

[ММвЛХ] Методуказания_Матметоды_в_ЛХ
.pdf3. Проверка статистических гипотезо соответствии распределения частот теоретичекому распределению в среде Statistica
Откройте программу Statistica.
Выберите в меню: Анализ → Подгонка распределения → нажмите селекторную кнопку Непрерывное→ выделите Нормальное → OK →
введите переменную → D → Наблюдаемые и ожидаемые частоты→
OK → скопируйте таблицу и вставьте в отчет → разверните свернутое окно анализа → График наблюдаемого и ожидаемого распределения
→ OK. График (рис.8) скопируйте в отчет.
Проверьте аналогичным образом соответствие нормальному закону распределение частот по H и A.
Рис. 8. Графическое представление наблюдаемых и ожидаемых частот в программе
Statistica
21
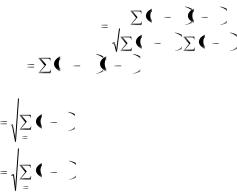
ЛАБОРАТОРНАЯ РАБОТА №4. КОРРЕЛЯЦИОННЫЙ АНАЛИЗ
Цель работы: закрепить знания по выявлению наличия связей между случайными величинами и их оценке по величине коэффициента корреляции, получить практические навыки по автоматизации обработки данных в среде Excel.
Краткие теоретические сведения
Корреляционным анализом называется многообразие методов исследования параметров генеральной совокупности, распределенной по нормальному закону. Корреляционный анализ позволяет с помощью выборки делать выводы о степени статистической связи (мере связи), между признаками.
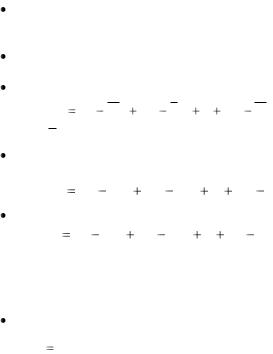
Наиболее распространѐнная мера статистической линейной связи между признаками – коэффициент корреляции Пирсона:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
r |
|
|
|
Xi |
|
X Yi |
Y |
|
, |
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
2 |
Yi |
|
2 |
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
Xi |
X |
Y |
|
|
||||||
где Sxy |
|
Xi |
|
|
X Yi Y – среднее квадратическое отклонение по |
||||||||||||||||||
хy; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
k |
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Sx |
xi |
|
x |
|
|
– среднее квадратическое отклонение по х; |
|||||||||||||||||
|
i |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
k |
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
S y |
yi |
|
y |
|
|
– среднее квадратическое отклонение по у. |
|||||||||||||||||
|
i |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Коэффициент корреляции изменяется от -1 до +1. Если r = 0, то линейная связь между изучаемыми случайными величинами отсутствует, если r = ±1, то связь функциональная; «-» – отрицательная зависимость, «+» – положительная. При положительной связи с увеличением (уменьшением) одного признака происходит увеличение (уменьшение) другого: ↑x↑y или ↓x↓y. При отрицательной – при увеличении одного признака другой уменьшается, и наоборот: ↑x↓y, ↓x↑y.
22
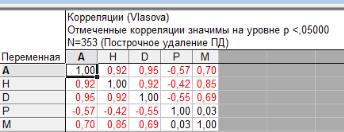
Таблица 3.Шкала оценки меры связи
|
r |
Характеристика меры связи между случайными |
|
|
величинами |
0 – 0,30 |
Слабая |
|
0,31 |
– 0,50 |
Умеренная |
0,51 |
– 0,70 |
Значительная |
0,71 |
– 0,90 |
Большая (тесная) |
0,91 |
– 1 |
Очень тесная |
Содержание работы
1. Расчет коэффициента корреляции в Excel
Раскройте лист «Исходные данные». В строке меню выберите Дан-
ные → Анализ данных → Корреляция → ОК. В появившемся окне диалога нажмите кнопку в поле «Входной интервал» - выделите столбцы с данными A, H, D, PRO, Р, М, затем снова нажмите на кнопку. В диалоговом окне «Корреляция» поставьте «птичку» Метки в первой строке и выделите «селекторную кнопку» Новый рабочий лист – ОК. На новом рабочем листе появится таблица – корреляционная решетка для A, H, D, PRO, Р, М. Назовите этот лист «Корреляция». Файл сохраните. Полученную таблицу скопируйте в MS Word (в отчет).
2. Расчет коэффициента корреляции в программе Statistica
Анализ → Основные статистики и таблицы → Парные и частные корреляции→ ОK → Квадратная матрица→ выделите переменные: A, H, D, P, M→ОK → Матрица парных корреляций.
Полученную таблицу (рис. 9) и график скопируйте в MS Word (в отчет).
3. Анализ связи между таксационными показателями На основании полученных данных и данных табл.2 сделайте выводы
о характере и направленности связи между A и H, А и D, A и Р, A и М, H и D, H и Р, H и М, D и Р, D и М, P и M.
Рис. 9. Корреляционная матрица в программе Statistica
23
ЛАБОРАТОРНАЯ РАБОТА №5. ДИСПЕРСИОННЫЙ АНАЛИЗ
Цель работы: провести однофакторный и двухфакторный дисперсионный анализ для выявления влияющих факторов на процент выхода дровяной древесины в среде Excel и Statistica.
Краткие теоретические сведения
Дисперсионный анализ применяется для обнаружения выделенного набора факторов на результативный признак. Факторы могут измеряться в неколичественной шкале, а результативный признак выражаться числом или вектором с числовыми компонентами.
Идея дисперсионного анализа состоит в разложении общей дисперсии результативного признака на части, обусловленные влиянием контролируемых факторов (межгрупповая дисперсия), и остаточную (внутригрупповую) дисперсию, объясняемую неконтролируемым влиянием или случайными обстоятельствами.
Выводы о существенности влияния контролируемых факторов на результат производятся путем сравнения частей общей дисперсии при выполнении требования нормальности распределения результативного
признака.
S2y= S2x + S2e ,
где S2y– общая дисперсия,
S2x– межгрупповая (факториальная, т.к. зависит от действия контролируемых факторов),
S2e– внутригрупповая или остаточная.
Известно много моделей дисперсионного анализа. Они классифицируются с одной стороны по математической природе факторов (детерминированные, случайные и смешанные) и, с другой стороны – по числу контролируемых факторов (однофакторные и многофакторные модели).
Модели с более чем одним фактором дают возможность исследовать влияние на результат не только отдельных контролируемых факторов (главные влияния), но и их наложение (взаимодействия).
Отношение межгрупповой дисперсии (факториальной) к внутригрупповой дисперсии (остаточной) служит критерием оценки влияния
регулируемых в опыте факторов на результативный признак:
Fфакт. = S2x / S2e = S2м.г. /S2в.г. (при S2x ≥ S2e).
Если Fфакт. > Fкрит. (для принятого уровня значимости α и числа степеней свободы k) действие контролируемого фактора (нескольких фак-
24
торов или их совместное действие) доказано (статистически достоверно).
Заключительный этап – оценка силы влияния отдельных факторов или их совместного действия на признак. Наибольшее влияние оказывает, тот фактор, у которого дисперсия или сумма квадратов (SS – в статистических пакетах) наибольшая.
Содержание работы
Исходные данные для выполнения данной лабораторной работы находятся в приложении 2, вариант выбирается по номеру компьютера.
Даны следующие исходные данные:
Древесная порода-сосна, изучаемый признак –X - % выхода дров; влияющие факторы: A-число лет после пожара; B-средний диаметр древостоя.
Таблица 4.Исходные данные для дисперсионного анализа
|
|
A=1 |
|
|
A=2 |
|
|
A=3 |
|
|
B=12 |
B=16 |
B=20 |
B=12 |
B=16 |
B=20 |
B=12 |
B=16 |
B=20 |
X |
36 |
26 |
19 |
70 |
45 |
33 |
73 |
54 |
42 |
|
37 |
27 |
20 |
72 |
46 |
34 |
75 |
55 |
44 |
|
34 |
25 |
18 |
68 |
44 |
32 |
70 |
52 |
40 |
1.Однофакторный дисперсионный анализ в Excel
На листе «Исходные данные» введите данные из своего варианта задания как показано в табл. 5.
Таблица 5. Представление исходных данных для работы в Excel
|
A1 |
A2 |
A3 |
B12 |
36 |
70 |
73 |
B12 |
37 |
72 |
75 |
B12 |
34 |
68 |
70 |
B16 |
26 |
45 |
54 |
B16 |
27 |
46 |
55 |
B16 |
25 |
44 |
52 |
B20 |
19 |
33 |
42 |
B20 |
20 |
34 |
44 |
B20 |
18 |
32 |
40 |
В строке меню выберите: Данные → Анализ данных → Однофакторный дисперсионный анализ → ОК. В появившемся окне диалога нажмите кнопку в поле «Входной интервал» - выделите столбцы с данными A1, A2, A3, затем снова нажмите на кнопку, поставьте «птичку»
Метки в первой строке, выделите «селекторную кнопку» Группирование: по столбцам и Новый рабочий лист → ОК.
25
На новом рабочем листе появится таблица с итогами дисперсионного анализа. Назовите этот лист «Дисперсионный анализ 1». Файл сохраните. Полученную таблицу скопируйте в Word (в отчет).
Сделайте вывод о наличии или отсутствии влияния фактора А (число лет после пожара) на результативный признак Х (% выхода дров из древостоя). Для этого сравните сумму квадратов (SS) между группами и внутри групп, а также оцените фактическое и критическое значение F-
критерия.
Вернитесь в Excel на лист «Исходные данные». В строке меню вы-
берите Данные → Анализ данных → Однофакторный дисперсионный анализ → ОК. В появившемся окне диалога нажмите кнопку в поле «Входной интервал» - выделите строки с данными B12, B16, B20, затем снова нажмите на кнопку, поставьте «птичку» Метки в первом столб-
це, выделите «селекторную кнопку» Группирование: по строкам и Новый рабочий лист – ОК.
Новый лист переименуйте в «Дисперсионный анализ 2». Файл сохраните. Полученную таблицу скопируйте в Word (в отчет). Сделайте вывод о наличии или отсутствии влияния фактора В (средний диаметр древостоя) на результативный признак Х (% выхода дров из древостоя).
2. Двухфакторный дисперсионный анализ в Excel
Вернитесь в Excel на лист «Исходные данные». В строке меню вы-
берите Данные → Анализ данных → Двухфакторный дисперсионный анализ без повторений → ОК. В появившемся окне диалога нажмите кнопку в поле «Входной интервал» - выделите всю таблицу с данными A1, A2, A3, B12, B16, B20, затем снова нажмите на кнопку, поставьте «птичку» Метки, выделите «селекторную кнопку» Новый рабочий лист – ОК. Новый лист переименуйте в «Дисперсионный анализ 3». Файл сохраните. Полученную таблицу скопируйте в Word (в отчет). Сделайте вывод о наличии совместного влияния факторов А и В на результативный признак и в случае его подтверждения о том, какой фактор влияет сильнее.
3. Дисперсионный анализ в среде Statistica
Откройте свой файл с исходными данными в программе Statistica. Добавьте три новых столбика Year, Diametr, Volume. (Переменные → Добавить → Число переменных: 3). Введите данные, как показано в таблице 6.
Встроке меню выберите Анализ → Дисперсионный анализ (Д.А.)
→Главные эффекты → ОК →Переменные → Зависимые переменные:
Volume → Независимые: Year и Diametr → ОК → ОК → Все эффекты
(таблицу (рис. 10) скопируйте и вставьте в отчет.
26
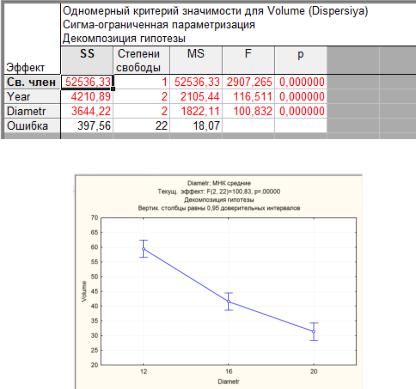
Таблица 6. Представление исходных данных для работы в программе Statistica
Year |
Diametr |
Volume |
1 |
12 |
36 |
1 |
12 |
37 |
… |
… |
… |
2 |
12 |
70 |
… |
… |
… |
2 |
16 |
45 |
… |
… |
…. |
3 |
20 |
40 |
Вернитесь в окно диалога анализа → Все эффекты/графики → выделите строку Year → ОК → график ( рис.11) скопируйте и вставьте в отчет. Аналогично постройте график для фактора Diametr.
Рис. 10. Результаты дисперсионного анализа в программе Statistica
Рис. 11. Графическое представление результатов дисперсионного анализа в программе Statistica
27
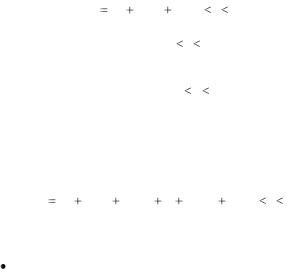
ЛАБОРАТОРНАЯ РАБОТА №6. РЕГРЕССИОННЫЙ АНАЛИЗ (ПРОСТАЯ РЕГРЕССИЯ)
Цель работы: Закрепить знания по разработке регрессионных моделей и оценке их адекватности эмпирическим данным, получить практические навыки по автоматизации обработки данных в среде Excel и Statistica.
Краткие теоретические сведения
Регрессионный анализ - это метод определения степени раздельного или совместного влияния факторов на результативный признак.
Процедура простой регрессии заключается в нахождении аналитического выражения для связи двух переменных X и Y.
Переменная X носит название независимой переменной, или предиктора, переменная Y называется зависимой переменной, или откликом.
Данная терминология связана с тем, что необходимо определить именно зависимость Y от X или предсказать, какими будут значения Y при данных значениях X.
Значение переменной X в i-м опыте обозначают через Xi, соответствующее значение величины Y - через Yi, 0 < i < = n.
Cамая простая регрессионная модель – линейная, в рамках этой модели наблюдаемые величины X и Y связаны между собой регрессионной зависимостью вида:
Yi b0 b1Xi ei , 0 i n ,
где b0, bl – неизвестные константы, ei – ненаблюдаемые случайные величины (наблюдаются только Xi, Yi, 0 i n ) со средним 0 (как говорят, являются несмещенными) и неизвестной дисперсией, не меняющейся от опыта к опыту.
Иногда случайные величины ei, 0 i n называют ошибками наблюдения. Относительно ei предполагается, что они не коррелированы в разных опытах. Кроме того, часто предполагается, что ошибки имеют нормальное распределение. В этом случае некоррелированность влечет независимость.
Линейные модели с несколькими независимыми переменными на-
зывают множественными регрессионными моделями:
Yi b0 b1X1 b2 X 2 ... bk X k ei , 0 i n
где b0, bl, b2, ..., bk – неизвестные коэффициенты.
Общая задача регрессионного анализа состоит в том, чтобы по наблюдениям:
оценить параметры модели b0 и bl;
28
построить доверительные интервалы для b0 и bl; проверить гипотезу о значимости регрессии; оценить степень адекватности модели и т.д.
В рассмотренном ниже примере (рис. 9) оценка свободного членауравнения b0, равна 5,99, оценка коэффициента bl – угла наклона – равна 0,36. Такие оценки называют оценками, построенными методом наименьших квадратов, или более кратко - оценками наименьших квадратов. Требование метода заключается в том, чтобы теоретические точки линии регрессии Ŷi были получены таким образом, чтобы сумма квадратов отклонений от этих точек эмпирических (наблюдаемых) значений Yi была минимальной, т.е. Σ(Yi – Ŷi)2→min.
Под адекватностью понимается способность модели предсказывать результаты эксперимента с требуемой точностью.
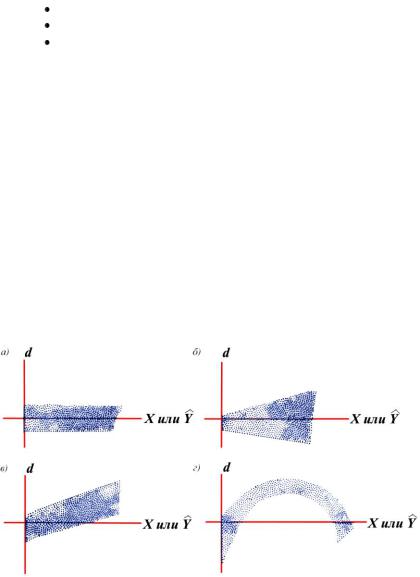
Модель можно считать адекватной, если множественный коэффициент корреляции (R) и коэффициент детерминации (R- квадрат) имеют значение, превышающее 0,5; сумма квадратов регрессии превышает сумму квадратов остатков (см. колонку SS), стандартная ошибка не велика, фактическое значение критерия Фишера (F) превышает теоретическое при данном числе степеней свободы (df) и заданном уровне значимости. В оценке адекватности модели важную роль играет и график остатков (рис.7).
Рис.7. Примеры графиков остатков: а) адекватная модель; b) гетероскедастичность (отсутствие постоянства дисперсии) указывает на необходимость преобразования
переменной Y; с) линейная независимая переменная; d) линейная или квадратичная независимая переменная
29
Основные понятия регрессионного анализа, используемые в таблицах вывода в модуле Регрессия (MS Excel):
Предсказанные значения Ŷi – значения Y, вычисленные по уравнению с оцененными параметрами (в нашем примере по уравнению M=5,99+0,36D).
Остатки – разности между наблюдаемыми значениями и предсказанными: Yi –Ŷi.
Сумма квадратов Y, скорректированная на среднее(SS):
SS (Y1 Y )2 (Y2 Y )2 ... (Yn Y )2 ,
где Y – среднее значение Y.
Сумма квадратов Ŷi, скорректированная на среднее – SS регрессии (SS регр.):
|
ˆ |
|
|
|
2 |
ˆ |
|
|
|
2 |
|
ˆ |
|
|
|
|
2 |
|
SS регр. |
Y ) |
Y ) |
... |
Y ) |
|
|||||||||||||
(Y1 |
|
(Y2 |
|
(Yn |
|
. |
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Сумма квадратов остатков - SS остатков (SSост..): |
||||||||||||||||||
SSост. |
(Y1 |
ˆ |
2 |
|
(Y2 |
ˆ |
2 |
|
... |
(Yn |
ˆ |
2 |
|
|
||||
Y1 ) |
|
|
Y2 ) |
|
|
Yn ) |
. |
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
Исходя из вышеизложенного: SS = SSрегр.+ SSост.
Несмотря на то, что это соотношение элементарно, оно играет ключевую роль в регрессионном и дисперсионном анализах. Именно на нем основывается большинство выводов в них.
Коэффициент детерминации – R-квадрат (R2):
R2 |
SS регр |
|
|
SS . |
|||
|
|||
Коэффициент детерминации измеряет долю разброса относительно среднего значения, которую «объясняет» построенная регрессия. Коэффициент детерминации лежит в пределах от 0 до 1. Он измеряет качество построенной регрессии. Чем ближе коэффициент детерминации к 1, тем лучше регрессия «объясняет» зависимость в данных.
Содержание работы
1. Построение регрессионной модели в Excel
Раскройте лист «Исходные данные». В строке меню выберите Дан-
ные → Анализ данных → Регрессия → ОК. В появившемся окне диало-
га нажмите кнопку в поле «Входной интервал Y» - выделите столбец с данными по запасу М, затем снова нажмите на кнопку, в поле «Входной интервал X» - выделите столбец с данными по запасу D, затем снова нажмите на кнопку. В окне диалога «Регрессия» поставьте «птички»
30