

Data-Structures-And-Algorithms-Alfred-V-Aho
.pdfData Structures and Algorithms: CHAPTER 11: Data Structures and Algorithms for External Storage
if current[1].key < current[2].key then winner := 1
else winner := 2;
{ write winning record }
if outswitch then write(g 1, current[winner])
else write(g 2, current[winner]); { advance winning file } getrecord(winner)
end;
{we have finished merging two runs - switch output file and repeat }
outswitch := not outswitch end
end; { merge }
Fig. 11.2. The procedure merge.
Notice that the procedure merge, of Fig. 11.2, is not required ever to have a complete run in memory; it reads and writes a record at a time. It is our desire not to store whole runs in main memory that forces us to have two input files. Otherwise, we could read two runs at a time from one file.
Example 11.1. Suppose we have the list of 23 numbers shown divided into two files in Fig. 11.3(a). We begin by merging runs of length 1 to create the two files of Fig. 11.3(b). For example, the first runs of length 1 are 28 and 31; these are merged by picking 28 and then 31. The next two runs of length one, 3 and 5, are merged to form a run of length two, and that run is placed on the second file of Fig. ll.3(b). The runs are separated in Fig. 11.3(b) by vertical lines that are not part of the file. Notice that the second file in Fig. 11.3(b) has a tail of length one, the record 22, while the first file has no tail.
We go from Fig. 11.3(b) to (c) by merging runs of length two. For example, the two runs 28, 31 and 3, 5 are merged to form 3, 5, 28, 31 in Fig. 11.3(c). By the time we get to runs of length 16 in Fig. 11.3(e), one file has one complete run and the other has only a tail, of length 7. At the last stage, where the files are ostensibly organized as runs of length 32, we in fact have one file with a tail only, of length 23, and the second file is empty. The single run of length 23 is, of course, the desired sorted order.
Speeding Up Merge Sort
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1211.htm (6 of 34) [1.7.2001 19:28:20]

Data Structures and Algorithms: CHAPTER 11: Data Structures and Algorithms for External Storage
We have, for the sake of a simple example, shown the merge sort process as starting from runs of length one. We shall save considerable time if we begin with a pass that, for some appropriate k, reads groups of k records into main memory, sorts them, say by quicksort, and writes them out as a run of length k.
For example, if we have a million records, it would take 20 passes through the data to sort starting with runs of length one. If, however, we can hold 10,000 records at once in main memory, we can, in one pass, read 100 groups of 10,000 records, sort each group, and be left with 100 runs of length 10,000 distributed evenly between two files. Seven more merging passes results in a file organized as one run of length 10,000 x 27 = 1,280,000, which is more than a million and means that the data are sorted.
Minimizing Elapsed Time
In modern time-shared computer systems, one is generally not charged for the time one's program spends waiting for blocks of a file to be read in, as must happen during the merge sort process. However, the fact is that the elapsed time of such a sorting process is greater, often substantially so, than the time spent computing with data found in the main memory. If we are sorting really large files, where the whole operation takes hours, the elapsed time becomes important, even if we do not "pay" for the time, and we should consider how the merging process might be performed in minimum elapsed time.
As was mentioned, it is typical that the time to read data from a disk or tape is greater than the time spent doing simple computations with that data,
Fig. 11.3. Merge-sorting a list.
such as merging. We should therefore expect that if there is only one channel over which data can be transferred into or out of main memory, then this channel will form a bottleneck; the data channel will be busy all the time, and the total elapsed time equals the time spent moving data into and out of main memory. That is, all the computation will be done almost as soon as the data becomes available, while additional data are being read or written.
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1211.htm (7 of 34) [1.7.2001 19:28:20]
Data Structures and Algorithms: CHAPTER 11: Data Structures and Algorithms for External Storage
Even in this simple environment, we must exercise a bit of care to make sure that we are done in the minimum amount of time. To see what can go wrong, suppose we read the two input files f1 and f2 one block at a time, alternately. The files are organized into runs of some length much larger than the size of a block, so to merge two runs we must read many blocks from each file. However, suppose it happens that all the records in the run from file f1 happen to precede all the records from file f2. Then as we read blocks alternately, all the blocks from f2 have to remain in memory. There may not be space to hold all these blocks in main memory, and even if there is, we must, after reading all the blocks of the run, wait while we copy and write the whole run from f2.
To avoid these problems, we consider the keys of the last records in the last blocks read from f1 and f2, say keys k1 and k2, respectively. If either run is exhausted, we naturally read next from the other file. However, if a run is not exhausted, we next read a block from f1 if k1<k2, and we read from f2 otherwise. That is, we determine which of the two runs will first have all its records currently in main memory selected, and we replenish the supply of records for that run first. If selection of records proceeds faster than reading, we know that when we have read the last block of the two runs, there cannot be more than two "blockfuls" of records left to merge; perhaps the records will be distributed over three blocks, but never more.
Multiway Merge
If reading and writing between main and secondary memory is the bottleneck, perhaps we could save time if we had more than one data channel. Suppose, for example, that we have 2m disk units, each with its own channel. We could place m files, f1, f2, . . .,fm on m of the disk units, say organized as runs of length k. We can read m runs, one from each file, and merge them into one run of length mk. This run is placed on one of m output files g1, g2, . . . ,gm, each getting a run in turn.
The merging process in main memory can be carried out in O(logm) steps per record if we organize the m candidate records, that is, the currently smallest unselected records from each file, into a partially ordered tree or other data structure that supports the priority queue operations INSERT and DELETEMIN in logarithmic time. To select from the priority queue the record with the smallest key, we perform DELETEMIN, and then INSERT into the priority queue the next record from the file of the winner, as a replacement for the selected record.
If we have n records, and the length of runs is multiplied by m with each pass,
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1211.htm (8 of 34) [1.7.2001 19:28:20]
Data Structures and Algorithms: CHAPTER 11: Data Structures and Algorithms for External Storage
then after i passes runs will be of length mi. If mi ³ n, that is, after i = logmn passes, the entire list will be sorted. As logmn = log2n/log2m, we save by a factor of log2m in the number of times we read each record. Moreover, if m is the number of disk units used for input files, and m are used for output, we can process data m times as fast as if we had only one disk unit for input and one for output, or 2m times as fast as if both input and output files were stored on one disk unit. Unfortunately, increasing m indefinitely does not speed processing by a factor of logm. The reason is that for large enough m, the time to do the merging in main memory, which is actually increasing as logm, will exceed the time to read or write the data. At that point, further increases in m actually increase the elapsed time, as computation in main memory becomes the bottleneck.
Polyphase Sorting
We can perform an m-way merge sort with only m + 1 files, as an alternative to the 2m-file strategy described above. A sequence of passes is made, merging runs from m of the files into longer runs on the remaining file. The insights needed are the following:
1.In one pass, when runs from each of m files are merged into runs of the m + 1st file, we need not use all the runs on each of the m input files. Rather, each file, when it becomes the output file, is filled with runs of a certain length. It uses some of these runs to help fill each of the other m files when it is their turn to be the output file.
2.Each pass produces files of a different length. Since each of the files loaded with runs on the previous m passes contributes to the runs of the current pass, the length on one pass is the sum of the lengths of the runs produced on the previous m passes. (If fewer than m passes have taken place, regard passes prior to the first as having produced runs of length 1.)
Such a merge-sorting process is called a polyphase sort. The exact calculation of the numbers of passes needed, as a function of m and n (the number of records), and calculation of the initial distribution of the runs into m files are left as exercises.
However, we shall give one example here to suggest the general case.
Example 11.2. If m = 2, we start with two files f1 and f2, organized into runs of length 1. Records from f1 and f2 are merged to make runs of length 2 on the third file, f3. Just enough runs are merged to empty f1. We then merge the remaining runs of length 1 from f2 with an equal number of runs of length 2 from f3. These yield runs of length 3, and are placed on f1. Then we merge runs of length 2 on f3 with runs of
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1211.htm (9 of 34) [1.7.2001 19:28:20]
Data Structures and Algorithms: CHAPTER 11: Data Structures and Algorithms for External Storage
length 3 on f1. These runs, of length 5, are placed on f2, which was emptied at the previous pass.
The run length sequence: 1, 1, 2, 3, 5, 8, 13, 21, . . . . . is the Fibonacci sequence. This sequence is generated by the recurrence relation F0 = F1 = 1, and Fi = Fi-1 + Fi-
2, for i ³ 2. Note that the ratio of consecutive Fibonacci numbers Fi+1/Fi approaches the "golden ratio" (Ö`5+1)/2 = 1.618 . . . as i gets large.
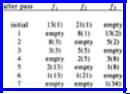
It turns out that in order to keep this process going, until the list is sorted, the initial numbers of records on f1 and f2 must be two consecutive Fibonacci numbers. For example, Fig. 11.4 shows what happens when we start with n = 34 records (34 is the Fibonacci number F8) distributed 13 on f1 and 21 on f2. (13 and 21 are F6 and F7, so the ratio F7/F6 is very close to 1.618. It is 1.615, in fact). The status of a file is represented in Fig. 11.4 as a(b), meaning it has a runs of length b.
Fig. 11.4. Example of polyphase sorting.
When Input/Output Speed is not a
Bottleneck
When reading files is the bottleneck, the next block read must be carefully chosen. As we have mentioned, the situation to avoid is one where we have to store many blocks of one run because that run happened to have records with high keys, which get selected after most or all of the records of the other run. The trick to avoiding this problem is to determine quickly which run will first exhaust those of its records currently in main memory, by comparing the last such records in each file.
When the time taken to read data into main memory is comparable to, or less than, the time taken to process the data, it becomes even more critical that we select the input file from which to read a block carefully, since there is no hope of building a reserve of records in main memory in case the merge process suddenly starts taking more records from one run than the other. The "trick" mentioned above helps us in a variety of situations, as we shall see.
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1211.htm (10 of 34) [1.7.2001 19:28:20]
Data Structures and Algorithms: CHAPTER 11: Data Structures and Algorithms for External Storage
We consider the case where merging, rather than reading or writing, is a bottleneck for two reasons.
1.As we have seen, if we have many disk or tape units available, we may speed input/output sufficiently that the time to do the merge exceeds input time or output time.
2.Higher speed channels may yet become commercially available.
We therefore shall consider a simple model of the problem that might be encountered when merging becomes the bottleneck in a merge sort performed on data stored in secondary memory. Specifically, we assume that
a.We are merging runs that are much larger than blocks.
b.There are two input files and two output files. The input files are stored on one disk (or other device connected to main memory by a single channel) and the output files are on another similar unit with one channel.
c.The times to
i.read a block
ii.write a block, and
iii.select enough of the lowest-keyed records from among those of two runs presently in main memory to fill a block,
are all the same.
Under these assumptions, we can consider a class of merging strategies where several input buffers (space to hold a block) are allocated in main memory. At all times some of these buffers will hold the unselected records from the two input runs, and one of them will be in the process of being read into from one of the input files. Two other buffers will hold output, that is, the selected records in their properly merged order. At all times, one of these buffers is in the process of being written into one of the output files and the other is being filled from records selected from the input buffers.
A stage consists of doing the following (possibly at the same time):
1.reading an input block into an input buffer,
2.filling one of the output buffers with selected records, that is, records with the smallest keys among those currently held in the input buffer, and
3.writing the other output buffer into one of the two output files being formed.
By our assumptions, (1), (2), and (3) all take the same time. For maximum efficiency, we must do them in parallel. We can do so, unless (2), the selection of records with the smallest keys, includes some of the records currently being read in.†
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1211.htm (11 of 34) [1.7.2001 19:28:20]
Data Structures and Algorithms: CHAPTER 11: Data Structures and Algorithms for External Storage
We must thus devise a strategy for selecting buffers to be read so that at the beginning of each stage the b unselected records with smallest keys are already in input buffers, where b is the number of records that fills a block or buffer.
The conditions under which merging can be done in parallel with reading are simple. Let k1 and k2 be the highest keys among unselected records in main memory from the first and second runs, respectively. Then there must be in main memory at least b unselected records whose keys do not exceed min(k1, k2). We shall first show how to do the merge with six buffers, three used for each file, then show that four buffers suffice if we share them between the two files.
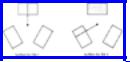
A Six-Input Buffer Scheme
Our first scheme is represented by the picture in Fig. 11.5. The two output buffers are not shown. There are three buffers for each file; each buffer has capacity b records. The shaded area represents available records, and keys are in increasing order clockwise around the circles. At all times, the total number of unselected records is 4b (unless fewer than that number of records remain from the runs being merged). Initially, we read the first two blocks from each run into buffers.† As there are always 4b records available, and at most 3b can be from one file, we know there are b records at least from each file. If k1 and k2 are the largest available keys from the two runs, there must be b records with keys equal to or less than k1 and b with keys equal to or less than k2. Thus, there are b records with keys equal to or less than min(k1, k2).
Fig. 11.5. A six-input buffer merge.
The question of which file to read from next is trivial. Usually, since two buffers will be partially full, as in Fig. 11.5, there will be only one empty buffer, and this must be filled. If it happens, as in the beginning, that each run has two completely filled and one empty buffer, pick either empty buffer to fill. Note that our proof that we could not exhaust a run [b records with keys equal to or less than min(k1, k2) exist] depended only on the fact that 4b records were present.
As an aside, the arrows in Fig. 11.5 represent pointers to the first (lowest-keyed) available records from the two runs. In Pascal, we could represent such a pointer by
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1211.htm (12 of 34) [1.7.2001 19:28:20]
Data Structures and Algorithms: CHAPTER 11: Data Structures and Algorithms for External Storage
two integers. The first, in the range 1..3, represents the buffer pointed to, and the second, in the range 1..b, represents the record within the buffer. Alternatively, we could let the buffers be the first, middle, and last thirds of one array and use one integer in the range 1..3b. In other languages, where pointers can point to elements of arrays, a pointer of type − recordtype would be preferred.
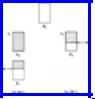
A Four-Buffer Scheme
Figure 11.6 suggests a four-buffer scheme. At the beginning of each stage, 2b records are available. Two of the input buffers are assigned to one of the files; B1 and
B2 in Fig. 11.6 are assigned to file one. One of these buffers will be partially full (empty in the extreme case) and the other full. A third buffer is assigned to the other file, as B3 is assigned to file two in Fig. 11.6. It is partially full (completely full in the extreme case). The fourth buffer is uncommitted, and will be filled from one of the files during the stage.
Fig. 11.6. A four-input buffer merge.
We shall maintain, of course, the property that allows us to merge in parallel with reading; at least b of the records in Fig. 11.6 must have keys equal to or less than min(k1, k2), where k1 and k2 are the keys of the last available records from the two files, as indicated in Fig. 11.6. We call a configuration that obeys the property safe. Initially, we read one block from each run (this is the extreme case, where B1 is empty and B3 is full in Fig. 11.6), so that the initial configuration is safe. We must, on the assumption that Fig. 11.6 is safe, show that the configuration will be safe after the next stage is complete.
If k1<k2, we choose to fill B4 with the next block from file one, and otherwise, we fill it from file two. Suppose first that k1<k2. Since B1 and B3 in Fig. 11.6 have together exactly b records, we must, during the next stage, exhaust B1, else we would exhaust B3 and contradict the safety of Fig. 11.6. Thus after a stage the configuration looks like Fig. 11.7(a).
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1211.htm (13 of 34) [1.7.2001 19:28:20]

Data Structures and Algorithms: CHAPTER 11: Data Structures and Algorithms for External Storage
Fig. 11.7. Configuration after one stage.
To see that Fig. 11.7(a) is safe, consider two cases. First, if k3, the last key in the newly-read block B4, is less than k2, then as B4 is full, there are surely b records equal to or less than min(k3, k2), and the configuration is safe. If k2£k3, then since k1<k2 was assumed (else we would have filled B4 from file two), the b records in B2 and B3 have keys equal to or less than min(k2, k3)=k2.
Now let us consider the case where k1³k2 in Fig. 11.6. Then we choose to read the next block from file two. Figure 11.7(b) shows the resulting situation. As in the case k1<k2, we can argue that B1 must exhaust, which is why we show file one as having only buffer B2 in Fig. 11.7(b). The proof that Fig. 11.7(b) is safe is just like the proof for Fig. 11.7(a).
Note that, as in the six buffer scheme, we do not read a file past the end of a run. However, if there is no need to read in a block from one of the present runs, we can read a block from the next run on that file. In this way we have the opportunity to read one block from each of the next runs, and we are ready to begin merging runs as soon as we have selected the last records of the previous run.
11.3 Storing Information in Files
In this section we consider data structures and algorithms for storing and retrieving information in externally stored files. We shall view a file as a sequence of records, where each record consists of the same sequence of fields. Fields can be either fixed length, having a predetermined number of bytes, or variable length, having an arbitrary size. Files with fixed length records are commonly used in database management systems to store highly structured data. Files with variable length records are typically used to store textual information; they are not available in Pascal. In this section we shall assume fixed-length fields; the fixed-length techniques can be modified simply to work for variable-length records.
The operations on files we shall consider are the following.
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1211.htm (14 of 34) [1.7.2001 19:28:20]
Data Structures and Algorithms: CHAPTER 11: Data Structures and Algorithms for External Storage
1.INSERT a particular record into a particular file.
2.DELETE from a particular file all records having a designated value in each of a designated set of fields.
3.MODIFY all records in a particular file by setting to designated values certain fields in those records that have a designated value in each of another set of fields.
4.RETRIEVE all records having designated values in each of a designated set of fields.
Example 11.3. For example, suppose we have a file whose records consist of three fields: name, address, and phone. We might ask to retrieve all records with phone = "555-1234", to insert the record ("Fred Jones", "12 Apple St.", "555-1234"), or to delete all records with name = "Fred Jones" and address = "12 Apple St." As another example, we might wish to modify all records with name = "Fred Jones" by setting the phone field to "5551234".
To a great extent we can view operations on files as if the files were sets of records and the operations were those discussed in Chapters 4 and 5. There are two important differences, however. First, when we talk of files on external storage devices, we must use the cost measure discussed in Section l l.l when evaluating strategies for organizing the files. That is, we assume that files are stored in some number of physical blocks, and the cost of an operation is the number of blocks that we must read into main memory or write from main memory onto external storage.
The second difference is that records, being concrete data types of most programming languages, can be expected to have pointers to them, while the abstract elements of a set would not normally have "pointers" to them. In particular, database systems frequently make use of pointers to records when organizing data. The consequence of such pointers is that records frequently must be regarded as pinned; they cannot be moved around in storage because of the possibility that a pointer from some unknown place would fail to point to the record after it was moved.
A simple way to represent pointers to records is the following. Each block has a physical address, which is the location on the external storage device of the beginning of the block. It is the job of the file system to keep track of physical addresses. One way to represent record addresses is to use the physical address of the block holding the record together with an offset, giving the number of bytes in the block preceding the beginning of the record. These physical address--offset pairs can then be stored in fields of type "pointer to record."
A Simple Organization
http://www.ourstillwaters.org/stillwaters/csteaching/DataStructuresAndAlgorithms/mf1211.htm (15 of 34) [1.7.2001 19:28:20]