

Data-Structures-And-Algorithms-Alfred-V-Aho
.pdfData Structures and Algorithms: CHAPTER 12: Memory Management
celltype );
{ If current cell was marked, do nothing. Otherwise, mark it and call dfs on any cells pointed to by the current cell }
|
begin |
(2) |
with currentcell− do |
(3) |
if mark = false then begin |
(4) |
mark := true; |
(5) |
if (pattern = PP ) or (pattern = PA ) then |
(6) |
if left <> nil then |
(7) |
dfs (left); |
(8) |
if (pattern = PP ) or (pattern = AP ) then |
(9) |
if right <> nil then |
(10) |
dfs (right) |
|
end |
|
end; { dfs } |
(11) |
procedure collect; |
|
var |
|
i: integer; |
|
begin |
(12) |
for i := 1 to memorysize do { "unmark" |
all cells } |
|
(13) |
memory[i].mark := false; |
(14) |
dfs(source); { mark accessible cells } |
(15) |
{ the code for the collection goes here } |
|
end; { collect } |
Fig. 12.5. Algorithm for marking accessible cells.
Collection in Place
The algorithm of Fig. 12.5 has a subtle flaw. In a computing environment where memory is limited, we may not have the space available to store the stack required for recursive calls to dfs. As discussed in Section 2.6, each time dfs calls itself, Pascal (or any other language permitting recursion) creates on "activation record" for that particular call to dfs. In general, an activation record contains space for parameters and variables local to the procedure, of which each call needs its own copy. Also necessary in each activation record is a "return address," the place to which control must go when this recursive call to the procedure terminates.
In the particular case of dfs, we only need space for the parameter and the return address (i.e., was it called by line (14) in collect or by line (7) or line (10) of another
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1212.htm (8 of 33) [1.7.2001 19:32:19]
Data Structures and Algorithms: CHAPTER 12: Memory Management
invocation of dfs). However, this space requirement is enough that, should all of memory be linked in a single chain extending from source (and therefore the number of active calls to dfs would at some time equal the length of this chain), considerably more space would be required for the stack of activation records than was allotted for memory. Should such space not be available, it would be impossible to carry out the marking.
Fortunately, there is a clever algorithm, known as the Deutsch-Schorr-Waite Algorithm, for doing the marking "in place." The reader should convince himself that the sequence of cells upon which a call to dfs has been made but not yet terminated indeed forms a path from source to the cell upon which the current call to dfs was made. Thus we can use a nonrecursive version of dfs, and instead of a stack of activation records to record the path of cells from source to the cell currently being examined, we can use the pointer fields along that path to hold the path itself. That is, each cell on the path, except the last, holds in either the left or right field, a pointer to its predecessor, the cell immediately closer to source. We shall describe the Deutsch-Schorr-Waite algorithm with an extra, one-bit field, called back. Field back is of an enumerated type (L, R), and tells whether field left or field right points to the predecessor. Later, we shall discuss how the information in back can be held in the pattern field, so no extra space in cells is required.
The new procedure for nonrecursive depth-first search, which we call nrdfs, uses a pointer current to point to the current cell, and a pointer previous to the predecessor of the current cell. The variable source points to a cell source1, which has a pointer in its right field only.† Before marking, source1 is initialized to have back = R, and its right field pointing to itself. The cell ordinarily pointed to by source1, is pointed to by current, and source1 is pointed to by previous. We halt the marking operation when current = previous, which can only occur when they both point to source1, the entire structure having been searched.
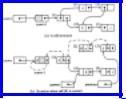
Example 12.3. Figure 12.6(a) shows a possible structure emanating from source. If we depth-first search this structure, we visit (1), (2), (3) and (4), in that order. Figure 12.6(b) shows the pointer modifications made when cell (4) is current. The value of the back field is shown, although fields mark and pattern are not. The current path is from (4) to (3) to (2) to (1) back to sourcel; it is represented by dashed pointers. For example, cell (1) has back = L, since the left field of (1), which in Fig. 12.6(a) held a pointer to (2), is being used in Fig. 12.6(b) to hold part of the path. Now the left field in (1) points backwards, rather than forwards along the path; however, we shall restore that pointer when the depth-first search finally retreats from cell (2) back to
(1). Similarly, in cell (2), back = R, and the right field of (2) points backwards along the path to (1), rather than ahead to (3), as it did in Fig. 12.6(a).
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1212.htm (9 of 33) [1.7.2001 19:32:19]
Data Structures and Algorithms: CHAPTER 12: Memory Management
Fig. 12.6. Using pointers to represent the path back to source.
There are three basic steps to performing the depth-first search. They are:
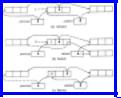
1.Advance. If we determine that the current cell has one or more nonnull pointers, advance to the first of these, that is, follow the pointer in left, or if there is none, the pointer in right. By "advance," we mean to make the cell pointed to become the current cell and the current cell become previous. To help find the way back, the pointer just followed is made to point to the old previous cell. These changes are shown in Fig. 12.7(a), on the assumption that the left pointer is followed. In that figure, the old pointers are solid lines and the new ones dashed.
2.Switch. If we determine that the cells emanating from the current cell have been searched (for example, the current cell may have only atoms, may be marked, or we may just have "retreated" to the current cell from the cell pointed to by the right field of the current cell), we consult the field back of the previous cell. If that value is L, and the right field of the previous cell holds a nonnull pointer to some cell C, we make C become the current cell, while the identity of the previous cell is not changed. However, the value of back in the previous cell is set to R, and the left pointer in that cell receives its correct value; that is, it is made to point to the old current cell. To maintain the path back to source from the previous cell, the pointer to C in field right is made to point where left used to point. Figure 12.7(b) shows these changes.
3.Retreat. If we determine, as in (2), that the cells emanating from the current cell have been searched, but field back of the previous cell is R, or it is L but field right holds an atom or null pointer, then we have now searched all cells emanating from the previous cell. We retreat, by making the previous cell be the current cell and the next cell along the path from the previous cell to source be the new previous cell. These changes are shown in Fig. 12.7(c), on the assumption that back = R in the previous cell.
One fortuitous coincidence is that each of the steps of Fig. 12.7 can be viewed as the simultaneous rotation of three pointers. For example, in Fig. 12.7(a), we simultaneously replace (previous, current, current−.left) by (current, current−.left, previous), respectively. The simultaneity must be emphasized; the location of current−.left does not change when we assign a new value to current. To perform these pointer modifications, a procedure rotate, shown in Fig. 12.8, is naturally
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1212.htm (10 of 33) [1.7.2001 19:32:19]
Data Structures and Algorithms: CHAPTER 12: Memory Management
useful. Note especially that the passing of parameters by reference assures that the locations of the pointers are established before any values change.
Now we turn to the design of the nonrecursive marking procedure nrdfs. This procedure is one of these odd processes that is most easily understood when written with labels and gotos. Particularly, there are two "states" of the procedure, "advancing," represented by label 1, and "retreating," represented by label 2. We enter the first state initially, and also whenever we have moved to a new cell, either by an advance step or a switch step. In this state, we attempt another advance step, and only retreat or switch if we are blocked. We can be blocked for two reasons: (l) The cell just reached is already marked, or (2) there are no nonnull pointers in the cell. When blocked, we change to the second, or "retreating" state.
Fig. 12.7. Three basic steps.
procedure rotate ( var p1, p2, p3: − celltype ); var
temp: − celltype; begin
temp := p1; p1 := p2; p2 := p3; p3 := temp
end; { rotate }
Fig. 12.8. Pointer modification procedure.
The second state is entered whenever we retreat, or when we cannot stay in the advancing state because we are blocked. In the retreating state we check whether we have retreated back to the dummy cell source1. As discusssed before, we shall recognize this situation because previous = current, in which case we go to state 3. Otherwise, we decide whether to retreat and stay in the retreating state or switch and enter the advancing state. The code for nrdfs is shown in Fig. 12.9. It makes use of functions blockleft, blockright, and block, which test if the left or right fields of a cell, or both, have an atom or null pointer. block also checks for a marked cell.
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1212.htm (11 of 33) [1.7.2001 19:32:19]
Data Structures and Algorithms: CHAPTER 12: Memory Management
function blockleft ( cell: celltype ): boolean; { test if left field is atom or null pointer } begin
with cell do
if (pattern = PP) or (pattern = PA)
then
if left <> nil then return (false); return (true)
end; { blockleft }
function blockright ( cell : celltype ): boolean; { test if right field is atom or null pointer } begin
with cell do
if (pattern = PP) or (pattern = AP)
then
if right <> nil then return (false);
return (true) end; { blockright }
function block ( cell: celltype ): boolean;
{ test if cell is marked or contains no nonnull pointers } begin
if (cell.mark = true) or blockleft (cell) and blockright (cell) then
return (true) else
return (false) end; { block }
procedure nrdfs; { marks cells accessible from source } var
current, previous: − celltype; begin { initialize }
current := source 1−.right; { cell pointed to by source1 }
previous := source 1; { previous points to source1 } source 1−.back := R;
source 1−.right := source 1; { source1 points to itself }
source 1−.mark := true;
state 1: { try to advance }
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1212.htm (12 of 33) [1.7.2001 19:32:19]
Data Structures and Algorithms: CHAPTER 12: Memory Management
if block (current−) then begin
{ prepare to retreat } current−.mark := true; goto state2
end
else begin { mark and advance } current−.mark := true;
if blockleft (current−) then begin { follow right pointer }
current−.back := R;
rotate(previous, current, current−.right); { implements changes of Fig. 12.7(a), but following right pointer }
goto state1 end
else begin { follow left pointer } current−.back := L;
rotate (previous, current, current−.left); { implements changes of Fig. 12.7(a) }
goto state1 end
end;
state2: { finish, retreat or switch }
if previous = current then { finish } goto state3
else if (previous−.back = L )
and
not blockright (previous−) then begin { switch }
previous−.back := R; rotate (previous−.left,
current, previous−.right);
{ implements changes of Fig. 12.7(b) } goto state1
end
else if previous−.back = R then { retreat }
rotate (previous, previous−.right, current) { implements changes of Fig. 12.7(c) }
else { previous−.back = L } rotate (previous, previous−.left,
current);
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1212.htm (13 of 33) [1.7.2001 19:32:19]

Data Structures and Algorithms: CHAPTER 12: Memory Management
{ implements changes of Fig. 12.7(c), but with left field of previous cell involved in the path }
goto state2 end;
state3: { put code to link unmarked cells on available list here } end; { nrdfs }
Fig. 12.9. Nonrecursive marking algorithm.
Deutsch-Schorr-Waite Algorithm Without an Extra Bit for the Field Back
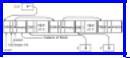
It is possible, although unlikely, that the extra bit used in cells for the field back might cause cells to require an extra byte, or even an extra word. In such a case, it is comforting to know that we do not really need the extra bit, at least not if we are programming in a language that, unlike Pascal, allows the bits of the field pattern to be used for purposes other than those for which they were declared: designators of the variant record format. The "trick" is to observe that if we are using the field back at all, because its cell is on the path back to source1, then the possible values of field pattern are restricted. For example, if back = L, then we know the pattern must be PP or PA, since evidently the field left holds a pointer. A similar observation can be made when back = R. Thus, if we have two bits available to represent both pattern and (when needed) back, we can encode the necessary information as in Fig. 12.10, for example.
The reader should observe that in the program of Fig. 12.9, we always know whether back is in use, and thus can tell which of the interpretations in Fig. 12.10 is applicable. Simply, when current points to a record, the field back in that record is not in use; when previous points to it, it is. Of course, as these pointers move, we must adjust the codes. For example, if current points to a cell with bits 10, which we interpret according to Fig. 12.10 as pattern = AP, and we decide to advance, so previous will now point to this cell, we make back=R, as only the right field holds a pointer, and the appropriate bits are 11. Note that if the pattern were AA, which has no representation in the middle column of Fig. 12.10, we could not possibly want previous to point to the cell, as there are no pointers to follow in an advancing move.
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1212.htm (14 of 33) [1.7.2001 19:32:19]
Data Structures and Algorithms: CHAPTER 12: Memory Management
Fig. 12.10. Interpreting two bits as pattern and back.
12.4 Storage Allocation for Objects with Mixed Sizes
Let us now consider the management of a heap, as typified by Fig. 12.1, where there is a collection of pointers to allocated blocks. The blocks hold data of some type. In Fig. 12.1, for example, the data are character strings. While the type of data stored in the heap need not be character strings, we assume the data contain no pointers to locations within the heap.
The problem of heap management has aspects that make it both easier and harder than the maintenance of list structures of equal-sized cells as discussed in the previous section. The principal factor making the problem easier is that marking used blocks is not a recursive process; one has only to follow the external pointers to the heap and mark the blocks pointed to. There is no need for a depth-first search of a linked structure or for anything like the Deutsch-Schorr-Waite algorithm.
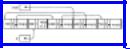
On the other hand, managing the available space list is not as simple as in Section 12.3. We might imagine that the empty regions (there are three empty regions in Fig. 12.1(a), for example) are linked together as suggested in Fig. 12.11. There we see a heap of 3000 words divided into five blocks. Two blocks of 200 and 600 words, hold the values of X and Y. The remaining three blocks are empty, and are linked in a chain emanating from avail, the header for available space.
Fig. 12.11. A heap with available space list.
In order that empty blocks may be found when they are needed to hold new data, and blocks holding useless data may be made available, we shall throughout this section make the following assumptions about blocks.
1.Each block is sufficiently large to hold
a.A count indicating the size (in bytes or words, as appropriate for the computer system) of the block,
b.A pointer (to link the block in available space), plus
c.A bit to indicate whether the block is empty or not. This bit is referred to as the full/empty or used/unused bit.
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1212.htm (15 of 33) [1.7.2001 19:32:19]
Data Structures and Algorithms: CHAPTER 12: Memory Management
2.An empty block has, from the left (low address end), a count indicating its length, a full/empty bit with a value of 0, indicating emptiness of the block, a pointer to the next available block, and empty space.
3.A block holding data has, from the left, a count, a full/empty bit with value 1 indicating the block is in use, and the data itself.†
One interesting consequence of the above assumptions is that blocks must be capable of storing data sometimes (when in use) and pointers at other times (when unused) in precisely the same place. It is thus impossible or very inconvenient to write programs that manipulate blocks of the kind we propose in Pascal or any other strongly typed language. Thus, this section must of necessity be discursive; only pseudo-Pascal programs can be written, never real Pascal programs. However, there is no problem writing programs to do the things we describe in assembly languages or in most systems programming languages such as C.
Fragmentation and Compaction of Empty
Blocks
To see one of the special problems that heap management presents, let us suppose that the variable Y of Fig. 12.11 changes, so the block representing Y must be returned to available space. We can most easily insert the new block at the beginning of the available list, as suggested by Fig. 12.12. In that figure, we see an instance of fragmentation, the tendency for large empty areas to be represented on the available space list by "fragments," that is, several small blocks making up the whole. In the case in point, the last 2300 bytes of the heap in Fig. 12.12 are empty, yet the space is divided into three blocks of 1000, 600, and 700 bytes, and these blocks are not even in consecutive order on the available list. Without some form of garbage collection, it would be impossible to satisfy a request for, say, a block of 2000 bytes.
Fig. 12.12. After returning the block of Y.
Evidently, when returning a block to available space it would be desirable to look at the blocks to the immediate left and right of the block being made available. Finding the block to the right is easy. If the block being returned begins at position p and has count c, the block to the right begins at position p+c. If we know p (for example, the pointer Y in Fig. 12.11 holds the value p for the block made available in Fig. 12.12), we have only to read the bytes starting at position p, as many as are used
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1212.htm (16 of 33) [1.7.2001 19:32:19]
Data Structures and Algorithms: CHAPTER 12: Memory Management
for holding c, to obtain the value c. From byte p+c, we skip over the count field to find the bit that tells whether or not the block is empty. If empty, the blocks beginning at p and p + c can be combined.
Example 12.4. Let us assume the heap of Fig. 12.11 begins at position 0. Then the block for Y being returned begins in byte 1700, so p=1700 and c=600. The block beginning at p+c=2300 is also empty so we could combine them into one block beginning at 1700 with a count of 1300, the sum of the counts in the two blocks.
It is, however, not so easy to fix the available list after combining blocks. We can create the combined block by simply adding the count of the second block to c. However, the second block will still be linked in the available list and must be removed. To do so requires finding the pointer to that block from its predecessor on the available list. Several strategies present themselves; none is strongly recommended over the others.
1.Run down the available list until we find a pointer with value p+c. This pointer must be in the predecessor block of the block we have combined with its neighbor. Replace the pointer found by the pointer in the block at p+c. This effectively eliminates the block beginning at position p+c from the available list. Its space is still available, of course; it is part of the block beginning at p. On the average, we shall have to scan half the available list, so the time taken is proportional to that length.
2.Use a doubly-linked available space list. Then the predecessor block can be found quickly and the block at p+c eliminated from the list. This approach takes constant time, independent of the length of the available list, but it requires extra space for another pointer in each empty block, thus increasing the minimum size for a block to that required to hold a count, a full/empty bit, and two pointers.
3.Keep the available space list sorted by position. Then we know the block at position p is the predecessor on the available list of the block at p+c, and the pointer manipulation necessary to eliminate the second block can be done in constant time. However, insertion of a new available block requires a scan of half the available list on the average, and is thus no more efficient than method (1).
Of the three methods, all but the second require time proportional to the length of the available list to return a block to available space and combine it with its right neighbor if that neighbor is empty. This time may or may not be prohibitive, depending on how long the list gets and what fraction of the total program time is spent manipulating the heap. The second method - doubly linking the available list - has only the penalty of an increased minimum size for blocks. Unfortunately, when
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1212.htm (17 of 33) [1.7.2001 19:32:19]