

Лабораторная работа № 6 Телекоммуникации и сети
Семиуровневая модель OSI
Модель OSI (Open System Interconnect Reference Model, Эталонная модель взаимодействия открытых систем) представляет собой универсальный стандарт на взаимодействие двух систем (компьютеров) через вычислительную сеть.
Эта модель описывает функции семи иерархических уровней и интерфейсы взаимодействия между уровнями. Каждый уровень определяется сервисом, который он предоставляет вышестоящему уровню, и протоколом - набором правил и форматов данных для взаимодействия между собой объектов одного уровня, работающих на разных компьютерах.
Идея состоит в том, что вся сложная процедура сетевого взаимодействия может быть разбита на некоторое количество примитивов, последовательно выполняющихся объектами, соотнесенными с уровнями модели. Модель построена так, что объекты одного уровня двух взаимодействующих компьютеров сообщаются непосредственно друг с другом с помощью соответствующих протоколов, не зная, какие уровни лежат под ними и какие функции они выполняют. Задача объектов – предоставить через стандартизованный интерфейс определенный сервис вышестоящему уровню, воспользовавшись, если нужно, сервисом, который предоставляет данному объекту нижележащий уровень.
Например, некий процесс отправляет данные через сеть процессу, находящемуся на другом компьютере. Через стандартизованный интерфейс процесс-отправитель передает данные нижнему уровню, который предоставляет процессу сервис по пересылке данных, а процесс-получатель через такой же стандартизованный интерфейс получает эти данные от нижнего уровня. При этом ни один из процессов не знает и не имеет необходимости знать, как именно осуществляет передачу данных протокол нижнего уровня, сколько еще уровней находится под ним, какова физическая среда передачи данных и каким путем они движутся.
Эти процессы, с другой стороны, могут находиться не на самом верхнем уровне модели. Предположим, что они через стандартный интерфейс взаимодействуют с приложениями вышестоящего уровня и их задача (предоставляемый сервис) - преобразование данных, а именно фрагментация и сборка больших блоков данных, которые вышестоящие приложения отправляют друг другу. При этом сущность этих данных и их интерпретация для рассматриваемых процессов совершенно не важны.
Возможна также взаимозаменяемость объектов одного уровня (например, при изменении способа реализации сервиса) таким образом, что объект вышестоящего уровня не заметит подмены.
Вернемся к примеру: приложения не знают о том, что их данные преобразуются именно путем фрагментации/сборки, им достаточно знать то, что нижний уровень предоставляет им некий “правильный” сервис преобразования данных. Если же для какой-то другой сети понадобится не фрагментация/сборка пакетов, а, скажем, перестановка местами четных и нечетных бит, то процессы рассматриваемого уровня будут заменены, но приложения ничего не заметят, так как их интерфейсы с нижележащим уровнем стандартизованы, а конкретные действия нижележащих уровней скрыты от них.
Объекты, выполняющие функции уровней, могут быть реализованы в программном, программно-аппаратном или аппаратном виде. Как правило, чем ниже уровень, тем больше доля аппаратной части в его реализации.
Организация сетевого взаимодействия компьютеров, построенного на основе иерархических уровней, как описано выше, часто называется протокольным стеком
Уровни модели OSI
Ниже перечислены (в направлении сверху вниз) уровни модели OSI и указаны их общие функции.
Уровень приложения (Application) - интерфейс с прикладными процессами.
Уровень представления (Presentation) - согласование представления (форматов, кодировок) данных прикладных процессов.
Сеансовый уровень (Session) - установление, поддержка и закрытие логического сеанса связи между удаленными процессами.
Транспортный уровень (Transport) - обеспечение безошибочного сквозного обмена потоками данных между процессами во время сеанса.
Сетевой уровень (Network) - фрагментация и сборка передаваемых транспортным уровнем данных, маршрутизация и продвижение их по сети от компьютера-отправителя к компьютеру-получателю.
Канальный уровень (Data Link) - управление каналом передачи данных, управление доступом к среде передачи, передача данных по каналу, обнаружение ошибок в канале и их коррекция.
Физический уровень (Physical) - физический интерфейс с каналом передачи данных, представление данных в виде физических сигналов и их кодирование (модуляция).
Инкапсуляция и обработка пакетов
При продвижении пакета данных по уровням сверху вниз каждый новый уровень добавляет к пакету свою служебную информацию в виде заголовка и, возможно, трейлера (информации, помещаемой в конец сообщения). Эта операция называется инкапсуляцией данных верхнего уровня в пакете нижнего уровня. Служебная информация предназначается для объекта того же уровня на удаленном компьютере, ее формат и интерпретация определяются протоколом данного уровня.
Разумеется, данные, приходящие с верхнего уровня, могут на самом деле представлять собой пакеты с уже инкапсулированными данными еще более верхнего уровня.
С другой стороны, при получении пакета от нижнего уровня он разделяется на заголовок (трейлер) и данные. Служебная информация из заголовка (трейлера) анализируется и в соответствии с ней данные, возможно, направляются одному из объектов верхнего уровня. Тот в свою очередь рассматривает эти данные как пакет со своей служебной информацией и данными для еще более верхнего уровня, и процедура повторяется, пока пользовательские данные, очищенные от всей служебной информации, не достигнут прикладного процесса.
Возможно, что пакет данных не будет доведен до самого верхнего уровня, например, в случае, если данный компьютер представляет собой промежуточную станцию на пути между отправителем и получателем. В этом случае объект соответствующего уровня при анализе служебной информации заметит, что пакет на этом уровне адресован не ему (хотя с точки зрения нижележащих уровней он был адресован именно этому компьютеру). Тогда объект выполнит необходимые действия для перенаправления пакета к месту назначения или возврата отправителю с сообщением об ошибке, но в любом случае не будет продвигать данные на верхний уровень.
Модель OSI предложена достаточно давно, однако протоколы, на ней основанные, используются редко, во-первых, в силу своей не всегда оправданной сложности, во-вторых, из-за существования хотя и не соответствующих строго модели OSI, но уже хорошо зарекомендовавших себя стеков протоколов (например, TCP/IP).
Поэтому модель OSI стоит рассматривать, в основном, как опорную базу для классификации и сопоставления протокольных стеков.
Стек протоколов TCP/IP
TCP/IP - собирательное название для набора (стека) сетевых протоколов разных уровней, используемых в Интернет. Особенности TCP/IP:
открытые стандарты протоколов, разрабатываемые независимо от программного и аппаратного обеспечения;
независимость от физической среды передачи;
система уникальной адресации;
стандартизованные протоколы высокого уровня для распространенных пользовательских сервисов.
Стек протоколов TCP/IP делится на 4 уровня: прикладной (application), транспортный (transport), межсетевой (internet) и уровень доступа к среде передачи (network access).
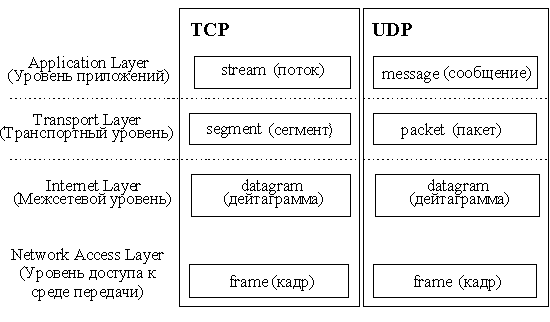
Рис. 73 Стек протоколов TCP/IP
Термины, применяемые для обозначения блока передаваемых данных, различны при использовании разных протоколов транспортного уровня – TCP и UDP, поэтому на рисунке 73 изображено два стека. Как и в модели OSI, данные более верхних уровней инкапсулируются в пакеты нижних уровней (см. рис. 74).
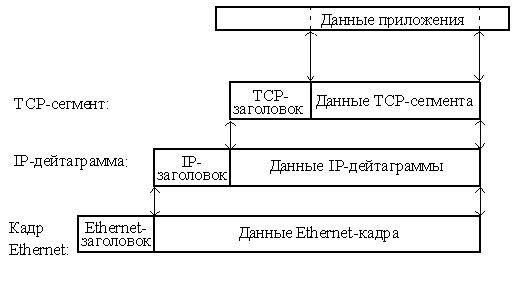
Рис. 74. Пример инкапсуляции пакетов в стеке TCP/IP
Примерное соотношение уровней стеков OSI и TCP/IP показано на рис. 75.
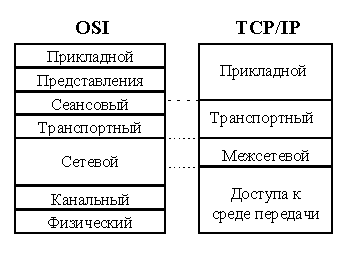
Рис. 75 Соотношение уровней стеков OSI и TCP/IP
Ниже кратко рассматриваются функции каждого уровня и примеры протоколов. Программа, реализующая функции того или иного протокола, часто называется модулем, например, “IP-модуль”, “модуль TCP”.
Уровень приложений
Приложения, работающие со стеком TCP/IP, могут также выполнять функции уровней представления и частично сеансового модели OSI; например, преобразование данных к внешнему представлению, группировка данных для передачи и т.п.
Распространенными примерами приложений являются программы telnet, ftp, HTTP-серверы и клиенты (WWW-броузеры), программы работы с электронной почтой.
Для пересылки данных другому приложению, приложение обращается к тому или иному модулю транспортного уровня.
Транспортный уровень
Протоколы транспортного уровня обеспечивают прозрачную (сквозную) доставку данных (end-to-end delivery service) между двумя прикладными процессами. Процесс, получающий или отправляющий данные с помощью транспортного уровня, идентифицируется на этом уровне номером, который называется номером порта. Таким образом, роль адреса отправителя и получателя на транспортном уровне выполняет номер порта (или проще - порт).
Анализируя заголовок своего пакета, полученного от межсетевого уровня, транспортный модуль определяет по номеру порта получателя, какому из прикладных процессов направлены данные, и передает эти данные соответствующему прикладному процессу (возможно, после проверки их на наличие ошибок и т.п.). Номера портов получателя и отправителя записываются в заголовок транспортным модулем, отправляющим данные; заголовок транспортного уровня содержит также и другую служебную информацию; формат заголовка зависит от используемого транспортного протокола.
На транспортном уровне работают два основных протокола: UDP и TCP.
TCP (Transmission Control Protocol – протокол контроля передачи) – надежный протокол с установлением соединения: он управляет логическим сеансом связи (устанавливает, поддерживает и закрывает соединение) между процессами и обеспечивает надежную (безошибочную и гарантированную) доставку прикладных данных от процесса к процессу.
Данными для TCP является не интерпретируемая протоколом последовательность пользовательских октетов, разбиваемая для передачи по частям. Каждая часть передается в отдельном TCP-сегменте. Для продвижения сегмента по сети между компьютером-отправителем и компьютером-получателем модуль TCP пользуется сервисом межсетевого уровня (вызывает модуль IP).
Все приложения, приведенные как пример в предыдущем пункте, пользуются услугами TCP.
Протокол UDP
UDP (User Datagram Protocol, протокол пользовательских дейтаграмм) фактически не выполняет каких-либо особых функций дополнительно к функциям межсетевого уровня (протокола IP). Протокол UDP используется либо при пересылке коротких сообщений, когда накладные расходы на установление сеанса и проверку успешной доставки данных оказываются выше расходов на повторную (в случае неудачи) пересылку сообщения, либо в том случае, когда сама организация процесса-приложения обеспечивает установление соединения и проверку доставки пакетов (например, NFS).
Пользовательские данные, поступившие от прикладного уровня, предваряются UDP-заголовком, и сформированный таким образом UDP-пакет отправляется на межсетевой уровень.
UDP-заголовок состоит из двух 32-битных слов:
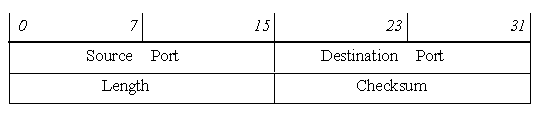
Значения полей:
Source Port – номер порта процесса-отправителя.
Destination Port – номер порта процесса-получателя.
Length – длина UDP-пакета вместе с заголовком в октетах.
Checksum – контрольная сумма. Контрольная сумма вычисляется таким же образом, как и в TCP-заголовке; если UDP-пакет имеет нечетную длину, то при вычислении контрольной суммы к нему добавляется нулевой октет.
После заголовка непосредственно следуют пользовательские данные, переданные модулю UDP прикладным уровнем за один вызов. Протокол UDP рассматривает эти данные как целостное сообщение; он никогда не разбивает сообщение для передачи в нескольких пакетах и не объединяет несколько сообщений для пересылки в одном пакете. Если прикладной процесс N раз вызвал модуль UDP для отправки данных (т.е. запросил отправку N сообщений), то модулем UDP будет сформировано и отправлено N пакетов, и процесс-получатель будет должен N раз вызвать свой модуль UDP для получения всех сообщений.
При получении пакета от межсетевого уровня модуль UDP проверяет контрольную сумму и передает содержимое сообщения прикладному процессу, чей номер порта указан в поле “Destination Port”.
Если проверка контрольной суммы выявила ошибку или если процесса, подключенного к требуемому порту, не существует, пакет игнорируется. Если пакеты поступают быстрее, чем модуль UDP успевает их обрабатывать, то поступающие пакеты также игнорируются. Протокол UDP не имеет никаких средств подтверждения безошибочного приема данных или сообщения об ошибке, не обеспечивает приход сообщений в порядке отправки, не производит предварительного установления сеанса связи между прикладными процессами, поэтому он является ненадежным протоколом без установления соединения. Если приложение нуждается в подобного рода услугах, оно должно использовать на транспортном уровне протокол TCP.
Максимальная длина UDP-сообщения равна максимальной длине IP-дейтаграммы (65535 октетов) за вычетом минимального IP-заголовка (20) и UDP-заголовка (8), т.е. 65507 октетов. На практике обычно используются сообщения длиной 8192 октета.
Примеры прикладных процессов, использующих протокол UDP: NFS (Network File System - сетевая файловая система), TFTP (Trivial File Transfer Protocol - простой протокол передачи файлов), SNMP (Simple Network Management Protocol - простой протокол управления сетью), DNS (Domain Name Service - доменная служба имен)
Межсетевой уровень и протокол IP
Основным протоколом этого уровня является протокол IP (Internet Protocol).
Протокол IP доставляет блоки данных, называемых дейтаграммами, от одного IP-адреса к другому. IP-адрес является уникальным 32-битным идентификатором компьютера (точнее, его сетевого интерфейса). Данные для дейтаграммы передаются IP-модулю транспортным уровнем. IP-модуль предваряет эти данные заголовком, содержащим IP-адреса отправителя и получателя и другую служебную информацию, и сформированная таким образом дейтаграмма передается на уровень доступа к среде передачи (например, одному из физических интерфейсов) для отправки по каналу передачи данных.
Не все компьютеры могут непосредственно связаться друг с другом; часто для того, чтобы передать дейтаграмму по назначению, требуется направить ее через один или несколько промежуточных компьютеров по тому или иному маршруту. Задача определения маршрута для каждой дейтаграммы решается протоколом IP.
Когда модуль IP получает дейтаграмму с нижнего уровня, он проверяет IP-адрес назначения. Если дейтаграмма адресована данному компьютеру, то данные из нее передаются на обработку модулю вышестоящего уровня (какому конкретно – указано в заголовке дейтаграммы). Если же адрес назначения дейтаграммы – чужой, то модуль IP может принять два решения: первое - уничтожить дейтаграмму, второе – отправить ее дальше к месту назначения, определив маршрут следования – так поступают промежуточные станции – маршрутизаторы.
Также может потребоваться, на границе сетей с различными характеристиками, разбить дейтаграмму на фрагменты, а потом собрать в единое целое на компьютере-получателе. Это тоже задача протокола IP.
Если модуль IP по какой-либо причине не может доставить дейтаграмму, она уничтожается. При этом модуль IP может отправить компьютеру-источнику этой дейтаграммы уведомление об ошибке; такие уведомления отправляются с помощью протокола ICMP, являющегося неотъемлемой частью модуля IP. Более никаких средств контроля корректности данных, подтверждения их доставки, обеспечения правильного порядка следования дейтаграмм, предварительного установления соединения между компьютерами протокол IP не имеет. Эта задача возложена на транспортный уровень.
Многие IP-адреса имеют эквивалентную форму записи в виде доменного имени (например, IP-адрес 194.84.124.4 может быть записан как maria.vvsu.ru). Преобразование между этими двумя формами выполняется службой DNS (Domain Name Service). Доменные имена обсуждаются в курсе “Введение в Интернет”, служба DNS рассматривается в курсе “Технологии Интернет”. Доменные имена введены для удобства использования человеком. Все TCP/IP-процессы и коммуникационное оборудование используют только IP-адреса.
Уровень доступа к среде передачи
Функции этого уровня:
отображение IP-адресов в физические адреса сети (MAC-адреса, например, Ethernet-адрес в случае сети Ethernet). Эту функцию выполняет протокол ARP;
инкапсуляция IP-дейтаграмм в кадры для передачи по физическому каналу и извлечение дейтаграмм из кадров. При этом не требуется какого-либо контроля безошибочности передачи (хотя он может и присутствовать), поскольку в стеке TCP/IP такой контроль возложен на транспортный уровень или на само приложение. В заголовке кадров указывается точка доступа к сервису (SAP, Service Access Point) – поле, содержащее код протокола межсетевого уровня, которому следует передать содержимое кадра (в нашем случае это протокол IP);
определение метода доступа к среде передачи – то есть способа, с помощью которого компьютер устанавливает свое право на произведение передачи данных (передача токена, опрос компьютеров, множественный доступ с детектированием коллизий и т.п.).
определение представления данных в физической среде;
пересылка и прием кадра.
Стек TCP/IP не подразумевает использования каких-либо определенных протоколов уровня доступа к среде передачи и физических сред передачи данных. От уровня доступа к среде передачи требуется наличие интерфейса с модулем IP, обеспечивающего передачу дейтаграммы между уровнями. Также требуется обеспечить преобразование IP-адреса узла сети, на который передается дейтаграмма, в MAC-адрес. Часто в качестве уровня доступа к среде передачи могут выступать целые протокольные стеки, тогда говорят об IP поверх ATM, IP поверх IPX, IP поверх X.25 и т.п.
Навигация в сети ИНТЕРНЕТ
Поисковые системы в сети Интернет
Основные протоколы, используемые в Интернет (в дальнейшем также Сеть), не обеспечены достаточными встроенными функциями поиска, не говоря уже о миллионах серверах, находящихся в ней. Протокол HTTP, используемый в Интернет, хорош лишь в отношении навигации, которая рассматривается только как средство просмотра страниц, но не их поиска. То же самое относится и к протоколу FTP, который даже более примитивен, чем HTTP. Из-за быстрого роста информации, доступной в Сети, навигационные методы просмотра быстро достигают предела их функциональных возможностей, не говоря уже о пределе их эффективности. Не указывая конкретных цифр, можно сказать, что нужную информацию уже не представляется возможным получить сразу, так как в Сети сейчас находятся миллиарды документов и все они в распоряжении пользователей Интернет, к тому же сегодня их количество возрастает согласно экспоненциальной зависимости. Количество изменений, которым эта информация подвергнута, огромно и, самое главное, они произошли за очень короткий период времени. Основная проблема заключается в том, что единой полной функциональной системы обновления и занесения подобного объема информации, одновременно доступного всем пользователям Интернет во всем мире, никогда не было. Для того чтобы структурировать информацию, накопленную в сети Интернет, и обеспечить ее пользователей удобными средствами поиска необходимых им данных, были созданы поисковые системы.
Поисковые системы
Поисковые системы обычно состоят из трех компонент:
агент (паук или гроулер), который перемещается по Сети и собирает информацию;
база данных, которая содержит всю информацию, собираемую пауками;
поисковый механизм, который люди используют как интерфейс для взаимодействия с базой данных.
Как работают механизмы поиска
Средства поиска и структурирования, иногда называемые поисковыми механизмами, используются для того, чтобы помочь людям найти информацию, в которой они нуждаются. Средства поиска типа агентов, пауков, гроулеров и роботов используются для сбора информации о документах, находящихся в Сети Интернет. Это специальные программы, которые занимаются поиском страниц в Сети, извлекают гипертекстовые ссылки на этих страницах и автоматически индексируют информацию, которую они находят для построения базы данных. Каждый поисковый механизм имеет собственный набор правил, определяющих, как собирать документы. Некоторые следуют за каждой ссылкой на каждой найденной странице и затем, в свою очередь, исследуют каждую ссылку на каждой из новых страниц, и так далее. Некоторые игнорируют ссылки, которые ведут к графическим и звуковым файлам, файлам мультипликации; другие игнорируют ссылки к ресурсам типа баз данных WAIS; другие проинструктированы, что нужно просматривать прежде всего наиболее популярные страницы.
Агенты – самые "интеллектуальные" из поисковых средств. Они могут делать больше, чем просто искать: они могут выполнять даже транзакции от Вашего имени. Уже сейчас они могут искать cайты специфической тематики и возвращать списки cайтов, отсортированных по их посещаемости. Агенты могут обрабатывать содержание документов, находить и индексировать другие виды ресурсов, не только страницы. Они могут также быть запрограммированы для извлечения информации из уже существующих баз данных. Независимо от информации, которую агенты индексируют, они передают ее обратно базе данных поискового механизма.
Общий поиск информации в Сети осуществляют программы, известные как пауки. Пауки сообщают о содержании найденного документа, индексируют его и извлекают итоговую информацию. Также они просматривают заголовки, некоторые ссылки и посылают проиндексированную информацию базе данных поискового механизма.
Гроулеры просматривают заголовки и возвращают только первую ссылку.
Роботы могут быть запрограммированы так, чтобы переходить по различным ссылкам различной глубины вложенности, выполнять индексацию и даже проверять ссылки в документе. Из-за их природы они могут застревать в циклах, поэтому, проходя по ссылкам, им нужны значительные ресурсы Сети. Однако имеются методы, предназначенные для того, чтобы запретить роботам поиск по сайтам, владельцы которых не желают, чтобы они были проиндексированы.
Агенты извлекают и индексируют различные виды информации. Некоторые, например, индексируют каждое отдельное слово во встречающемся документе, в то время как другие индексируют только наиболее важных 100 слов в каждом, индексируют размер документа и число слов в нем, название, заголовки и подзаголовки и так далее. Вид построенного индекса определяет, какой поиск может быть сделан поисковым механизмом и как полученная информация будет интерпретирована.
Агенты могут также перемещаться по Интернет и находить информацию, после чего помещать ее в базу данных поискового механизма. Администраторы поисковых систем могут определить, какие сайты или типы сайтов агенты должны посетить и проиндексировать. Проиндексированная информация отсылается базе данных поискового механизма так же, как было описано выше.
Люди могут помещать информацию прямо в индекс, заполняя особую форму для того раздела, в который они хотели бы поместить свою информацию. Эти данные передаются базе данных.
Когда кто-либо хочет найти информацию, доступную в Интернет, он посещает страницу поисковой системы и заполняет форму, детализирующую информацию, которая ему необходима. Здесь могут использоваться ключевые слова, даты и другие критерии. Критерии в форме поиска должны соответствовать критериям, используемым агентами при индексации информации, которую они нашли при перемещении по Сети.
База данных отыскивает предмет запроса, основанный на информации, указанной в заполненной форме, и выводит соответствующие документы, подготовленные базой данных. Чтобы определить порядок, в котором список документов будет показан, база данных применяет алгоритм ранжирования. В идеальном случае, документы, наиболее релевантные пользовательскому запросу будут помещены первыми в списке. Различные поисковые системы используют различные алгоритмы ранжирования, однако основные принципы определения релевантности следующие:
Количество слов запроса в текстовом содержимом документа (т.е. в html-коде).
Тэги, в которых эти слова располагаются.
Местоположение искомых слов в документе.
Удельный вес слов, относительно которых определяется релевантность, в общем количестве слов документа.
Эти принципы применяются всеми поисковыми системами. А представленные ниже используются некоторыми, но достаточно известными (вроде AltaVista, HotBot).
Время - как долго страница находится в базе поискового сервера. Поначалу кажется, что это довольно бессмысленный принцип. Но, если задуматься, как много существует в Интернете сайтов, которые живут максимум месяц! Если же сайт существует довольно долго, это означает, что владелец весьма опытен в данной теме и пользователю больше подойдет сайт, который пару лет вещает миру о правилах поведения за столом, чем тот, который появился неделю назад с этой же темой.
Индекс цитируемости – как много ссылок на данную страницу ведет с других страниц, зарегистрированных в базе поисковика.
База данных выводит ранжированный подобным образом список документов с HTML и возвращает его человеку, сделавшему запрос. Различные поисковые механизмы также выбирают различные способы показа полученного списка – некоторые показывают только ссылки; другие выводят ссылки c первыми несколькими предложениями, содержащимися в документе или заголовок документа вместе со ccылкой.
Когда Вы щелкаете на ссылке к одному из документов, который вас интересует, этот документ запрашивается у того сервера, на котором он находится.
Сравнительный обзор поисковых систем
Lycos. В Lycos используется следующий механизм индексации:
слова в <title> заголовке имеют высший приоритет;
слова в начале страницы;
слова в ссылках;
если в его базе индекса есть сайты, ссылка с которых указывает на индексируемый документ – релевантность этого документа возрастает.
Как и большинство систем, Lycos дает возможность применять простой запрос и более изощренный метод поиска. В простом запросе в качестве поискового критерия вводится предложение на естественном языке, после чего Lycos производит нормализацию запроса, удаляя из него так называемые stop-слова, и только после этого приступает к его выполнению. Почти сразу выдается информация о количестве документов на каждое слово, а позже и список ссылок на формально релевантные документы. В списке против каждого документа указывается его мера близости запросу, количество слов из запроса, попавших в документ, и оценочная мера близости, которая может быть больше или меньше формально вычисленной. Пока нельзя вводить логические операторы в строке вместе с терминами, но использовать логику через систему меню Lycos позволяет. Такая возможность применяется для построения расширенной формы запроса, предназначенной для искушенных пользователей, уже научившихся работать с этим механизмом. Таким образом, видно, что Lycos относится к системе с языком запросов типа "Like this", но намечается его расширение и на другие способы организации поисковых предписаний.
AltaVista. Индексирование в этой системе осуществляется при помощи робота. При этом робот имеет следующие приоритеты:
слова содержащиеся в теге <title> имеют высший приоритет; ключевые фразы в <Meta> тэгах;
ключевые фразы, находящиеся в начале странички;
ключевые фразы в ALT - ссылках
ключевые фразы по количеству вхождений\присутствия слов\фраз;
Если тэгов на странице нет, использует первые 30 слов, которые индексирует и показывает вместо описания (tag description)
Наиболее интересная возможность AltaVista - это расширенный поиск. Здесь стоит сразу оговориться, что, в отличие от многих других систем AltaVista поддерживает одноместный оператор NOT. Кроме этого, имеется еще и оператор NEAR, который реализует возможность контекстного поиска, когда термины должны располагаться рядом в тексте документа. AltaVista разрешает поиск по ключевым фразам, при этом она имеет довольно большой фразеологический словарь. Кроме всего прочего, при поиске в AltaVista можно задать имя поля, где должно встретиться слово: гипертекстовая ссылка, applet, название образа, заголовок и ряд других полей. К сожалению, подробно процедура ранжирования в документации по системе не описана, но видно, что ранжирование применяется как при простом поиске, так и при расширенном запросе. Реально эту систему можно отнести к системе с расширенным булевым поиском.
Yahoo. Данная система появилась в Сети одной из первых, и сегодня Yahoo сотрудничает со многими производителями средств информационного поиска, а на различных ее серверах используется различное программное обеспечение. Язык Yahoo достаточно прост: все слова следует вводить через пробел, они соединяются связкой AND либо OR. При выдаче не указывается степень соответствия документа запросу, а только подчеркиваются слова из запроса, которые встретились в документе. При этом не производится нормализация лексики и не проводится анализ на "общие" слова. Хорошие результаты поиска получаются только тогда, когда пользователь знает, что в базе данных Yahoo информация есть наверняка. Ранжирование производится по числу терминов запроса в документе. Yahoo относится к классу простых традиционных систем с ограниченными возможностями поиска.
OpenText. Информационная система OpenText представляет собой самый коммерциализированный информационный продукт в Сети. Все описания больше похожи на рекламу, чем на информативное руководство по работе. Система позволяет провести поиск с использованием логических коннекторов, однако размер запроса ограничен тремя терминами или фразами. В данном случае речь идет о расширенном поиске. При выдаче результатов сообщается степень соответствия документа запросу и размер документа. Система позволяет также улучшить результаты поиска в стиле традиционного булевого поиска. OpenText можно было бы отнести к разряду традиционных информационно-поисковых систем, если бы не механизм ранжирования.
Infoseek. В этой системе индекс создает робот, но он индексирует не весь сайт, а только указанную страницу. При этом робот имеет такие приоритеты:
слова в заголовке <title> имеют наивысший приоритет;
слова в теге keywords, description и частота вхождений\повторений в самом тексте;
при повторении одинаковых слов рядом выбрасывает из индекса
Допускает до 1024 символов для тега keywords, 200 символов для тэга description;
Если тэги не использовались, индексирует первые 200 слов на странице и использует как описание;
Система Infoseek обладает довольно развитым информационно-поисковым языком, позволяющим не просто указывать, какие термины должны встречаться в документах, но и своеобразно взвешивать их. Достигается это при помощи специальных знаков "+" - термин обязан быть в документе, и "-" - термин должен отсутствовать в документе. Кроме этого, Infoseek позволяет проводить то, что называется контекстным поиском. Это значит, что используя специальную форму запроса, можно потребовать последовательной совместной встречаемости слов. Также можно указать, что некоторые слова должны совместно встречаться не только в одном документе, а даже в отдельном параграфе или заголовке. Имеется возможность указания ключевых фраз, представляющих собой единое целое, вплоть до порядка слов. Ранжирование при выдаче осуществляется по числу терминов запроса в документе, по числу фраз запроса за вычетом общих слов. Все эти факторы используются как вложенные процедуры. Подводя краткое резюме, можно сказать, что Infoseek относится к традиционным системам с элементом взвешивания терминов при поиске.
WAIS. WAIS является одной из наиболее изощренных поисковых систем Internet. В ней не реализованы лишь поиск по нечетким множествам и вероятностный поиск. В отличие от многих поисковых машин, система позволяет строить не только вложенные булевые запросы, считать формальную релевантность по различным мерам близости, взвешивать термины запроса и документа, но и осуществлять коррекцию запроса по релевантности. Система также позволяет использовать усечения терминов, разбиение документов на поля и ведение распределенных индексов. Не случайно именно эта система была выбрана в качестве основной поисковой машины для реализации энциклопедии "Британика" на Internet.
Поисковые роботы
За последние годы Всемирная паутина стала настолько популярной, что сейчас Интернет является одним из основных средств публикации информации. Когда размер Сети вырос из нескольких серверов и небольшого числа документов до огромных пределов, стало ясно, что ручная навигация по значительной части структуры гипертекстовых ссылок больше не представляется возможной, не говоря уже об эффективном методе исследования ресурсов.
Эта проблема побудила исследователей Интернет на проведение экспериментов с автоматизированной навигацией по Сети, названной "роботами". Веб-робот – это программа, которая перемещается по гипертекстовой структуре Сети, запрашивает документ и рекурсивно возвращает все документы, на которые данный документ ссылается. Эти программы также иногда называют "пауками", " странниками", или " червями" и эти названия, возможно, более привлекательны, однако, могут ввести в заблуждение, поскольку термин "паук" и "странник" создает ложное представление, что робот сам перемещается, а термин "червь" мог бы подразумевать, что робот еще и размножается подобно интернетовскому вирусу-червю. В действительности, роботы реализованы как простая программная система, которая запрашивает информацию из удаленных участков Интернет, используя стандартные cетевые протоколы.
Роботы могут использоваться для выполнения множества полезных задач, таких как статистический анализ, обслуживание гипертекстов, исследования ресурсов или зазеркаливания страниц. Рассмотрим эти задачи подробнее.
Первый робот был создан для того, чтобы обнаружить и посчитать количество веб-серверов в Сети. Другие статистические вычисления могут включать среднее число документов, приходящихся на один сервер в Сети, пропорции определенных типов файлов на сервере, средний размер страницы, степень связанности ссылок и т.д.
Обслуживание гипертекстов
Одной из главных трудностей в поддержании гипертекстовой структуры является то, что ссылки на другие страницы могут становиться " мертвыми ссылками" в случае, когда страница переносится на другой сервер или cовсем удаляется. На сегодняшний день не существует общего механизма, который смог бы уведомить обслуживающий персонал сервера, на котором содержится документ со ссылками на подобную страницу, о том, что она изменилась или вообще удалена. Некоторые серверы, например, CERN HTTPD, будут регистрировать неудачные запросы, вызванные мертвыми ссылками наряду с рекомендацией относительно страницы, где обнаружена мертвая cсылка, предусматривая что данная проблема будет решаться вручную. Это не очень практично, и в действительности авторы документов обнаруживают, что их документы содержат мертвые ссылки лишь тогда, когда их извещают непосредственно, или, что бывает очень редко, когда пользователь сам уведомляет их по электронной почте.
Робот типа MOMSPIDER, который проверяет ссылки, может помочь автору документа в обнаружении подобных мертвых ссылок, и также может помогать в обслуживании гипертекстовой структуры. Также роботы могут помочь в поддержании содержания и самой структуры, проверяя соответствующий HTML-документ, его соответствие принятым правилам, регулярные модернизации, и т.д., но это обычно не используется. Возможно, данные функциональные возможности должны были бы быть встроены при написании окружающей среды HTML-документа, поскольку эти проверки могут повторяться в тех случаях, когда документ изменяется, и любые проблемы при этом могут быть решены немедленно.
Зазеркаливание
Зазеркаливание – популярный механизм поддержания FTP архивов. Зеркало рекурсивно копирует полное дерево каталогов по FTP, и затем регулярно перезапрашивает те документы, которые изменились. Это позволяет распределить загрузку между несколькими серверами, успешно справиться с отказами сервера и обеспечить более быстрый и более дешевый локальный доступ, так же как и автономный доступ к архивам. В Сети Интернет зазеркаливание может быть осуществлено с помощью робота, однако на время написания этой статьи никаких сложных средств для этого не существовало. Конечно, существует несколько роботов, которые восстанавливают поддерево страниц и сохраняют его на локальном сервере, но они не имеют средств для обновления именно тех страниц, которые изменились. Вторая проблема - это уникальность страниц, которая состоит в том, что ссылки в скопированных страницах должны быть перезаписаны там, где они ссылаются на страницы, которые также были зазеркалены и могут нуждаться в обновлении. Они должны быть измененены на копии, а там, где относительные ссылки указывают на страницы, которые не были зазеркалены, они должны быть расширены до абсолютных ссылок. Потребность в механизмах зазеркаливания по причинам показателей производительности намного уменьшается применением сложных кэширующих серверов, которые предлагают выборочную модернизацию, что может гарантировать, что кэшированный документ не обновился, и в значительной степени самообслуживается. Однако, ожидается, что средства зазеркаливания в будущем будут развиваться должным образом.
Исследование ресурсов
Возможно, наиболее захватывающее применение роботов – использование их при исследовании ресурсов. Там, где люди не могут справиться с огромным количеством информации, довольно возможность переложить всю работу на компьютер выглядит довольно привлекательно. Существует несколько роботов, которые собирают информацию в большей части Интернет и передают полученные результаты базе данных. Это означает, что пользователь, который ранее полагался исключительно на ручную навигацию в Сети, теперь может объединить поиск с просмотром страниц для нахождения нужной ему информации. Даже если база данных не содержит именно того, что ему нужно, велика вероятность того, что в результате этого поиска будет найдено немало ссылок на страницы, которые, в свою очередь, могут ссылаться на предмет его поиска.
Второе преимущество состоит в том, что эти базы данных могут автоматически обновляться за определенный период времени так, чтобы мертвые ссылки в базе данных были обнаружены и удалены, в отличие от обслуживания документов вручную, когда проверка часто является спонтанной и не полной. Использование роботов для исследования ресурсов будет обсуждаться ниже.
Простой робот может выполнять более чем одну из вышеупомянутых задач. Например, робот RBSE Spider выполняет статистический анализ запрошенных документов и обеспечивает ведение базы данных ресурсов. Однако, подобное комбинированное использование встречается, к сожалению, весьма редко.
Использование роботов может дорого обойтись, особенно в случае, когда они используются удаленно в Интернете. В этом разделе мы увидим, что роботы могут быть опасны, так как они предъявляют слишком высокие требования к Сети.
Сетевой ресурс и загрузка сервера
Роботы требуют значительной пропускной способности канала сервера. Во-первых, роботы работают непрерывно в течение длительных периодов времени, часто даже в течение месяцев. Чтобы ускорить операции, многие роботы делают параллельные запросы страниц с сервера, ведущие в последствии к повышенному использованию пропускной способности канала сервера. Даже удаленные части Сети могут чувствовать сетевую нагрузку на ресурс, если робот делает большое количество запросов за короткий промежуток времени. Это может привести к временной нехватке пропускной способности сервера для других пользователей, особенно на серверах с низкой пропускной способностью, поскольку Интернет не имеет никаких средств для балансирования нагрузки в зависимости от используемого протокола.
Традиционно Интернет воспринимался как "свободный", поскольку индивидуальные пользователи не должны были платить за его использование. Однако теперь это поставлено под сомнение, так как особенно корпоративные пользователи платят за издержки, связанные с использованием Сети. Компания может чувствовать, что ее услуги (потенциальным) клиентам стоят оплаченных денег, а страницы, автоматически переданные роботам – нет.
Помимо предъявления требований к Сети, робот также предъявляет дополнительные требования к самому серверу. В зависимости от частоты, с которой он запрашивает документы с сервера, это может привести к значительной загрузке всего сервера и снижению скорости доступа других пользователей, обращающихся к серверу. К тому же, если главный компьютер используется также для других целей, это может быть вообще неприемлемо. В качестве эксперимента автор управлял моделированием 20 параллельных запросов от своего сервера, функционирующего как Plexus сервер на Sun 4/330. Несколько минут машину, замедленную использованием паука, вообще невозможно было использовать. Этот эффект можно почувствовать даже последовательно запрашивая страницы.
Все это показывает, что нужно избегать ситуаций с одновременным запросом страниц. К сожалению, даже современные браузеры (например, Netscape) создают эту проблему, параллельно запрашивая изображения, находящиеся в документе. Сетевой протокол HTTP оказался неэффективным для подобных передач и как средство борьбы с подобными эффектами сейчас разрабатываются новые протоколы.
Обновление документов
Как уже было упомянуто, базы данных, создаваемые роботами, могут автоматически обновляться. К сожалению, до сих пор не имеется никаких эффективных механизмов контроля за изменениями, происходящими в Сети. Более того, нет даже простого запроса, который мог бы определить, которая из cсылок была удалена, перемещена или изменена. Протокол HTTP обеспечивает механизм "If-Modified-Since", посредством которого агент пользователя может определить время модификации кэшированного документа одновременно с запросом самого документа. Если документ был изменен, тогда сервер передаст только его содержимое, так как этот документ уже был прокэширован.
Это средство может использоваться роботом только в том случае, если он сохраняет отношения между итоговыми данными, которые извлекаются из документа: это сама ссылка и отметка о времени, когда документ запрашивался. Это ведет к возникновению дополнительных требований к размеру и сложности базы данных и широко не применяется.
Роботы / агенты клиента
Загрузка Сети является особой проблемой, связанной с применением категории роботов, которые используются конечными пользователями и реализованы как часть веб-клиента общего назначения (например, Fish Search и tkWWW робот). Одной из особенностей, которая является обычной для этих роботов, является способность передавать обнаруженную информацию поисковым системам при перемещении по Сети. Это преподносится как усовершенствование методов исследования ресурсов, так как запросы к нескольким удаленным базам данных осуществляются автоматически. Однако, по мнению автора, это неприемлемо по двум причинам. Во-первых, операция поиска приводит к большей загрузке сервера, чем даже простой запрос документа, поэтому обычному пользователю могут быть причинены значительные неудобства при работе на нескольких серверах с большими издержками, чем обычно. Во-вторых, ошибочно предполагать, что одни и те же ключевые слова при поиске одинаково релевантны, синтаксически правильны, не говоря уже об оптимальности для различных баз данных, и диапазон баз данных полностью скрыт от пользователя. Например, запрос " Форд и гараж " мог бы быть послан базе данных, хранящей литературу 17-ого столетия, базе данных, которая не поддерживает булевские операторы или базе данных, которая определяет, что запросы относительно автомобилей должны начаться со слова "автомобиль:". И пользователь даже не знает это.
Другой опасный аспект использования клиентского робота заключается в том, что как только он был распространен по Сети, никакие ошибки уже не могут быть исправлены, не могут быть добавлены никакие знания проблемных областей, и никакие новые эффективные свойства не могут его улучшить, как не каждый пользователь впоследствии будет модернизировать этого робота самой последней версией.
Наиболее опасный аспект, однако – большое количество возможных пользователей роботов. Некоторые люди, вероятно, будут использовать такое устройство здраво, то есть ограничиваться некоторым максимумом ссылок в известной области Сети и в течение короткого периода времени, но найдутся и люди, которые злоупотребят им из-за невежества или высокомерия. По мнению автора, удаленные роботы не должны передаваться конечным пользователям, и к счастью, до сих пор удавалось убедить, по крайней мере, некоторых авторов роботов, не распространять их открыто.
Даже не учитывая потенциальную опасность клиентских роботов, возникает этический вопрос: где использование роботов может быть полезно всему Интернет-сообществу для объединения всех доступных данных, а где они не могут быть применены, поскольку принесут пользу только одному пользователю.
"Интеллектуальные агенты" и " цифровые помощники", предназначенные для использования конечным пользователем, который ищет информацию в Интернет, являются в настоящее время популярной темой исследований в компьютерной науке, и часто рассматриваются как будущее Сети. В то же время это действительно может иметь место, и уже очевидно, что автоматизация неоценима для исследований ресурсов, хотя требуется проводить еще больше исследований для того, чтобы их сделать их использование эффективным. Простые управляемые пользователем роботы очень далеки от интеллектуальных сетевых агентов: агент должен иметь некоторое представление о том, где найти определенную информацию (то есть какие услуги использовать) вместо того, чтобы искать ее вслепую. Рассмотрим ситуацию, когда человек ищет книжный магазин; он использует "Желтые страницы" для области, в которой он проживает, находит список магазинов, выбирает из них один или несколько, и посещает их. Клиентский робот шел бы во все магазины в области, спрашивая о книгах. В Сети, как и в реальной жизни, это неэффективно в малом масштабе, и совсем должно быть запрещено в больших масштабах.
Плохие программные реализации роботов
Нагрузка на сеть и серверы иногда увеличивается плохой программной реализацией особенно недавно написанных роботов. Даже если протокол и ссылки, посланные роботом, правильны, и робот правильно обрабатывает возвращенный протокол (включая другие особенности вроде переназначения), имеется несколько менее очевидных проблем.
Можно наблюдать, как несколько похожих роботов управляют вызовом его сервера. В то время как в некоторых случаях негативные последствия были вызваны людьми, использующими свой сайт для испытаний (вместо локального сервера), в остальных случаях стало очевидно, что они были вызваны плохим написанием самого робота. При этом могут произойти повторные запросы страниц в том случае, если нет никаких записей об уже запрошенных ссылках (что является непростительным), или когда робот не распознает, когда несколько ссылок синтаксически эквивалентны, например, где различаются DNS псевдонимы для одного и того же адреса IP, или где ссылки не могут быть обработаны роботом, например " foo/bar/ ../baz.html " является эквивалентным "foo/baz.html".
Некоторые роботы иногда запрашивают документы типа GIF и PS, которые они не могут обработать и поэтому игнорируют.
Другая опасность состоит в том, что некоторые области Сети являются почти бесконечными. Например, рассмотрим сценарий, который возвращает страницу со ссылкой на один уровень, расположенный ниже. Он начнет, например, с " /cgi-bin/pit / ", и продолжит с " /cgi-bin/pit/a / ", " /cgi-bin/pit/a/a / ", и т.д. Поскольку такие ссылки могут заманить в робота в ловушку, их часто называют "черными дырами".
Проблемы при каталогизации информации
Бесспорен тот факт, что базы данных, наполняемые роботами, популярны. Однако имеется несколько проблем, которые ограничивают применение роботов для исследования ресурсов в Сети. Одна из них заключается в том, что здесь находится слишком много документов, и все они постоянно динамически изменяются.
Одной из мер эффективности подхода к поиску информации является "отзыв" (recall), содержащий информацию о всех релевантных документах, которые были найдены. Брайен Пинкертон утверждает, что отзыв в индексирующих системах Интернет является вполне приемлемым подходом, так как обнаружение достаточно релевантных документов не проблема. Однако, если сравнивать все множество информации, доступной в Интернет, с информацией в базе данных, созданной роботом, то отзыв не может быть слишком точным, поскольку количество информации огромно и она очень часто изменяется. Так что практически база данных может не содержать специфического ресурса, который доступен в Интернет в данный момент, и таких документов будет множество, поскольку Сеть непрерывно растет.
Определение роботом, какую информацию включать / исключать
Робот не может автоматически определить, была ли данная страница в Сети включена в его индекс. К тому же веб-сервера в Интернет могут содержать документы, которые являются релевантными только для локального контекста, документы, которые существуют временно, и т.д. На практике роботы сохраняют почти всю информацию о том, где они побывали. Заметьте, что, даже если робот смог определить, должна ли указанная страница быть исключена из его базы данных, он уже понес накладные расходы на запрос самого файла, а робот, который решает игнорировать большой процент документов, очень расточителен. Пытаясь исправить эту ситуацию, Интернет-сообщество приняло " Стандарт исключений для роботов". Этот стандарт описывает использование простого структурированного текстового файла, доступного в известном месте на сервере ("/robots.txt") и используемого для того, чтобы определить, какая из частей их ссылок должна игнорироваться роботами. Это средство может быть также использовано для того, чтобы предупредить роботов о черных дырах. Каждому типу роботов можно передавать определенные команды, если известно, что данный робот специализируется в конкретной области. Этот стандарт является свободным, но его очень просто осуществить и в нем имеется значительное давление на роботов с попыткой их подчинения.
Формат файла /robots.txt.
Файл /robots.txt предназначен для указания всем поисковым роботам индексировать информационные сервера так, как определено в этом файле, т.е. только те директории и файлы сервера, которые НЕ описаны в /robots.txt. Этот файл должен содержать 0 или более записей, которые связаны с тем или иным роботом (что определяется значением поля agent_id), и указывают для каждого робота или для всех сразу что именно им НЕ НАДО индексировать. Тот, кто пишет файл /robots.txt, должен указать подстроку Product Token поля User-Agent, которую каждый робот выдает на HTTP-запрос индексируемого сервера. Например, нынешний робот Lycos на такой запрос выдает в качестве поля User-Agent:
Lycos_Spider_(Rex)/1.0 libwww/3.1
Если робот Lycos не нашел своего описания в /robots.txt – он поступает так, как считает нужным. При создании файла /robots.txt следует учитывать еще один фактор – размер файла. Поскольку описывается каждый файл, который не следует индексировать, да еще для многих типов роботов отдельно, при большом количестве не подлежащих индексированию файлов размер /robots.txt становится слишком большим. В этом случае следует применять один или несколько следующих способов сокращения размера /robots.txt:
указывать директорию, которую не следует индексировать, и, соответственно, не подлежащие индексированию файлы располагать именно в ней
создавать структуру сервера с учетом упрощения описания исключений в /robots.txt
указывать один способ индексирования для всех agent_id
указывать маски для директорий и файлов
Записи файла /robots.txt
Общее описание формата записи.
[ # comment string NL ]*
User-Agent: [ [ WS ]+ agent_id ]+ [ [ WS ]* # comment string ]? NL
[ # comment string NL ]*
Disallow: [ [ WS ]+ path_root ]* [ [ WS ]* # comment string ]? NL
[
# comment string NL
|
Disallow: [ [ WS ]+ path_root ]* [ [ WS ]* # comment string ]? NL
]*
[ NL ]+
Параметры
Описание параметров, применяемых в записях /robots.txt
[...]+ Квадратные скобки со следующим за ними знаком + означают, что в качестве параметров должны быть указаны один или несколько терминов. Например, после "User-Agent:" через пробел могут быть указаны один или несколько agent_id.
[...]* Квадратные скобки со следующим за ними знаком * означают, что в качестве параметров могут быть указаны ноль или несколько терминов. Например, Вы можете писать или не писать комментарии.
[...]? Квадратные скобки со следующим за ними знаком ? означают, что в качестве параметров могут быть указаны ноль или один термин. Например, после "User-Agent: agent_id" может быть написан комментарий.
..|.. означает или то, что до черты, или то, что после.
WS один из символов - пробел (011) или табуляция (040)
NL один из символов - конец строки (015) , возврат каретки (012) или оба этих символа (Enter)
User-Agent: ключевое слово (заглавные и прописные буквы роли не играют). Параметрами являются agent_id поисковых роботов.
Disallow: ключевое слово (заглавные и прописные буквы роли не играют). Параметрами являются полные пути к неиндексируемым файлам или директориям.
# начало строки комментариев, comment string - собственно тело комментария.
agent_id любое количество символов, не включающих WS и NL, которые определяют agent_id различных поисковых роботов. Знак * определяет всех роботов сразу.
path_root любое количество символов, не включающих WS и NL, которые определяют файлы и директории, не подлежащие индексации.
Расширенные комментарии формата.
Каждая запись начинается со строки User-Agent, в которой описывается каким или какому поисковому роботу эта запись предназначается. Следующая строка: Disallow. Здесь описываются не подлежащие индексации пути и файлы. КАЖДАЯ запись ДОЛЖНА иметь как минимум эти две строки (lines). Все остальные строки являются опциями. Запись может содержать любое количество строк комментариев. Каждая строка комментария должна начинаться с символа # . Строки комментариев могут быть помещены в конец строк User-Agent и Disallow. Символ # в конце этих строк иногда добавляется для того, чтобы указать поисковому роботу, что длинная строка agent_id или path_root закончена. Если в строке User-Agent указано несколько agent_id, то условие path_root в строке Disallow будет выполнено для всех одинаково. Ограничений на длину строк User-Agent и Disallow нет. Если поисковый робот не обнаружил в файле /robots.txt своего agent_id, то он игнорирует /robots.txt.
Если не учитывать специфику работы каждого поискового робота, можно указать исключения для всех роботов сразу. Это достигается заданием строки
User-Agent: *
Если поисковый робот обнаружит в файле /robots.txt несколько записей с удовлетворяющим его значением agent_id, то робот волен выбирать любую из них.
Каждый поисковый робот будет определять абсолютный URL для чтения с сервера с использованием записей /robots.txt. Заглавные и строчные символы в path_root ИМЕЮТ значение.
Пример 1:
User-Agent: *
Disallow: /
User-Agent: Lycos
Disallow: /cgi-bin/ /tmp/
В примере 1 файл /robots.txt содержит две записи. Первая относится ко всем поисковым роботам и запрещает индексировать все файлы. Вторая относится к поисковому роботу Lycos и при индексировании им сервера запрещает директории /cgi-bin/ и /tmp/, а остальные - разрешает. Таким образом сервер будет проиндексирован только системой Lycos.
Определение порядка перемещения по Сети
Определение того, как перемещаться по Сети является относительной проблемой. Учитывая, что большинство серверов организовано иерархически, при первом перемещении вширь по ссылкам от вершины на ограниченной глубине вложенности ссылок, более вероятно быстрее найти набор документов с более высоким уровнем релевантности и услуг, чем при перемещении в глубину вложенности ссылок, и поэтому этот метод намного предпочтительнее для исследования ресурсов. Также при перемещении по ссылкам первого уровня вложенности более вероятно найти домашние страницы пользователей с ссылками к другим, потенциально новым, серверам, и поэтому при этом существует большая вероятность найти новые сайты.
Проиндексировать произвольный документ, находящийся в Сети, очень сложно. Первые роботы просто сохраняли название документа и якоря (anchor) в самом тексте, но новейшие роботы уже используют более продвинутые механизмы и вообще рассматривают полное содержание документа.
Эти методы являются хорошими общими мерами и могут автоматически применяться для всех страниц, но, к сожалению, не могут быть столь же эффективны, как индексация страницы самим ее автором. Язык HTML обеспечивает автора документа средством для того, чтобы присоединить к нему общую информацию. Это средство заключается в определении элемента <META>, например " <meta title = "keywords" value = " Обслуживание автомобиля Форда ". Однако, здесь не определяется никакая семантика для специфических значений атрибутов данного HTML-тэга, что серьезно ограничивает его применение, а поэтому и его полноценность. Это ведет к низкой "точности" относительно общего количества запрошенных документов, которые являются релевантными для конкретного запроса. Включение особенностей типа применения булевских операторов, нахождение весов слов, как это делается в WAIS или обратной связи для релевантности, могут улучшить точность документов, но учитывая, что информация, находящаяся в данный момент в Интернет, чрезвычайно разнообразна, эта проблема продолжает быть серьезной и наиболее эффективные пути ее решения пока не найдены.
Типы информационно-поисковых языков
Главная задача информационно-поисковой системы - поиск информации, релевантной информационным потребностям пользователя. Под релевантностью понимают соответствие между желаемой и получаемой информацией.
Релевантность можно представить также, как меру близости между реально полученными документами и тем, что следовало бы получить из системы. Возникают две взаимосвязанные задачи: представление информации в системе и формулирование информационных потребностей пользователя. Руководства по ИПС обычно утверждают, что в системе реализуется запрос типа "найди похожее". Но что означает эта фраза в действительности? Как вычислить эту похожесть?
Наиболее распространенными моделями представления документов в информационно-поисковой системе являются различные вариации на тему векторной модели, в которой документ выдается в виде набора терминов, то есть имеется не весь текст документа, а только небольшой набор терминов, отражающий его содержание. Отталкиваясь от такого представления о документе, рассмотрим различные информационно-поисковые языки и определим степень развития информационно-поисковых средств, используемых в Internet.
Традиционные ИПЯ и их модификации
Наиболее распространенным является язык, позволяющий составить логические выражения из набора терминов. При этом используются булевые операторы AND, OR, NOT. Тогда запрос может выглядеть следующим образом:
((информационная and система) or ИПС) not СУБД
Эта фраза означает: <Найди все документы, которые содержат одновременно слова "информационная" и "система", либо слово "ИПС", но не содержат слова "СУБД">. Фактически, здесь имеется два запроса: "информационная and система not СУБД" и "ИПС not СУБД", каждый из которых подразумевает как бы два действия: сначала найти все документы, содержащие необходимые пользователю термины, а потом отсеять все из них, которые содержат термин "СУБД". Такая схема достаточно проста и поэтому наиболее широко применяется в современных ИПС, однако еще 20 лет назад уже были хорошо известны ее недостатки.
Булев поиск плохо масштабирует выдачу. Оператор AND может очень сильно сократить число документов, выдаваемых на запрос. При этом все будет зависеть от того, насколько типичными для базы данных являются поисковые термины. Оператор OR, напротив, может привести к неоправданно широкому запросу, в котором полезная информация затеряется за информационным шумом. Для успешного применения этого ИПЯ следует хорошо знать лексику системы и ее тематическую направленность. Как правило, для системы с таким поисковым языком создаются специальные документально - лексические базы данных со сложными словарями или тезаурусами, содержащими информацию о связи терминов словаря друг с другом.
Модификацией булева поиска является взвешенный поиск. Идея достаточно проста. Считается, что термин описывает содержание документа с какой-то точностью, и эту точность выражают в виде веса термина. Причем взвешивать можно как термины документа, так и термины запроса. Запрос может формулироваться на ИПЯ, использующем булевы конструкции, но выдача документов при этом будет ранжироваться в зависимости от степени близости запроса и документа. Измерение близости строится таким образом, чтобы обычный булевый поиск был бы частным случаем взвешенного булевого поиска.
Языки типа "Like this"
При внимательном рассмотрении взвешенного поиска закрадывается естественное желание вообще обойтись без логических коннекторов и измерять близость документа и запроса какими-либо другими критериями. Наиболее простой моделью этого типа является линейная модель индексирования и поиска, при которой близость документа и запроса рассматривается как угол между ними. В этом случае высчитывается синус угла, получаемого как скалярное произведение двух векторов. В соответствии со значением меры близости происходит ранжирование документов при выдаче на них ссылок. Вообще скалярное произведение не очень хорошо подходит для ИПС Internet, так как длина запроса обычно невелика. Это только в традиционных системах существовали специальные службы, отлаживающие длинные запросы, а в Internet такие службы пока еще только нарождаются. Поэтому реально применяются другие меры близости, но принцип остается тот же: сначала вычисляется мера, а потом происходит ранжирование.
Поиск в нечетких множествах
При данном типе поиска весь массив документов описывается как набор нечетких множеств терминов. Каждый термин определяет некую монотонную функцию принадлежности к документам данного массива. Когда запрашивается AND, то это понимается как минимум из двух функций, соответствующих терминам запросов: OR - как максимум, NOT - как 1-<значение функции>. В соответствии с полученными значениями результат поиска также ранжируется, как и в случае с поиском по мерам близости. Этот метод поиска используется только в исследовательских системах, его распространение крайне ограничено.
Пороговые модели
Как уже было сказано, на конечном этапе поиска выборка найденных документов ранжируется, однако совершенно очевидно, что меры близости или поиск в нечетких множествах приводит к ранжированию всего массива документов в базе данных. Современные ИПС Internet имеют базы данных, состоящие только из индексов и занимающие терабайты. Ранжировать такие массивы целиком - безумная затея. Поэтому применяются пороговые модели, задающие пороговые значения для документов, выдаваемых пользователю.
Кластерная и вероятностная модели
В кластерной модели может использоваться два подхода. Первый заключается в том, что массив заранее разбивается на подмножества документов и при поиске вычисляется близость к некоторому подмножеству. В другом подходе кластер "накручивается" вокруг запроса и ближайших к нему терминов. Наиболее часто эта модель применяется в системах, уточняющих запрос по релевантности найденных документов.
При вероятностной модели вычисляется вероятность принадлежности документа классу релевантных запросу документов. При этом используется вероятность принадлежности терминов запроса каждому из документов базы данных.
Коррекция запроса по релевантности
Многие ИПС применяют механизм коррекции запроса по релевантности, означающий, что процедура поиска носит интерактивный и итеративный характер. После проведения первичного поиска пользователь отмечает релевантные запросу документы из всего списка найденных. На следующей итерации система расширяет или уточняет запрос пользователя терминами из отмеченных документов и снова выполняет поиск. Так продолжается до тех пор, пока пользователь не сочтет, что лучшего результата, чем есть, добиться уже не удастся. Коррекция запроса по релевантности - это довольно широко применяемый способ уточнения запросов. В некоторых системах, например в OpenText, пользователь может и не знать об этой процедуре. В этом случае несколько итераций выполняется автоматически.
Задание для выполнения работы
Задание 1. Для того чтобы пользователь одного компьютера смог использовать ресурсы другого компьютера, входящею в сеть, необходимо организовать доступ к логическим устройствам.
Для этого на компьютере, к логическим устройствам которого обеспечивается доступ, необходимо выполнить следующие операции:
1. Открыть окно Мой компьютер.
2. В этом окне переместить указатель на значок диска (например, D:), к которому требуется открыть доступ по сети, и щелкнуть правой кнопкой мыши.
3. В контекстном меню выбрать пункт Доступ.
4. В появившемся окне необходимо выбрать переключатель Общий ресурс.
5. Указать сетевое имя этого диска.
6. Определить один из трех типов доступа посредством переключателей Только чтение, Полный, Определяется по паролю.
7. Нажать кнопку ОК.
Указанные операции повторяются для всех логических дисков, включая и CD-ROM.
Использование общих ресурсов осуществляется через папку Сетевое окружение. Выбрав имя компьютера, можно просмотреть и использовать общие ресурсы. Для того чтобы пользователь одною компьютера смог использовать ресурсы другого компьютера, входящею в сеть, необходимо организовать доступ к сетевым дискам. После их подключения работа с ними осуществляется как с обычными дисками на индивидуальном компьютере.
Задание 2. Диагностика IP-протокола.
Нажмите кнопку Пуск, выберите строку меню Выполнить, наберите символы cmd и нажмите клавишу Enter на клавиатуре.
В открывшемся окне наберите ipconfig /all. При нормальной работе компьютера на экран должен вывестись примерно такой листинг:
Настройка протокола IP для Windows
Имя компьютера…………………..: c7a106-Main
Основной DNS-суффикс………….:
Тип узла…………………………….: гибридный
IP-маршрутизация включена………: нет
WINS-прокси включен……………..: нет
Порядок просмотра суффиксов……: compclass.loc
Подключение по локальной сети – Ethernet адаптер:
DNS-суффикс этого подключения…: compclass.loc
Описание……………………………..: Realtek RTL8168C(P)/8111C(P) PCI-E Gigabit Ethernet NIC
Физический адрес……………………:00-1F-D0-16-19-87
Dhcp включен………………………...: да
Автонастройка включена……………: да
IP-адрес………………………………..: 192.168.52.24
Маска подсети………………………...: 255.255.255.0
Основной шлюз……………………….: 192.168.52.254
DHCP-сервер…………………………..: 192.168.52.152
DNS-серверы…………………………...: 192.168.52.152
Основной WINS-сервер………………..: 192.168.52.152
Аренда получена………………………..: 5 мая 2009 г. 13:48:26
Аренда истекает…………………………: 6 мая 2009 г. 13:48:26
Отключите сетевое подключение, повторите команду. При отсутствующем соединении на экран выводится примерно такой листинг:
Windows IP Configuration
Host Name . . . . . . . . . . . . : vest
Primary Dns Suffix . . . . . . . : vrn.ru
Node Type . . . . . . . . . . . . : Hybrid
IP Routing Enabled. . . . . . . . : No
WINS Proxy Enabled. . . . . . . . : No
DNS Suffix Search List. . . . . . : vrn.ru
vrn.ru
Ethernet adapter Local Area Connection:
Media State . . . . . . . . . . . : Media disconnected
Description . . . . . . . . . . . : Intel(R) PRO/100 S Desktop Adapter
Physical Address. . . . . . . . . : 00-02-B3-8D-44-53
Обратите внимание, что программа вывела на экран только данные о "физических" параметрах сетевой карты и указала, что отсутствует подключение сетевого кабеля (Media disconnected).
Команда Ping
Команда используется для проверки протокола TCP/IP и достижимости удаленного компьютера. Она выводит на экран время, за которое пакеты данных достигают заданного в ее параметрах компьютера.
1. Проверка правильности установки протокола TCP/IP. Откройте командную строку и выполните команду:
ping 192.168.52.24
Адрес 192.168.52.24 – это личный адрес любого компьютера. Таким образом, эта команда проверяет прохождение сигнала "на самого себя". Она может быть выполнена без наличия какого-либо сетевого подключения. Вы должны увидеть приблизительно следующие строки:
Обмен пакетами 192.168.52.24 по 32 байт:
Ответ от 192.168.52.24 число байт=32 время<1мс TTL=128
Ответ от 192.168.52.24 число байт=32 время<1мс TTL=128
Ответ от 192.168.52.24 число байт=32 время<1мс TTL=128
Ответ от 192.168.52.24 число байт=32 время<1мс TTL=128
Статистика Ping для 192.168.52.24:
Пакетов: отправлено = 4, получено = 4, потеряно = 0 (0% потерь),
Приблизительное время приема-передачи в мс:
Минимальное = 0 мсек, Максимальное= 0 мсек, Среднее = 0 мсек
По умолчанию команда посылает пакет 32 байта. Размер пакета может быть увеличен до 65 кбайт. Так можно обнаружить ошибки при пересылке пакетов больших размеров. За размером тестового пакета отображается время отклика удаленной системы (в нашем случае — меньше 1 миллисекунды). Потом показывается еще один параметр протокола — значение TTL. TTL — "время жизни" пакета. На практике это число маршрутизаторов, через которые может пройти пакет, каждый маршрутизатор уменьшает значение TTL на единицу. При достижении нулевого значения пакет уничтожается. Такой механизм введен для исключения случаев зацикливания пакетов.
Если будет показано сообщение о недостижимости адресата, то это означает ошибку установки протокола IP. В этом случае целесообразно удалить протокол из системы, перезагрузить компьютер и вновь установить поддержку протокола TCP/IP.
2. Проверка видимости локального компьютера и ближайшего компьютера сети. Выполните команду
ping 192.168.52.88
На экран должны быть выведены примерно такие строки:
Обмен пакетами с 192.168.52.88 по 32 байт:
Ответ от 192.168.52.88: число байт =32 время<=1 мс TTL=128
Ответ от 192.168.52.88: число байт =32 время<=1 мс TTL=128
Ответ от 192.168.52.88: число байт =32 время<=1 мс TTL=128
Ответ от 192.168.52.88: число байт =32 время<=1 мс TTL=128
Статистика Ping для 192.168.52.88:
Пакетов: отправлено = 4, получено = 4, потеряно = 0 (0% потерь),
Приблизительное время приема-передачи в мс:
Минимум=0 мсек, Максимальное = 0 мсек, Среднее = 0 мсек
Наличие отклика свидетельствует о том, что канал связи установлен и работает.
3. Проверка работоспособности сервера имен Internet. Выполните команду
ping 192.168.3.2
Если система сможет различить IP-адрес этого хоста, то система распознавания имен работоспособна. На экран должен быть выведен примерно такой листинг:
Обмен пакетами с 192.168.3.2 по 32 байт:
Ответ от 192.168.3.2: число байт =32 время<1 мс TTL=63
Ответ от 192.168.3.2: число байт =32 время<1 мс TTL=63
Ответ от 192.168.3.2: число байт =32 время<1 мс TTL=63
Ответ от 192.168.3.2: число байт =32 время<1 мс TTL=63
Статистика Ping для 192.168.3.2:
Пакетов: отправлено = 4, получено= 4, потеряно = 0 (0% потерь),
Приблизительное время приема-передачи в мс:
Минимальное = 0 мсек, Максимально = 0 мсек, Среднее= 0 мсек 6ms
Если не будет ответа на ввод команды с именем существующего хоста, то это может свидетельствовать либо об ошибке в задании DNS-серверов, либо об их неработоспособности.
Команда Tracert
При работе в Сети одни информационные серверы откликаются быстрее, другие медленнее, бывают случаи недостижимости желаемого хоста. Для выяснения причин подобных ситуаций можно использовать специальные утилиты.
Например, команда tracert, которая обычно используется для показа пути прохождения сигнала до желаемого хоста. Зачастую это позволяет выяснить причины плохой работоспособности канала. Точка, после которой время отклика резко увеличено, свидетельствует о наличии в этом месте "узкого горлышка", не справляющегося с нагрузкой.
4. В командной строке введите команду:
tracert 192.168.3.2
Вы должны увидеть примерно такой листинг:
Трассировка маршрута к 192.168.3.2 с максимальным числом прыжков 30
1 1 ms 2 ms 1 ms 192.168.52.254
2 <1 мс <1 мс <1 мс _
Trace complete.
Команда Nslookup используется для получения информации от DNS-сервера. По умолчанию (после запуска без указания параметров) осуществляется подключение к указанному в настройках протокола серверу DNS. Набирая необходимые имена в качестве запроса, вы можете получить информацию о данных DNS по этому имени, найти почтовый сервер, обслуживающий домен, уточнить данные регистрации и т.п.
Выполните команду nslookup.
Наберите server compclass.loc и нажмите Enter – этой командой мы указываем, какой DNS-сервер мы хотим использовать для получения интересующих нас данных.
Наберите set type=all и нажмите Enter — этой командой мы указали, что нас будут интересовать все данные касательно задаваемого нами домена.
Наберите compclass.loc и нажмите Enter — этой командой мы запрашиваем данные по домену compclass.loc
На экране вы должны получить примерно такой листинг:
> nslookup
Server: srvk7class.compclass.loc
Address: 192.168.52.152
Delauf Server: compclass.loc
Address: 192.168.52.152
> set type=all
> compclass.loc
Server: compclass.loc
Address: 192.168.52.152
compclass.loc internet address = 192.168.52.152
compclass.loc nameserver = srvk7classrez.compclass.loc
compclass.loc nameserver = bgserver2009.compclass.loc
compclass.loc nameserver =srvk7class.loc
compclass.loc
primary name server = srvk7class.compclass.loc
responsible mail addr = hostmaster
serial = 720
refresh = 900 (15 mins)
retry = 600 (10 mins)
expite = 86400 (1 day)
bgserver2009.compclass.loc internet address = 192.168.52.152
srvk7class.compclass.loc internet address = 192.168.52.152