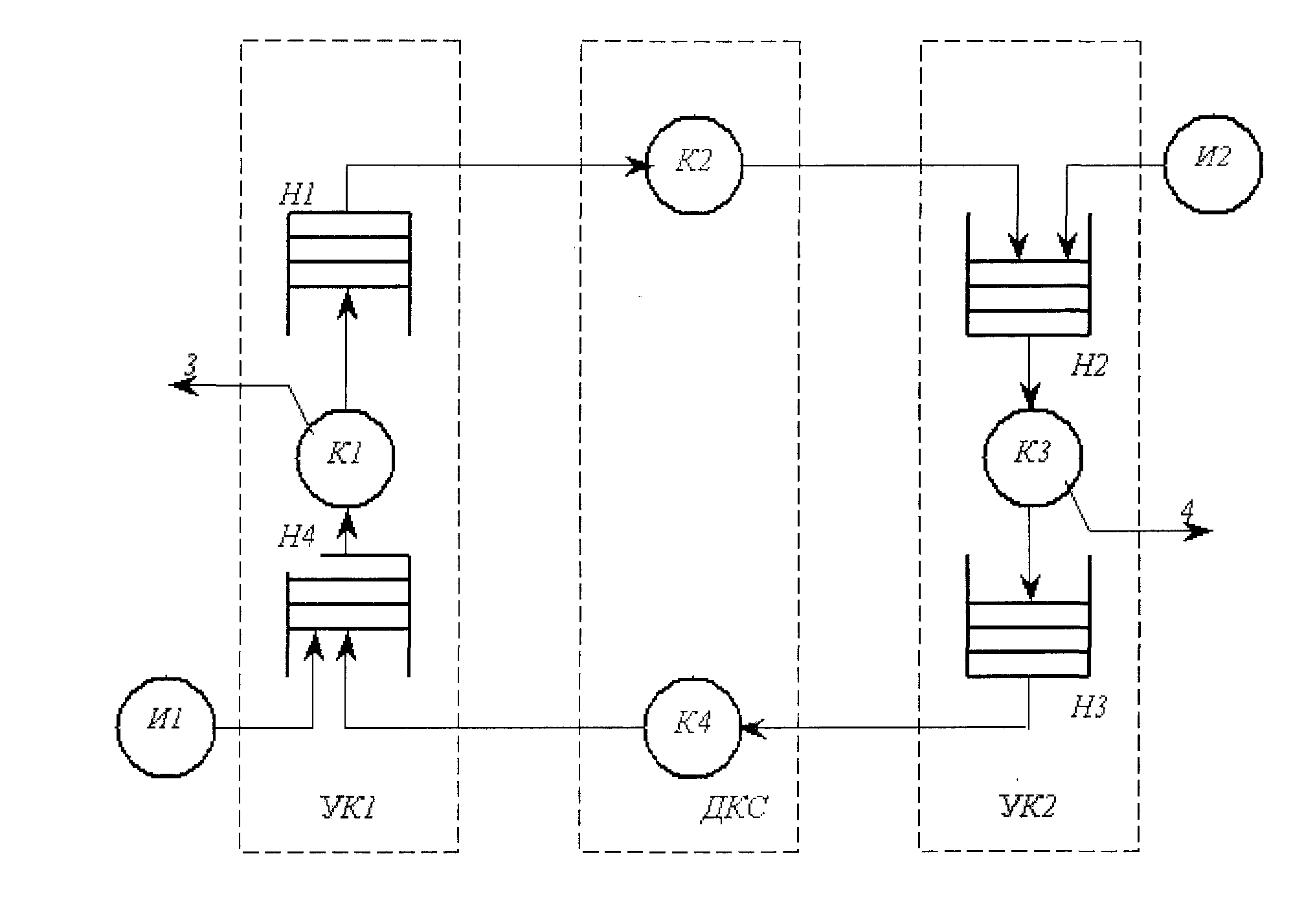
Рис 5.13. Структурная схема модели процесса взаимодействия двух узлов коммутации.
На рисунке обозначено: И - источник, К— канал, Н- накопитель. Поступление пакетов данных в моделируемый фрагмент СПД на входы имитируется источниками И1 и И2. Пакеты буферируются накопителями Н4 и Н2, т.е. ожидают освобождения каналов в УК1 и УК2 соответственно. После обслуживания каналами К1 и КЗ, т.е. после обработки ЦП УК1 и УК2 соответственно, пакеты поступают в выходные накопители HI и НЗ этих узлов. Далее, в порядке очереди, копии пакетов обслуживаются каналами К2 и К4, имитирующими процесс передачи по ДКС. При приеме копии пакета без ошибки, т.е. их поступлении в 112 и Н4, формируется подтверждение приема, которое в виде короткого пакета поступает в соответствующий выходной для данного узла накопитель HI и НЗ для передачи на другой УК, т.е. снова реализуется обслуживание каналами К2 и К4. После подтверждения в узле-источнике правильного приема уничтожается пакет, хранящийся в HI и НЗ. Выходам соответствуют точки 3 и 4 на структурной схеме модели процесса взаимодействия двух узлов коммутации СПД.
Блок-схема моделируемой системы.
Так как для моделирования выбран пакет GPSS, то необходимо разработать блок-схему модели, по сути представляющую собой логическую схему, адаптированную к особенностям использования для машинной реализации модели GPSS. Блок-схема модели процесса функционирования фрагмента СПД приведена на рис. 5.14, где для структурных элементов модели, показанных на рис.5.13, введены следующие обозначения:
для накопителей HI, Н2, НЗ и Н4 соответственно,
BUF1, BUF2, BUF3 и BUF4;
для источников И1 и И2 соответственно, GEN1 и GEN2;
для каналов обслуживания:
в узлах коммутации для ЦП Kl - CPU1 и КЗ - CPU2,
в каналах связи при дуплексной передаче К2 - DCH1 и К4 - DCH2.
Описание некоторых блоков, используемых при построении модели.
Блок SPLIT
Блок SPLIT имеет следующий формат:
SPLIT <A>,[<B>],[<C>]
Блок SPLIT выполняет функцию копирования входящего в него транзакта, которое называется исходным или порождающим.
В поле А задается число создаваемых копий. Операнд А может быть именем, положительным целым. Если вычисленное значение аргумента поля А равно нулю, то блок SPLIT не выполняет никаких операций. После создания копий транзакт пытается перейти к следующему по номеру блоку. Все копии формируются в момент входа порождающего транзакта в блок SPLIT.
Поле В задает номер следующего блока, к которому переходят копии исходного транзакта, причем значение вычисляется для каждой копии отдельно. Операнд В может быть именем, положительным целым,
В поле С может быть задан номер параметра, используемого для присвоения копиям последовательных номеров. Операнд С может быть именем, положительным целым.
Счетчик общего числа входов (Nj) и счетчик текущего числа сообщений (Wj) блока SPLIT увеличиваются на единицу каждым исходным транзактом и каждой копией. Счетчик числа транзактов уменьшается на единицу при каждом выходе исходного транзакта или копии из блока SPLIT.
Каждая новая копия становится членом семейства транзактов, порожденного одним исходным транзактом, которое было создано блоком GENERATE.
Транзакты, принадлежащие к одному семейству, объединяются интерпретатором в список.
Блок ASSEMBLE
Блок ASSEMBLE имеет следующий формат: ASSEMBLE <A>
Блок ASSEMBLE объединяет заданное число транзактов, принадлежащих к одному семейству, в один транзакт (т.е. осуществляет сборку заданного числа транзактов). После сборки из блока ASSEMBLE выходит только один транзакт, который переходит в следующий по номеру блок. В одном и том же блоке ASSEMBLE возможна одновременная сборка транзактов нескольких семейств. Когда транзакт входит в блок ASSEMBLE, интерпретатор просматривает семейство, к которому принадлежит этот транзакт, и проверяет, есть ли другой транзакт из того же семейства в данном блоке ASSEMBLE.
Поле А задает число транзактов, участвующих в сборке. Операнд А может быть именем, положительным целым. Первоначальное значение аргумента поля А не должно быть больше или равно единице. Если при входе исходного транзакта в блок ASSEMBLE, значение счетчика стало равным нулю (т.е. нужно было "объединить" только один транзакт), транзакт немедленно покидает блок ASSEMBLE и переходит в следующий по номеру блок.
Если результат отрицательный (вычисленное значение аргумента поля А нулевое иди отрицательное), происходит ошибка выполнения. Обычно значение счетчика сборки больше единицы, поэтому при входе в блок ASSEMBLE исходного транзакта результат вычитания единицы из счетчика положительный. Этот результат (новое значение счетчика сборки) сохраняется, а исходный транзакт исключается из списка текущих событий и переходит в состояние синхронизации. Этот транзакт не будет возвращен в список текущих событий до тех пор, пока в блок ASSEMBLE не войдет заданное число транзактов, и счетчик сборки не станет равным нулю.
Счетчики Nj и Wj блока ASSEMBLE увеличиваются на единицу. Затем интерпретатор переходит к обработке следующего транзакта списка текущих событий. При входе транзакта того же семейства в блок ASSEMBLE счетчик сборки уменьшается на единицу. Вновь прибывшее сообщение уничтожается. Если значение счетчика сборки все еще больше нуля, интерпретатор переходит к обработке следующего сообщения из списка текущих событий.
Если значение счетчика после вычитания единицы стало равным нулю, то исходный транзакта возвращается в список текущих событий и становится последним транзактом в своем приоритетном классе. Следовательно, может получиться так, что интерпретатор обработает ряд транзактов до того, как приступит к обработке транзакта, вышедшего из блока ASSEMBLE. Индикатор синхронизации устанавливается в "О", завершение сборки отмечается установкой флага изменения состояния. После возвращения исходного сообщения в список текущих событий, интерпретатор начинает просмотр с начала списка. Это обеспечит обработку исходного транзакта в тот же момент условного времени, когда заканчивается сборка. Даже если исходный транзакт не может войти в следующий по номеру блок, он больше не считается участвующим в процессе сборки. Это связано с тем, что индикатор синхронизации транзактов устанавливается в "О". Следовательно, если другой транзакт из того же семейства поступит в блок ASSEMBLE, он будет рассматриваться как исходный транзакт, и начнется новый процесс сборки. Счетчик Wj уменьшается на единицу при каждом выходе транзакта из блока ASSEMBLE.
Блок MATCH
Блок MATCH имеет следующий формат:
MATCH <A>
Блок MATCH используется для синхронизации движения двух транзактов, принадлежащих к одному семейству, без удаления этих транзактов из модели.
Блоки MATCH не объединяют синхронизируемые транзакты. Синхронизация осуществляется путем подбора пар транзактов из одного семейства и задержки этих транзактов до тех пор, пока оба транзакта из одной пары не поступят в заданные точки модели. Транзакты никогда не задерживаются в блоке MATCH. Транзакты, для которых выполнилось условие синхронизации, переходят к следующему по номеру блоку. В одной паре блоков MATCH могут одновременно находиться в состоянии синхронизации пары транзактов из различных семейств. Возможна также одновременная синхронизации пар транзктов из одного семейства в нескольких блоках MATCH.
Поле А задает имя или номер другого блока MATCH, называемого "сопряженным блоком MATCH". Если такого блока нет, происходит останов по ошибке. Операнд А может быть именем, положительным целым. Когда транзакт входит в блок LEAVE, то ищется многоканальное устройство, заданное в поле А. Если такое многоканальное устройство не существует, то возникает ошибка выполнения. Число освобождаемых единиц многоканального устройства берется из операнда В. Когда многоканальное устройство становится доступным, проверяется список задержки многоканального устройства, в порядке уменьшения приоритета с целью нахождения транзактов, запросы которых могут быть удовлетворены в данный момент. Если такие транзакты найдены, то они входят в блок ENTER, который отказал им, и далее помещаются в список будущих событий за транзактами с таким же приоритетом. Попытка освободить больше единиц емкости, чем было определено, приводит к ошибке.
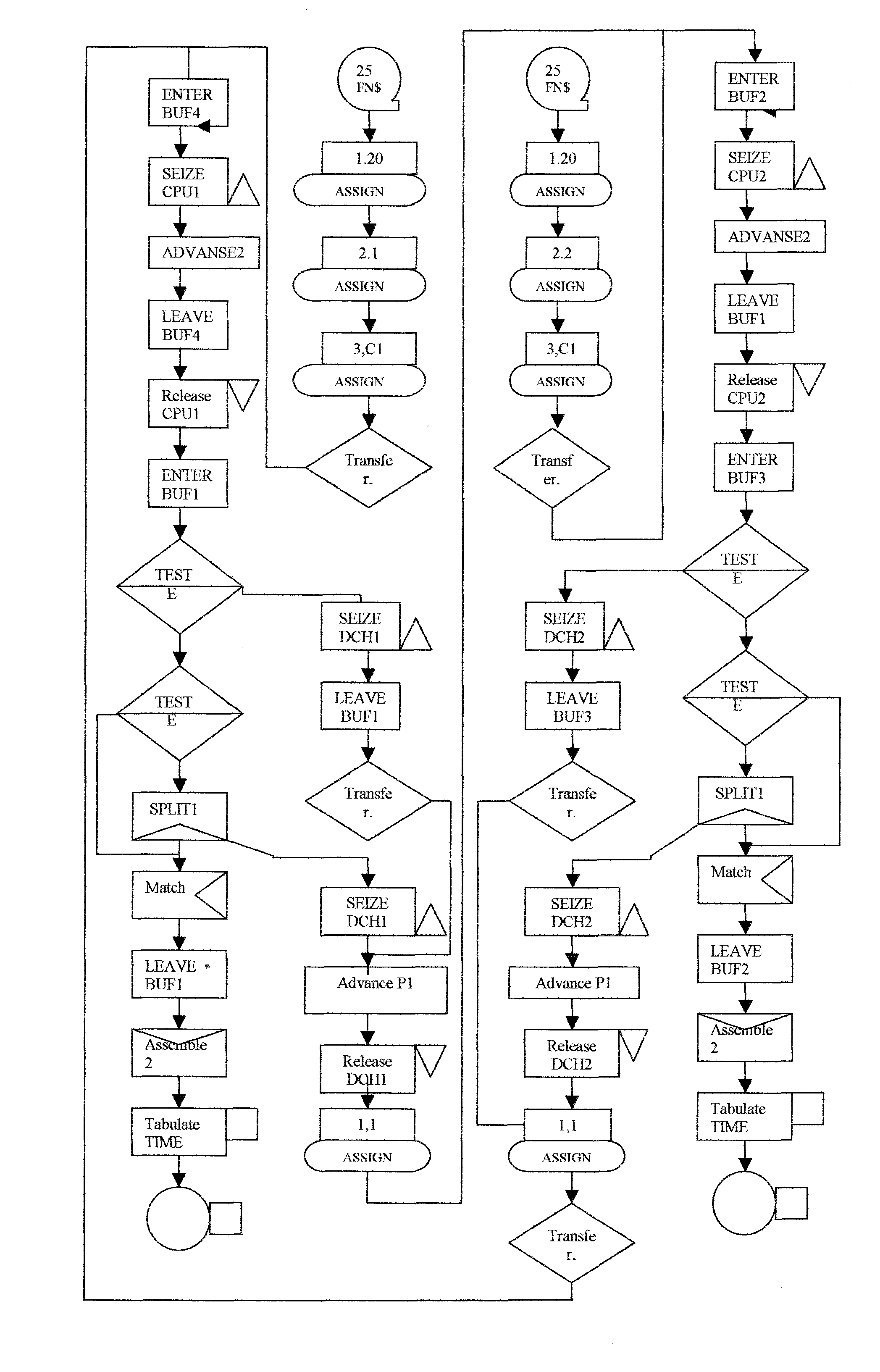
Рис. 5.14. Блок-схема программы моделирования работы двух узлов коммутации.
.
Листинг программы.
RMULT 111
EXPON FUNCTION RN1,C24
0,0/.1,.104/.2,.222/.3,.355/.4,.509/.5,.69/.6,.915/.7,1.2/.75,1.38/.8,1.6/.84,1.83
.88,2.12/.9,2.3/.92,2.52/.94,2.81/.95,2.99/.96,3.2/.97,3.5/.98,3.9/.99,4.6/.995,5.3
.998,6.2/.999,7/.9998,8
*Определение емкости буферов
BUF1 STORAGE 20
BUF2 STORAGE 20
BUF3 STORAGE 20
BUF4 STORAGE 20
*Задание таблиц переменных
TIME TABLE V$TIME,0,20,16
TIME FVARIABLE C1-P3
MET1 ENTER BUF4
SEIZE CPU1
ADVANCE 2
LEAVE BUF4
RELEASE CPU1
ENTER BUF1
TEST E P2,1,MET4
TEST E P1,20,COP1
SPLIT 1,NEX1
COP1 MATCH COP1
LEAVE BUF1
ASSEMBLE 2
TABULATE TIME
TERMINATE
MET4 SEIZE DCH1
LEAVE BUF1
TRANSFER ,NEX11
NEX1 SEIZE DCH1
NEX11 ADVANCE P1
RELEASE DCH1
ASSIGN 1,1
MET2 ENTER BUF2
SEIZE CPU2
ADVANCE 2
LEAVE BUF2
RELEASE CPU2
ENTER BUF3
TEST E P2,2,MET5
TEST E P1,20,COR2
SPLIT 1,NEX2
COP2 MATCH COP2
LEAVE BUF3
ASSEMBLE 2
TABULATE TIME
TERMINATE
MET5 SEIZE DCH2
LEAVE BUF3
TRANSFER ,NEX21
NEX2 SEIZE DCH2
NEX21 ADVANCE P1
RELEASE DCH2
ASSIGN 1,1
TRANSFER ,MET1
GEN2 GENERATE 25,FN$EXPON
ASSIGN 1,20
ASSIGN 2,2
ASSIGN 3,C1
TRANSFER ,MET2
GEN1 GENERATE 25,FN$EXPON
ASSIGN 1,20
ASSIGN 1,2
ASSIGN 3,C1
TRANSFER ,MET1
GENERATE 1,,10000
TERMINATE 1
Лабораторные работы по курсу «Моделирование».
Лабораторная работа № 1
Моделирование одноканальной системы массового обслуживания с одномерным входным потоком
Провести моделирование
одноканальной системы массового
обслуживания с одномерным потоком
заявок. Интенсивность входного потока
–λi
задается
формулой
![]()
где
![]() -среднее
время между поступлением заявок в
систему:
-среднее
время между поступлением заявок в
систему:
![]() = 10*i
,
= 10*i
,
i - номер варианта.Номер варианта совпадает с номером в списке группы.Интенсивность обслуживания µ = 1/tоб.i ,
где tоб - среднее время обслуживания заявки tоб= 0.6 ti .
Интервалы между поступлением заявок и время обслуживания заявок распределены по экспоненциальному закону.
Провести моделирование системы ,изменяя величину = /µ= tоб / ti
с 0.6 до 1.1 через 0.1 т.е провести исследование системы при tоб= 0.6 ti,0,7ti,, 0.8 ti,, 0.9 ti,, 1.0 ti,, 1.1 ti,
Время моделирования положить равным 500 ti.
Объяснить результаты моделирования.
Контрольные вопросы
Какие системы массового обслуживания называются одномерными ?
Что определяет величина ?
Как ведет себя очередь при увеличении ?
Сколько транзактов будет введено в систему,если tоб = 0.8 ti,, а время моделирования равно 500 ti ?
5. Каким образом можно изменить последовательность временных интервалов между приходом заявок в систему ?