


17
3.Информационные ресурсы дисциплины
3.1.Библиографический список
Основной:
1.Кремер, Н. Ш. Эконометрика / Н. Ш. Кремер, Б. А. Путко. – М.: ЮНИТИ-
ДАНА, 2002, 2005. – 311 с.
Дополнительный:
2.Доугерти, К. Введение в эконометрику: учебник: пер. с англ. / К. Доугерти. – М.: ИНФРА – М, 2004. – 418 с.
3.Эконометрика / под ред. И. И. Елисеевой. – М.: Финансы и статистика, 2005. – 576 с.
4.Практикум по эконометрике / под ред. И. И. Елисеевой. – М.: Финансы и статистика, 2005. – 192 с.
3.2.Опорный конспект*
Введение
Эконометрика – это наука, которая устанавливает и исследует количественные закономерности и взаимозависимости в экономике на основе анализа реальных статистических данных.
Эконометрика базируется на математической статистике и экономической теории. Экономическая теория выявила и исследовала большое число устоявшихся связей между различными показателями. Эти закономерности сформулированы качественно. Например, экономическая теория утверждает, что спрос на товар с ростом его цены убывает, но при этом не отвечает на вопрос, как быстро. Эконометрика с помощью математико-статистических методов в каждом конкретном случае придает количественное выражение общим закономерностям.
Задачей эконометрики является построение эконометрических моделей и оценивание их параметров, проверка гипотез о свойствах экономических показателей и формах их связи.
* Нумерация разделов, параграфов, формул, таблиц и рисунков в опорном конспекте является автономной.
18
Раздел 1. Парная линейная регрессия
Вразделе рассматриваются три темы:
1.Классическая линейная модель парной регрессии.
2.Оценка качества модели парной регрессии.
3.Прогноз по модели парной регрессии.
По каждой теме излагается основной теоретический материал и приводятся иллюстрирующие его примеры.
После проработки теоретического материала раздела студентам очнозаочной и заочной форм обучения надо выполнить задания контрольной работы в соответствии со своим вариантом. Студенты очной формы обучения во время первой практической работы выполняют задания, приведенные в контрольной работе.
После изучения данного раздела необходимо ответить на вопросы теста № 1. Более подробная информация по данной теме содержится в учебнике [1].
1.1.Классическая линейная модель парной регрессии
Изучаемые вопросы:
взаимосвязи экономических переменных;
педпосылки модели;
оценка параметров парной регрессии методом наименьших квадратов;
статистические свойства МНК-оценок.
При работе с теоретическим материалом следует разобрать примеры решения задач и ответить на контрольные вопросы, приведенные в конце темы.
Взаимосвязи экономических переменных
Одной из основных задач в экономических исследованиях является анализ взаимосвязей экономических показателей. Обычно согласно некоторой экономической гипотезе выделяют зависимые и независимые переменные. Зависимую переменную называют также результативным признаком,
19
объясняемой или эндогенной переменной, независимую переменную – факторной, объясняющей или экзогенной переменной.
Зависимость между переменными может быть строгой (функциональной) либо статистической. Связь между показателями называется функциональной, если каждому значению x соответствует определенное значение y , т. е. y =ϕ(x), где ϕ – обычная числовая функция.
В экономике функциональная зависимость между переменными проявляется редко. Обычно на связь переменных накладывается воздействие случайных факторов и каждому конкретному значению объясняющей переменной соответствует не одно, а множество значений зависимой переменной, точнее, некоторое вероятностное распределение зависимой переменной.
Если при изменении значений x изменяется закон распределения случайной величины y , то зависимость переменной y от переменной x
называется статистической. Для изучения статистической зависимости необходимо располагать большими совокупностями наблюдений переменной y для каждого значения переменной x . Обычно исследуют, как изменяется среднее значение y при изменении значений x . Зависимость, при которой
изменение x приводит к изменению математического ожидания случайной величины y , называется корреляционной.
Функцией регрессии (уравнением регрессии) y на x называется функция,
описывающая изменение условного математического ожидания (среднего значения) зависимой переменной y при изменении x :
M (y / x)= f (x). |
(1.1.1) |
График f (x) называется линией регрессии. Если |
f (x)= const , то |
корреляционная зависимость отсутствует.
Реальное значение зависимой переменной y не всегда совпадает с ее
условным математическим ожиданием |
M (y / x). Чтобы отразить |
20
статистическую суть зависимости, вводят случайную составляющую u , которая является случайной величиной. Таким образом, связь между зависимой
и объясняющей переменными можно выразить следующей формулой: |
|
y = f (x)+u , |
(1.1.2) |
которая называется регрессионной моделью.
В зависимости от количества факторов регрессионные модели подразделяются на модели парной регрессии и модели множественной регрессии. В парной регрессионной модели результативная переменная зависит только от одной факторной переменной.
Отметим характерную особенность эконометрической модели – наличие двух составляющих: неслучайная составляющая f (x) – это часть зависимой переменной, которая полностью объясняется значением независимой переменной x , случайная составляющая u – часть зависимой переменной, которая не может быть объяснена значением x .
Построение регрессионной модели выполняется в несколько этапов:
•спецификация модели;
•сбор статистической информации;
•оценка параметров модели (параметризация);
•проверка адекватности модели (верификация). Остановимся чуть подробнее на каждом из этапов.
На этапе спецификации модели определяется набор экономических
переменных, описывающих функционирование системы, и устанавливается их взаимосвязь. Основная задача, решаемая на этом этапе, – выбор вида функции регрессии в эконометрической модели. В зависимости от типа уравнения регрессии регрессионные модели подразделяются на линейные и нелинейные.
В случае парной регрессии формулу связи выбирают по графическому представлению данных наблюдений в виде точек в декартовой системе координат. Такой график называется корреляционным полем (диаграммой рассеяния). На рис. 1.1.1 изображены три ситуации. На графике (а) взаимосвязь
21
x и y близка к линии. На графике (б) связь, скорее всего, описывается нелинейной функцией, а на графике (в) взаимосвязь между x и y отсутствует.
Рис. 1.1.1
Основой эконометрических моделей являются статистические данные, сбор которых осуществляется на втором этапе. В эконометрике рассматривается два типа выборочных данных.
Пространственными являются данные по некоторому экономическому показателю, полученные для разных объектов за один и тот же период или момент времени. Например, данные о количестве работников, доходе разных фирм в один и тот же момент времени.
Временные данные (временные ряды) – это данные, характеризующие один и тот же объект в различные моменты времени. Например, месячные или ежеквартальные данные о средней заработной плате, инфляции, ежедневный курс доллара. Отличительной особенностью временных данных является упорядоченность этих данных по времени. Кроме того, наблюдения в близкие моменты времени часто бывают зависимы.
На третьем этапе определяются параметры модели. При этом следует иметь в виду, что на практике множество возможных реализаций экономических показателей (генеральная совокупность) неизвестно. Исследователь располагает выборочными значениями показателей (выборочная совокупность), с помощью которых можно оценить, а не определить точно значения параметров модели. Эти оценки являются случайными. Цель оценивания – получить как можно более точные значения неизвестных параметров генеральной совокупности.
22
На четвертом этапе проверяется соответствие модели эмпирическим данным. Если модель неадекватна, то снова выполняются этапы построения модели и параметризации.
Если эконометрическая модель удовлетворяет всем требованиям качества, то она может быть использована для задач анализа и прогнозирования исследуемых экономических процессов. Процесс построения, изучения и применения эконометрических моделей называется эконометрическим моделированием.
Предпосылки модели
Парная линейная регрессионная модель имеет вид
y=a0 +a1x + u , |
(1.1.3) |
где y – зависимая переменная – результативный признак (случайная величина); x – факторная переменная (детерминированная величина); a0, a1 – параметры модели (постоянные неизвестные коэффициенты); u – случайное возмущение или отклонение (случайная величина), характеризующее отклонение от уравнения регрессии f (x)=a0 +a1x (теоретической линейной зависимости).
Наличие случайного члена u (ошибки регрессии) связано с воздействием на зависимую переменную других неучтенных в уравнении факторов, с возможной нелинейностью модели и ошибками измерения.
Уравнения для отдельных наблюдений зависимой переменной y
записываются в виде
yi =a0 +a1xi + ui , |
|
|
(1.1.4) |
|
где (xi , yi ), i =1, K, n – выборочные |
данные |
(наблюдения), n |
– |
объем |
выборки (количество наблюдений). |
|
|
|
|
Относительно возмущений ui , i =1, |
K, n , |
в регрессионных |
моделях |
|
принимают следующие предположения (условия Гаусса – Маркова): |
|
|
||
1. Математическое ожидание (среднее значение) возмущения |
ui |
равно |
||
нулю: |
|
|
|
|
|
23 |
|
M [ui ]= 0 , |
i =1, K, n . |
(1.1.5) |
2. Дисперсия возмущения постоянна для любых значений i |
(условие гомо- |
|
скедастичности): |
|
|
D[ui ]= const =σ2 , i =1, K, n . |
(1.1.6) |
|
Зависимость дисперсии возмущения от номера наблюдения называется
гетероскедастичностью.
3. Возмущения для разных наблюдений являются некоррелированными:
cov u |
,u |
|
= 0 при i ≠ j , |
(1.1.7) |
i |
|
j |
|
|
т. е. предполагается отсутствие систематической связи между значениями случайного члена в любых двух наблюдениях i и j. В случае нарушения данного условия говорят об автокорреляции возмущений.
4.x – детерминированная (неслучайная) величина.
5.Возмущения являются нормально распределенными случайными
величинами с нулевым средним значением и дисперсией σ2 : |
|
ui ~ N (0,σ 2 ). |
(1.1.8) |
Регрессионная модель с учетом условий Гаусса-Маркова (1.1.5)-(1.1.7)
называется классической регрессионной моделью. Если в предпосылки регрессионной модели включено условие нормального распределения возмущения, то модель называется классической нормальной регрессионной моделью.
Для получения уравнения регрессии достаточно первых четырех предпосылок. Требование выполнения пятой предпосылки необходимо для оценки точности уравнения регрессии и его параметров.
Точные значения параметров модели могут быть определены с использованием значений переменных x и y всей генеральной совокупности,
что практически невозможно. Поэтому задача линейного регрессионного анализа состоит в том, чтобы по имеющимся статистическим данным (xi , yi ), i =1, K, n , для переменных x и y получить наилучшие оценки неизвестных
24
параметров. Следовательно, по выборке нужно построить так называемое
эмпирическое (выборочное) уравнение регрессии |
|
yˆ =b0 + b1x , |
(1.1.9) |
где yˆ – оценка условного математического ожидания, |
b0, b1 – оценки |
неизвестных параметров a0 и a1, называемые коэффициентами регрессии.
Для оценки параметров a0 и a1 обычно применяют метод наименьших квадратов (МНК). Существуют и другие методы оценки параметров, например метод моментов, метод максимального правдоподобия.
Оценка параметров парной регрессии методом наименьших квадратов
Пусть по выборке (xi , yi ), i =1, K, n , требуется определить оценки b0, b1,
т. е. построить выборочное уравнение регрессии (1.1.9) yˆ =b0 + b1x .
Очевидно, наблюдаемые значения yi не будут совпадать с расчетными значениями, вычисленными по формуле (1.1.9): yˆi =b0 + b1xi . Обозначим через ei разность
(1.1.10)
Случайная величина ei называется остатком регрессии в i-м наблюдении.
Методом наименьших квадратов называется метод нахождения неизвестных параметров функции регрессии из условия, чтобы сумма квадратов остатков была минимальной:
|
n |
n |
− yˆ |
)2 |
n |
−b |
−b x )2 |
→ min . |
(1.1.11) |
Q(b ,b )= ∑e2 |
= ∑(y |
= ∑(y |
|||||||
0 1 |
i |
i |
i |
|
i |
0 |
1 i |
|
|
|
i=1 |
i=1 |
|
|
i=1 |
|
|
|
|
25
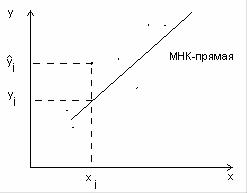
С геометрической точки зрения минимизация суммы квадратов отклонений (1.1.11) означает выбор прямой, которая ближе всего “прилегает” по ординатам к системе выборочных точек (xj,yj), что показано на рис. 1.1.2.
Рис. 1.1.2.
Нетрудно заметить, что функция Q является квадратичной функцией двух параметров b0 и b1, поскольку xi , yi , i =1, K, n – известные данные наблюдений.
Так как функция Q непрерывна, выпукла и ограничена снизу (Q ≥ 0 ), то она имеет минимум. Необходимым условием существования минимума функции двух переменных является равенство нулю ее частных производных по неизвестным параметрам b0 и b1:
|
∂Q |
= −2∑(y −b −b x |
)= 0; |
||
|
|
||||
|
∂b |
i |
0 1 i |
|
|
|
|
|
|
||
|
0 |
|
= −2∑(yi |
−b0 −b1 xi )xi = 0. |
|
|
∂Q |
|
|||
|
∂b1 |
||||
|
|
|
|
||
После преобразований получим следующую систему нормальных уравнений:
nb |
+ b |
∑x |
= ∑ y ; |
|
|||||
|
|
0 |
|
1 |
|
i |
|
i |
(1.1.12) |
|
|
|
|
|
|
∑x2 |
|
||
b |
∑x |
+ b |
= ∑x y . |
|
|||||
|
0 |
|
i |
|
1 |
|
i |
i i |
|
Разделив оба уравнения системы (1.1.12) на n , получим:
|
|
|
|
|
b |
+ b x = y; |
|
|
|
|
|
|
|||||
|
|
|
|
|
|
0 |
|
1 |
|
|
|
|
|
|
|
|
(1.1.13) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
b x + b x2 |
= |
|
, |
|
|
|
|
|||||
|
|
|
|
xy |
|
|
|
|
|||||||||
|
|
|
|
|
|
0 |
|
1 |
|
|
|
|
|
|
|
|
|
|
|
1 ∑x , |
|
= 1 |
∑x2 |
, y = 1 |
|
|
|
1 ∑x y - соответствующие |
|||||||
где |
x = |
x2 |
∑ y , |
|
= |
||||||||||||
xy |
|||||||||||||||||
|
|
n |
i |
|
n |
|
i |
|
|
n |
|
i |
|
|
n |
i i |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
выборочные средние.
|
|
|
|
|
26 |
|
|
||
Решения системы (1.1.13) имеют вид |
|
|
|||||||
b = |
|
|
− x y |
= |
cov(x, y) |
, |
|
|
|
xy |
b |
= y −b x , |
|||||||
|
|
|
|
|
|||||
1 |
|
x2 − x 2 |
|
Sx2 |
0 |
1 |
|||
|
|
|
|
|
|||||
где Sx2 – выборочная дисперсия переменной x:
|
|
1 |
n |
(x − x )2 |
|
|
|
|
S2 |
= |
=x2 |
− x 2 , |
|||||
∑ |
||||||||
x |
|
n i=1 |
i |
|
|
|
||
(1.1.14)
(1.1.15)
cov(x, y) – выборочная ковариация:
|
1 |
n |
|
|
|
|
|
cov(x, y)= |
∑ |
(x |
− x )(y − y )= xy − x y . |
(1.1.16) |
|||
|
n i=1 |
i |
i |
|
|||
В некоторых случаях удобно использовать иную форму записи этих решений:
|
n |
|
n |
n |
|
|
|
n∑xi yi − ∑xi |
∑ yi |
||||
b = |
1 |
|
1 |
1 |
, |
|
|
|
|
|
|||
1 |
n |
|
n |
2 |
||
|
− |
|||||
|
n∑x2 |
|
∑x |
|
|
|
|
i |
|
i |
|
||
1 |
|
|
i |
|
|
|
b |
= |
1 |
n |
|
−b |
1 |
n |
|
(1.1.17) |
∑ y |
∑x . |
||||||||
0 |
|
n 1 |
i |
1 n 1 |
i |
|
|||
Подставляя значение b0 = y −b1x в уравнение регрессии (1.1.9), получим
ˆ |
− |
y |
= |
b1 |
(x |
− |
x ). |
(1.1.18) |
y |
|
|
|
Из полученного уравнения следует, что линия регрессии проходит через точку (x, y ), т. е. y =b0 + b1x .
Коэффициент b1 при x называется коэффициентом регрессии. Как следует из (1.1.18), b1 показывает, на сколько единиц в среднем изменяется переменная y при увеличении переменной x на одну единицу. Коэффициент b0 –
смещение, равен значению yˆ при x = 0 и может не иметь экономического содержания.

27
Пример 1.1.1
В табл. 1.1.1 приведены данные о зависимости объема продаж y (тыс. шт.)
от расходов на рекламу x (усл. ед.) по 8 предприятиям концерна.
Таблица 1.1.1
|
x |
0,8 |
|
1 |
1,7 |
|
2,6 |
|
4,1 |
5,4 |
7,2 |
8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
y |
4,6 |
|
6,6 |
12 |
|
15 |
|
21 |
25 |
24 |
26 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Полагая, |
что между |
x и y |
имеет место линейная зависимость, построить |
|||||||||
выборочное уравнение линейной регрессии. |
|
|
|
|
|
||||||||
Решение. Коэффициенты регрессии b1, b0 вычислим по формулам (1.1.17).
Для удобства вычисления сумм оформим в виде табл. 1.1.2.
Таблица 1.1.2
№ п/п |
x |
y |
xy |
x2 |
y2 |
1 |
0,8 |
5,6 |
4,48 |
0,64 |
31,36 |
2 |
1 |
6,6 |
6,6 |
1 |
43,56 |
3 |
1,7 |
12 |
20,4 |
2,89 |
144 |
4 |
2,6 |
15 |
39 |
6,76 |
225 |
5 |
4,1 |
21 |
86,1 |
16,81 |
441 |
6 |
5,4 |
25 |
135 |
29,16 |
625 |
7 |
7,2 |
24 |
172,8 |
51,84 |
576 |
8 |
8 |
26 |
208 |
64 |
676 |
|
|
|
|
|
|
Сумма |
30,8 |
135,2 |
672,38 |
173,1 |
18279,04 |
Среднее |
3,85 |
16,9 |
84,0475 |
21,637 |
285,61 |
|
|
|
|
|
|
В результате получим
b |
= |
xy |
− x y |
= 84,05 −3,85 |
16,9 = 2,78 , |
||||
1 |
|
|
x |
2 |
− x |
2 |
21,64 −3,85 |
3,85 |
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
||
b0 = y − b1 x =16,9 − 2,78 3,85 = 6,18.
Таким образом, уравнение парной линейной регрессии имеет вид yˆ = 6,18 + 2,78x .
28
Полученные значения коэффициентов легко проверить с помощью стандартных статистических функций MS Excel НАКЛОН(Y;X) и ОТРЕЗОК(Y;X) соответственно.
Величина b1 показывает, что с увеличением расходов на рекламу на 1 усл.
ед. объем продаж предприятия возрастает в среднем на 2,78 тыс. шт. Величина b0 имеет значение объема продаж предприятия в случае отсутствия рекламы.
Статистические свойства МНК-оценок
Рассмотрим вопросы качества и точности полученных оценок. Найденные по МНК коэффициенты являются лишь выборочными
точечными оценками истинных параметров регрессии. Выборочные оценки b0
и b1 являются случайными величинами, так как зависят от выборки xi и yi , а
также от метода расчета. Критериями качества точечных оценок в статистике являются такие их свойства, как несмещенность, состоятельность и эффективность.
Учитывая, что y = a0 + a1x + u , и воспользовавшись разложением
cov(x, y)= cov(x,a0 + a1x + u)= a1 cov(x, x)+ cov(x,u)= a1Sx2 + cov(x,u),
выражения (1.1.14) для b0 и b1 можно представить в эквивалентном виде
|
|
|
cov(x,u) |
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
x cov(x, u) |
|
||||||
b1 |
= a1 |
+ |
; |
b0 |
= a0 |
+ |
∑ui |
− |
. |
(1.1.19) |
|||||
Sx2 |
|
|
|||||||||||||
|
|
|
|
|
|
n i=1 |
|
|
S x2 |
|
|
||||
Таким образом, выборочные коэффициенты регрессии представлены в виде суммы постоянной составляющей (истинного значения) и случайной составляющей, зависящей от случайного отклонения модели u , а значит, и от свойств u .
Из (1.1.19) находятся статистические характеристики коэффициентов b0 и
b1.
Математические ожидания: |
|
|
M (b1)= a1, |
M (b0 )= a0 . |
(1.1.20) |
|
|
|
|
|
|
|
29 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Дисперсии: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
D(b )= |
σ2 |
, D(b |
)= |
σ2 |
|
|
|
|
. |
|
|
|
|||||||||
|
|
|
x2 |
|
|
(1.1.21) |
|||||||||||||||||
|
|
|
|
|
|
||||||||||||||||||
|
|
1 |
|
nSx2 |
|
0 |
|
|
nSx2 |
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
Ковариационная матрица: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
cov(b ,b |
) |
cov(b ,b |
) |
|
|
|
2 |
|
|
|
|
|
|
|
|
|||||||
|
|
|
σ |
|
|
2 |
|
|
|
||||||||||||||
C |
= |
0 0 |
) |
0 |
1 |
|
= |
|
|
|
x |
|
|
|
− x . |
(1.1.22) |
|||||||
|
,b |
cov(b |
,b |
|
2 |
|
|
|
|||||||||||||||
b |
cov(b |
) |
|
|
|
|
−x |
1 |
|
|
|||||||||||||
|
|
1 0 |
|
1 1 |
|
|
|
nSx |
|
|
|
||||||||||||
Из выражений (1.1.20)-(1.1.22) следует, что оценки параметров b0 и b1
являются несмещенными (математическое ожидание оценки равно истинному значению) и состоятельными. Действительно, оценка состоятельна, если сходится по вероятности к истинному значению параметра. Для несмещенных оценок достаточным условием сходимости является сходимость их дисперсии к нулю при неограниченном возрастании объема выборки. Справедлива также теорема Гаусса-Маркова.
Теорема Гаусса-Маркова. Если регрессионная модель (1.1.3) удовлетворяет условиям (1.1.5)-(1.1.8), то МНК-оценки имеют наименьшую дисперсию в классе всех линейных несмещенных оценок (являются эффективными оценками).
Несмещенной оценкой дисперсии возмущений σ2 является величина
|
2 |
= |
1 |
n |
2 |
= |
1 |
∑(yi |
− ˆ |
2 |
|
|
|
|
|
|
|
|
|
||||||
S |
|
|
n − 2 i∑=1ei |
|
n − 2 |
yi ) |
|
, |
(1.1.23) |
|||
которая служит мерой разброса зависимой переменной и называется
остаточной дисперсией. Величина S называется стандартной ошибкой регрессии.
Несмещенные оценки дисперсий коэффициентов b0 и b1 получаются путем
замены в (1.1.21) неизвестного |
значения |
дисперсии возмущения |
σ2 его |
||||||||
оценкой (1.1.23): |
|
|
|
|
|
|
|
|
|
|
|
S2 |
|
S2 |
|
S2 |
|
S2 |
|
|
. |
|
|
= |
, |
= |
|
x2 |
(1.1.24) |
||||||
2 |
2 |
||||||||||
b1 |
|
|
b0 |
|
|
|
|
|
|||
|
|
nSx |
|
|
|
nSx |
|
|
|
|
|
30
Величины Sb1 и Sb0 – стандартные отклонения (ошибки) МНК-
коэффициентов регрессии.
После этапа оценивания модели следует этап проверки ее качества, который включает:
•проверку статистической значимости оценок параметров регрессии;
•построение доверительных интервалов параметров регрессии, дающих определенные гарантии точности их оценок;
•проверку общего качества уравнения регрессии;
•проверку качества прогнозов результативного признака.
Пример 1.1.2
Для данных примера 1.1.1 рассчитать стандартную ошибку регрессии и стандартные ошибки коэффициентов регрессии.
Решение. Подставляя рассчитанные в примере 1.1.1 значения b0 и b1 в
формулу yˆi = b0 + b1 xi , найдем значения yˆi и разместим их в седьмом столбце табл. 1.1.3.
Таблица 1.1.3
|
|
|
|
|
|
|
|
|
|
|
|
|||
№ п/п |
xy |
y |
xy |
x |
2 |
y |
2 |
yˆ |
e |
2 |
( ) |
|||
|
|
|
|
|
|
2 |
||||||||
|
|
|
y −y |
|||||||||||
|
|
|
|
|
|
|
|
|||||||
1 |
0,8 |
5,6 |
4,48 |
0,64 |
31,36 |
8,404 |
7,8624 |
127,69 |
||||||
2 |
1 |
6,6 |
6,6 |
1 |
|
43,56 |
8,96 |
5,5696 |
106,09 |
|||||
3 |
1,7 |
12 |
20,4 |
2,89 |
144 |
|
10,906 |
1,1968 |
24,01 |
|
||||
4 |
2,6 |
15 |
39 |
6,76 |
225 |
|
13,408 |
2,5345 |
3,61 |
|
|
|
||
5 |
4,1 |
21 |
86,1 |
16,81 |
441 |
17,578 |
11,71 |
16,81 |
|
|
||||
6 |
5,4 |
25 |
135 |
29,16 |
625 |
21,192 |
14,501 |
65,61 |
|
|||||
7 |
7,2 |
24 |
172,8 |
51,84 |
576 |
26,196 |
4,8224 |
50,41 |
|
|||||
8 |
8 |
26 |
208 |
64 |
|
676 |
28,42 |
5,8564 |
82,81 |
|
|
|||
|
|
|
|
|
|
|
|
|
||||||
Сумма |
30,8 |
135,2 |
672,38 |
173,1 |
2761,92 |
|
54,053 |
477,04 |
||||||
Среднее |
3,85 |
16,9 |
84,0475 |
21,6375 |
345,24 |
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
31
В восьмом столбце таблицы рассчитаем значения (yi − yˆi )2 . Вычислив
соответствующие суммы, найдем несмещенную оценку дисперсии ошибки σ2 по формуле (1.1.23) и оценки дисперсий коэффициентов регрессии по формулам (1.1.24):
|
S 2 |
|
54,053 |
|
|
− |
|
2 = 21,6375 − 3,852 |
|
|||
|
= |
= 9,008, |
S x2 = |
x2 |
= 6,815, |
|||||||
|
x |
|||||||||||
|
|
8 − 2 |
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Sb2 |
= |
9,01 |
|
= 0,1652 , |
Sb2 |
= 0,165 21,64 = 3,575. |
|
||||
|
|
8 6,815 |
|
|||||||||
|
1 |
|
|
|
0 |
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|||
|
Значения соответствующих стандартных ошибок S = 3,00 , |
Sb = 0,406 , |
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
1 |
Sb |
=1,89. |
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
ВОПРОСЫ ДЛЯ САМОПРОВЕРКИ
1.Какая зависимость называется статистической?
2.Какая связь между переменными называется корреляционной?
3.Какая функция называется функцией регрессии?
4.Чем отличаются парная и множественная регрессионные модели?
5.Перечислите этапы построения модели регрессии.
6.Как выглядит линейная модель парной регрессии?
7.Каковы предпосылки классической регрессионной модели?
8.Назовите основные причины наличия в регрессионной модели случайного отклонения.
9.В чем суть метода наименьших квадратов (МНК) и для чего он используется?
10.Приведите формулы расчета оценок коэффициентов линейной модели по МНК.
11.Дайте содержательную интерпретацию коэффициента регрессии в линейном парном уравнении регрессии?
12.Какими свойствами обладают МНК-оценки классической линейной эконометрической модели?
13.Как оценивается дисперсия истинной ошибки модели?

32
1.2. Оценка качества модели парной регрессии
Изучаемые вопросы:
показатели качества регрессии;
проверка значимости коэффициентов парной регрессии.
При работе с теоретическим материалом следует разобрать примеры решения задач и ответить на контрольные вопросы, приведенные в конце темы.
Показатели качества регрессии
Качество уравнения регрессии оценивается по тому, как хорошо уравнение регрессии согласуется со статистическими данными. Другими словами, насколько широко рассеяны точки наблюдений относительно линии регрессии.
Пусть на основе выборочных наблюдений (xi , yi ), i =1, n построено уравнение регрессии, тогда значение зависимой переменной y в каждом наблюдении можно разложить на две составляющие: yi = yˆi +ei . В качестве меры общего разброса значений зависимой переменной y вокруг среднего значения y возьмем сумму квадратов отклонений (вариацию) y от y . Общая вариация может быть разложена на две составляющие:
∑(yi |
− |
|
2 |
= |
∑ |
( |
yi |
− ˆ |
)2 + |
ˆ |
− |
|
2 |
(1.2.1) |
|
|
|||||||||||||
|
y) |
|
|
yi |
|
∑(yi |
|
y) . |
||||||
i |
|
|
|
|
i |
|
|
|
|
i |
|
|
|
|
Часто уравнение (1.2.1) записывают в следующих обозначениях:
TSS=ESS+RSS,
где |
|
|
|
|
|
|
|
|
TSS= ∑(yi |
− |
|
|
)2 |
– |
общая сумма |
квадратов отклонений зависимой |
|
|
y |
|||||||
i |
|
|
|
|
|
|
|
|
переменной от ее среднего выборочного значения (total sum of squares); |
||||||||
ˆ |
− |
|
|
2 |
|
|
|
|
RSS= ∑(yi |
|
|
y) |
– |
сумма квадратов, |
объясненная регрессией (regression |
||
i
sum of squares);
33
ESS= ∑(yi − yˆi )2 |
– |
необъясненная регрессией |
(остаточная) сумма |
||||
i |
|
|
|
|
|
|
|
квадратов отклонений (error sum of squares). |
|
||||||
Мерой качества уравнения регрессии является коэффициент детерминации. |
|||||||
Коэффициентом детерминации называется отношение |
|
||||||
|
R2 |
= |
RSS |
=1 − |
ESS |
. |
(1.2.2) |
|
TSS |
|
|||||
|
|
|
|
TSS |
|
||
Величина R2 показывает, какая доля вариации зависимой переменной обусловлена вариацией объясняющей переменной.
Из формулы (1.2.2) следует, что в общем случае справедливо соотношение
0 ≤ R2 ≤1. При R2 = 0 вариация зависимой переменной полностью обусловлена
воздействием неучтенных в модели переменных |
(случайных факторов) |
и |
|||
линия регрессии параллельна оси абсцисс yˆi = |
|
|
( RSS = |
0 , ESS =TSS ). При |
|
y |
|||||
R2 =1 все точки наблюдения лежат на регрессионной прямой и между x и |
y |
||||
имеется линейная функциональная зависимость, |
т. е. |
yi = yˆi , ( ESS = 0 , |
|||
RSS =TSS ). |
|
|
|
||
Таким образом, чем ближе значение коэффициента детерминации к 1, тем лучше качество подгонки регрессионной модели к наблюденным значениям yi .
Заметим, что вычисление R2 корректно лишь в том случае, когда константа b0 включена в уравнение регрессии. Только в этом случае справедливо разложение (1.2.1).
Для определения статистической значимости коэффициента детерминации
R2 проверяется гипотеза H0 : F = 0 |
для F-статистики, |
рассчитываемой по |
||||
формуле |
|
|
|
|
|
|
F = |
R 2 |
(n − 2) |
. |
(1.2.3) |
||
|
|
|
|
|||

34
F = 0 в том случае, если R 2 = 0 . Поэтому, проверяя значимость F- статистики, мы можем проверить статистическую значимость коэффициента детерминации.
Величина F имеет распределение Фишера с ν1 =1, |
ν2 |
= n − 2 |
|
степенями |
|||||||||||||||||||||||||||||||||||
свободы. Вычисленный критерий F сравнивается с критическим значением Fкр . |
|||||||||||||||||||||||||||||||||||||||
Если F < F |
|
|
, то |
H |
0 |
|
принимается, т. е. |
R2 |
незначим; |
если |
F > F |
|
|
, |
то |
H |
0 |
||||||||||||||||||||||
|
|
кр |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
кр |
|
|
|
|||||||
отклоняется, т. е. R2 значим. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
В случае парной |
регрессии коэффициент |
детерминации совпадает |
|
с |
|||||||||||||||||||||||||||||||||||
квадратом коэффициента корреляции переменных x |
и y , т. е. |
R 2 |
= rx2, y . |
|
|
||||||||||||||||||||||||||||||||||
Коэффициент линейной парной корреляции – показатель тесноты линейной |
|||||||||||||||||||||||||||||||||||||||
связи между признаками x и y : |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
r = r |
= |
cov(x, y) |
=b |
Sx |
, |
|
|
|
|
|
|
|
|
|
|
(1.2.4) |
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
xy |
|
|
SxSy |
|
|
1 Sy |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
где Sx и Sy |
|
|
– средние квадратические отклонения фактора и результативного |
||||||||||||||||||||||||||||||||||||
признака соответственно. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
Коэффициент r – безразмерная величина, лежащая в пределах |
|
|
−1≤ r ≤1. |
||||||||||||||||||||||||||||||||||||
Чем ближе |
|
r |
|
к единице, тем теснее связь. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
При r = ±1 корреляционная связь представляет линейную функциональную |
|||||||||||||||||||||||||||||||||||||||
зависимость. При r = 0 линейная корреляционная связь отсутствует. |
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||
При r > 0 (b1 > 0 ) корреляционная связь между переменными называется |
|||||||||||||||||||||||||||||||||||||||
прямой, при r < 0 (b1 < 0 ) – обратной. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
Для практических расчетов удобной является следующая формула: |
|
|
|
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
n |
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n ∑ xi yi |
− |
|
∑ xi |
∑ yi |
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
xy − x y |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
r = |
|
|
|
|
|
|
|
|
|
= |
|
|
|
i=1 |
|
|
|
i=1 |
i=1 |
|
|
|
|
|
. |
(1.2.5) |
|||||||||||||
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
2 |
||||||||
x |
2 |
|
− x |
|
y |
2 |
− y |
|
|
n |
− |
n |
|
|
n |
|
|
n |
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
n ∑ x2 |
∑ x |
|
n ∑ y2 − |
∑ y |
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
i |
|
|
|
i |
|
|
i=1 |
i |
|
i |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
i=1 |
|
i=1 |
|
|
|
|
i |
=1 |
|
|
|
|
|
|
|
|
|||

35
Еще одним показателем качества модели регрессии является средняя ошибка аппроксимации:
A = 1n |
∑ |
yi − yˆi |
|
. |
(1.2.6) |
y |
|||||
|
|
i |
|
|
|
Чем меньше рассеяние эмпирических точек вокруг теоретической линии регрессии, тем меньше средняя ошибка аппроксимации. Ошибка аппроксимации меньше 7 % свидетельствует о хорошем качестве модели.
Пример 1.2.1
Для данных примера 1.1.1 рассчитать выборочный коэффициент корреляции.
Решение. Выборочный коэффициент корреляции вычислим по формуле
(1.2.5) с использованием средних значений из таблицы 1.1.2: |
|
||||||||||||||||||
|
|
|
|
|
|
|
− |
|
|
|
|
|
|
|
|
|
84,055 − 3,85 16,9 |
|
|
r = |
|
|
|
xy |
x |
y |
= |
= 0,94 . |
|||||||||||
|
|
− |
|
2 |
|
|
|
− |
|
2 |
21,64 − 3,852 345,24 −16,92 |
||||||||
x2 |
y2 |
||||||||||||||||||
|
|
x |
y |
|
|
||||||||||||||
Полученное значение можно проверить с помощью стандартной
статистической функции КОРРЕЛ(X;Y).
Пример 1.2.2
Вычислить коэффициент детерминации R2 и F-статистику для регрессии, оцененной в примере 1.1.1.
Решение. По формуле (1.2.2) рассчитаем величину выборочного коэффициента детерминации. Значения ESS и TSS вычислены в табл. 1.1.3 и
расположены в строке “сумма” восьмого и девятого столбцов.
|
R2 =1 − 54,053 |
= 0,8867 . |
|
|
|
477,04 |
|
Значение F-статистики вычислим по формуле (1.2.3): |
|||
F |
|
= 0,8867(8 −2) |
= 47,0 . |
факт |
1−0,8867 |
|
|
|
|
|
|
36 |
|
При уровне значимости α = 5 % , степенях свободы ν1 =1, |
ν2 =8 − 2 = 6 |
критическое значение критерия Фишера Fкр = 6,0 , т. е. Fфакт > Fкр. |
|
Критическое значение Fкр можно определить в Excel |
при помощи |
функции Fраспобр. Параметры функции: вероятность – уровень значимости
α , число степеней свободы 1 – для парной регрессии 1, число степеней свободы 2 – для парной регрессии 2.
Проверка значимости коэффициентов парной регрессии
При проверке качества модели наиболее важной является задача установления наличия линейной зависимости между результативной и факторной переменными.
Мы выбрали регрессионную модель в виде (1.1.3). В действительности может оказаться, что фактор x не влияет на результативный признак, и потому параметр a1 должен быть равен нулю. Значение оценки b1, найденное для конкретной выборки, при этом может быть отличным от нуля. Для проверки существенности отклонения b1 от нуля проверяется значимость коэффициента.
Проверка значимости коэффициента b1 |
означает |
проверку гипотезы |
||
H0 : a1 = 0 против альтернативной гипотезы |
H1 : a1 ≠ 0 . Коэффициент b1 |
|||
считают значимым (значимо отличающимся от нуля), если верна гипотеза H1 . |
||||
В качестве статистики для проверки гипотезы H0 принимается отношение |
||||
коэффициента регрессии к его стандартной ошибке t = |
|
b1 |
. При выполнении |
|
|
|
|||
|
|
Sb |
||
|
|
|
1 |
|
исходных предпосылок модели эта величина имеет распределение Стьюдента с числом степеней свободы ν = n −2 , где n – число наблюдений.
Если модуль вычисленного по выборке (фактического) значения
статистики превысит критический уровень tкр : |
|
tфакт |
≥ tкр, |
то гипотезу |
H0 |
следует отклонить на уровне значимости α |
и признать |
коэффициент |
b1 |
||
значимым. |
|
|
|
|
|

37
В противном случае, т. е. при tфакт ≤ tкр, коэффициент b1 незначим, и
фактор x исключают из модели.
Аналогично проверяется значимость оценки параметра a0 , однако параметр a1 в парной регрессии имеет более важную роль, так как его значимость соответствует наличию линейной связи между переменными модели.
Большинство статистических пакетов выводят t-статистику для рассмотренного случая. Однако если имеется основание предполагать, что
величина |
a |
равна некоторой заданной величине |
a0 , то проверяют гипотезы |
||||||
|
|
|
1 |
|
|
|
|
1 |
|
H |
0 |
: a = a0 , |
H : a ≠ a0 |
. Если по выборке получена оценка |
b , то в качестве |
||||
|
1 |
1 |
1 |
1 |
1 |
|
|
1 |
|
критерия проверки гипотезы используют t-статистику вида |
|
||||||||
|
|
|
|
|
|
|
b −a0 |
|
(1.2.7) |
|
|
|
|
|
|
|
t = 1 1 . |
|
|
|
|
|
|
|
|
|
Sb |
|
|
|
|
|
|
|
|
|
1 |
|
|
Правило принятия решения аналогичное.
Задаваясь некоторым уровнем значимости α , по таблицам t-распределения можно определить критическое значение статистики tкр, задающее границы доверительного интервала, который с доверительной вероятностью накрывает значение статистики t, т. е. удовлетворяющее условию
P(t < tкр)= P(−tкр < t < tкр)=1−α .
Подставив в это равенство вместо t-статистики:
t = |
b0 − a0 |
, |
t = |
b1 −a1 |
, |
|
|
||||
|
Sb |
|
Sb |
||
0 |
|
1 |
|
||
получаем следующие доверительные интервалы для параметров b0 −tкр Sb0 < a0 < b0 +tкр Sb0 ,
(1.2.8)
a0 и a1 :
b1 |
−tкр Sb |
< a1 |
< b1 |
+tкр Sb . |
(1.2.9) |
|
1 |
|
|
1 |
|
38
Если в границы доверительного интервала попадает ноль, то оцениваемый коэффициент принимается нулевым, так как он не может одновременно принимать и положительное, и отрицательное значения.
Пример 1.2.3
Выполнить проверку значимости коэффициента b1, оцененного в примере
1.1.1, для уровня значимости α =5 % .
Решение. Оцененную регрессионную модель обычно записывают следующим образом:
yi =b0 + b1 xi + ui
(Sb0 ) (Sb1 ) (S),
с учетом полученных оценок |
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
yi |
= 6,18 + 2,78 xi +ui . |
|
|||||||
|
|
|
|
|
|
(1,89) (0,406) |
(3,00) |
|
||||||
Для проверки значимости коэффициента b1 вычислим t-статистику и |
||||||||||||||
сравним ее значение с критическим |
|
tкр |
|
|
|
|
||||||||
|
tb |
|
= |
|
b1 |
|
|
= |
|
2,78 |
|
≈ 6,85 >tкр = 2,45 . |
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|||||||
|
|
Sb |
|
0,406 |
|
|||||||||
|
1 |
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Таким образом, нулевая гипотеза |
|
отвергается при уровне |
значимости |
|||||||||||
α = 5 % . Коэффициент признается |
значимым, |
а следовательно, |
значима и |
|||||||||||
факторная переменная x . |
|
|
|
|
|
|
|
|
|
|
||||
|
ВОПРОСЫ ДЛЯ САМОПРОВЕРКИ |
|
||||||||||||
1.Приведите формулу расчета коэффициента детерминации R2 . Что характеризует коэффициент детерминации? В каких пределах изменяется коэффициент детерминации для парной линейной регрессии?
2.Как связаны коэффициент корреляции и коэффициент детерминации для парной линейной регрессии?
3.Приведите формулу расчета выборочного коэффициента корреляции. Назовите основные свойства выборочного коэффициента корреляции.
39
4.Как связан коэффициент линейной регрессии с выборочным коэффициентом корреляции?
5.С помощью какого критерия проверяется значимость коэффициентов регрессии? Каков алгоритм проверки значимости коэффициентов регрессии?
1.3. Прогноз по модели парной регрессии
Изучаемые вопросы:
предсказание среднего значения;
предсказание индивидуального значения зависимой переменной;
использование MS Excel при решении задач регрессионного анализа. После изучения темы Вам следует ответить на вопросы для самопроверки.
Под прогнозированием в эконометрике понимается построение оценки зависимой переменной для значений независимой переменной, которых нет в исходных наблюдениях. Рассматривают два вида прогнозов для определенного значения факторной переменной: предсказание условного математического ожидания зависимой переменной (ожидаемого или среднего значения) и предсказание индивидуального значения зависимой переменной.
Предсказание среднего значения
Пусть построено уравнение парной регрессии yˆi = b0 +b1 xi . На основе построенной модели рассчитываются точечные и интервальные прогнозы. Точечный прогноз при x = x0 получается путем подстановки значения x = x0 в
уравнение регрессии:
(1.3.1) yˆ0 является точечной оценкой условного математического ожидания
(среднего значения) переменной y при x = x0 . Чтобы измерить точность полученной оценки и построить доверительный интервал для среднего

|
|
|
|
|
|
|
|
|
|
|
|
|
40 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
значения, необходимо найти дисперсию |
точечной оценки yˆ0 , по |
которой |
||||||||||||||||||||||||||||
формируется интервальная оценка. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
Воспользуемся уравнением регрессии (1.1.18): |
|
|
|
|||||||||||||||||||||||||||
|
|
|
|
|
yˆ0 = |
|
+b1(x0 − |
|
). |
|
|
|
|
|
|
|
|
|
|
|
(1.3.2) |
|||||||||
|
|
|
|
|
y |
x |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
Дисперсия оценки |
yˆ0 равна сумме дисперсий для независимых слагаемых |
|||||||||||||||||||||||||||||
выражения (1.3.2) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
D(yˆ0 )= D( |
|
)+ D(b1(x0 − |
|
))= D( |
|
|
|
)+(x0 − |
|
)2 D(b1). |
(1.3.3) |
|||||||||||||||
y |
x |
|
y |
x |
||||||||||||||||||||||||||
Подставляя в (1.3.3) дисперсию коэффициента регрессии (1.1.21) и |
||||||||||||||||||||||||||||||
дисперсию выборочной средней |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
n |
|
1 |
|
n |
|
|
|
|
|
|
1 |
|
|
|
|
|
|
2 |
|
||||||
|
|
D(y)= D 1 |
y |
= |
D |
|
|
y |
= |
|
|
|
|
σ 2n = σ |
|
, |
|
|||||||||||||
|
2 |
|
|
|
|
2 |
|
|
|
|||||||||||||||||||||
|
|
|
|
|
∑ i |
n |
|
∑ i |
|
|
n |
|
|
|
|
n |
|
|
||||||||||||
|
|
|
|
n i=1 |
|
|
i=1 |
|
|
|
|
|
|
|
|
|
|
|||||||||||||
получим |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
σ 2 |
|
σ 2 (x |
|
− |
|
)2 |
|
|
|
|
||||||||
|
|
|
|
|
D(yˆ0 )= |
|
|
x |
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
+ |
|
|
|
|
0 |
|
|
|
|
|
|
|
. |
|
|
(1.3.4) |
||||||||
|
|
|
|
|
n |
|
|
|
|
nD(x) |
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
Из формулы видно, что дисперсия предсказания убывает с ростом объема |
||||||||||||||||||||||||||||||
выборки n и она тем больше, чем больше |
x0 |
|
отклоняется от выборочного |
|||||||||||||||||||||||||||
среднего |
|
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
x |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
Заменяя в выражении (1.3.4) |
неизвестное значение дисперсии σ 2 на ее |
|||||||||||||||||||||||||||||
оценку S 2 , можно записать формулу для выборочной дисперсии оценки
среднего значения в точке x0
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
(x0 − x)2 |
|||
S |
2 |
= S |
2 |
|
+ |
||||
yˆ |
|
|
|
nD(x) |
|||||
|
|
|
n |
|
|||||
|
|
|
|
|
|
|
|
|
|
⎟. (1.3.5)
Если предпосылки (1.1.5)-(1.1.8) верны, то можно показать, что статистика
t = yˆ − (a0 + a1 x) имеет распределение Стьюдента с (n-2) степенями свободы.
S yˆ
41
Используя стандартную процедуру, рассмотренную выше, получим
доверительный интервал для функции регрессии |
|
yˆ − tкр S yˆ < a0 + a1 x < yˆ + tкр S yˆ . |
(1.3.6) |
Предсказание индивидуального значения зависимой переменной
При определении границ доверительного интервала для индивидуальных значений зависимой переменной следует включить в оценку суммарной дисперсии дисперсию, обусловленную рассеянием вокруг линии регрессии,
т. е. S 2 . В результате оценка дисперсии индивидуальных значений y0 при x = x0 равна
|
|
|
1 |
|
(x |
|
− |
|
)2 |
|
|
||
|
|
|
0 |
x |
|
|
|||||||
S 2 |
= S 2 1 |
+ |
|
+ |
|
|
|
|
|
, |
(1.3.7) |
||
n |
nD(x) |
||||||||||||
yˆ0 |
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|||
а границы доверительного интервала прогноза индивидуальных значений определяются по формуле
yˆ0 − tкр S yˆ0 < y0 < yˆ0 + tкр S yˆ0 . |
(1.3.8) |
Пример 1.3.1
Выполнить оценку объема продаж предприятия для значения расходов на рекламу x0 = 2 для исходных данных примера 1.1.1. Построить доверительные интервалы для оценок среднего и индивидуального значений объема продаж.
Решение. Используя уравнение регрессии с оцененными параметрами из примера 1.1.1 yˆ = 6,18 + 2,78x , получим оценку среднего значения объема продаж при x0 = 2
yˆ = 6,18 + 2,78 2 =11,74.
Для определения доверительного интервала вычислим оценку дисперсии значения зависимой переменной по формуле (1.3.5)

|
|
|
|
|
|
|
|
|
42 |
|
|
|
|
|
|
|
|
|
|
1 |
|
(x0 − |
|
)2 |
1 |
|
(2 − 3,85)2 |
|
|||||
2 |
|
2 |
|
x |
|
|
||||||||||
S yˆ |
= S |
|
|
|
+ |
|
|
|
|
|
= 9,01 |
|
+ |
|
|
=1,69 . |
|
|
nD(x) |
|
8 |
8 6,82 |
|||||||||||
|
|
|
n |
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таким образом, границы доверительного интервала среднего значения прибыли, в соответствии с формулой (1.3.7), равны
11,74 − 2,45 1,69 =8,56; |
11,74 + 2,45 1,69 =14,93. |
Для определения границ доверительного интервала для отдельных индивидуальных значений зависимой переменной необходимо вычислить оценку дисперсии ошибки по формуле (1.3.7). Границы доверительного интервала индивидуальных значений y равны
11,74 − 2,45 3,271 = 7,31; |
11,74 + 2,45 3,271 =16,17 . |
Использование MS Excel при решении задач регрессионного анализа
Оценка параметров парной регрессионной модели, а также вычисление статистик, позволяющих проверить качество оцененной модели, могут быть выполнены в Excel при помощи функции ЛИНЕЙН.
Порядок работы с функцией ЛИНЕЙН:
•выделите область для размещения результата – два столбца и пять строчек;
•вызовите функцию ЛИНЕЙН;
•заполните строчки окна функции: столбец значений результативной переменной; столбец значений факторной переменной; значение параметра Конс (0 – для модели без свободного члена, 1 – для модели со свободным членом); значение параметра Стат (0 – оцениваются только параметры модели, 1 – оцениваются параметры модели и статистики, позволяющие проверить качество модели);
•нажмите кнопку OK;
•после щелчка мыши по строке формул нажмите клавиши
Ctrl+Shift+Enter.
43
Результаты вычислений будут расположены в следующем порядке
(табл. 1.3.1):
Таблица 1.3.1
b1 |
b0 |
Sb1 |
Sb0 |
|
|
R2 |
S |
F |
ν2 |
|
|
RSS |
ESS |
|
|
Широкие возможности для проведения статистического анализа предоставляет надстройка Пакет анализа.
Порядок работы с надстройкой Пакет анализа:
•в меню Сервис выбирите команду Анализ данных (если она отсутствует, необходимо в меню Сервис выбрать команду Надстройки и затем надстройку Пакет анализа);
•выберите инструмент Регрессия в окне надстройки;
•заполните строчки окна функции: столбец значений результативной переменной; столбец значений факторной переменной.
Результаты расчетов будут выведены в виде трех таблиц под общим
названием Вывод итогов. Содержание таблиц для данных из примера 1.1.1 представлены на рис. 1.3.1.
ВОПРОСЫ ДЛЯ САМОПРОВЕРКИ
1.Что понимается под прогнозированием при эконометрическом моделировании?
2.Какие виды прогноза Вы знаете?
3.Запишите формулу для вычисления несмещенной оценки дисперсии зависимой переменной.
4.От каких факторов зависит ширина интервала прогноза?

44
n |
x |
y |
xy |
|
|
|
|
|
1 |
0,8 |
5,6 |
4,48 |
0,64 |
31,36 |
8,40453 |
7,8654 |
127,69 |
2 |
1 |
6,6 |
6,6 |
1 |
43,56 |
8,96161 |
5,5772 |
106,09 |
3 |
1,7 |
12 |
20,4 |
2,89 |
144 |
10,9114 |
1,1851 |
24,01 |
4 |
2,6 |
15 |
39 |
6,76 |
225 |
13,4183 |
2,5019 |
3,61 |
5 |
4,1 |
21 |
86,1 |
16,81 |
441 |
17,5963 |
11,585 |
16,81 |
6 |
5,4 |
25 |
135 |
29,16 |
625 |
21,2174 |
14,308 |
65,61 |
7 |
7,2 |
24 |
172,8 |
51,84 |
576 |
26,2311 |
4,9778 |
50,41 |
8 |
8 |
26 |
208 |
64 |
676 |
28,4594 |
6,0487 |
82,81 |
сумма |
30,8 |
135,2 |
672,38 |
173,1 |
2761,9 |
|
54,049 |
477,04 |
cреднее |
3,85 |
16,9 |
84,0475 |
21,6375 |
345,24 |
|
|
|
ВЫВОД ИТОГОВ |
|
|
|
|
|
|
||
|
|
|
|
|
|
2,785 |
6,176 |
|
Регрессионная |
|
|
|
|
0,406 |
1,891 |
|
|
статистика |
|
|
|
|
|
|
|
|
Множес |
0,942 |
|
|
|
|
0,887 |
3,001 |
S |
твенный |
|
|
|
|
|
|
|
|
R |
|
|
|
|
|
|
|
|
R- |
0,887 |
|
|
|
F |
46,956 |
6,000 |
|
квадрат |
|
|
|
|
|
|
|
|
Нормир |
0,868 |
|
|
|
RSS |
422,991 |
54,049 |
ESS |
ованный |
|
|
|
|
|
|
|
|
R- |
|
|
|
|
|
|
|
|
квадрат |
|
|
|
|
|
|
|
|
Стандар |
3,001 |
|
|
|
|
|
|
|
тная |
|
|
|
|
|
|
|
|
ошибка |
|
|
|
|
|
|
|
|
Наблюд |
8 |
|
|
|
|
|
|
|
ения |
|
|
|
|
|
|
|
|
Дисперсионный анализ |
|
|
|
|
|
|
||
|
df |
SS |
MS |
F |
Значимость F |
|
|
|
Регресс |
1 |
422,9908 |
422,9908 |
46,9562 |
0,0005 |
|
|
|
ия |
|
|
|
|
|
|
|
|
Остаток |
6 |
54,04918 |
9,008196 |
|
|
|
|
|
Итого |
7 |
477,04 |
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
Коэф |
Стандар |
t- |
P- |
Нижние Верхние Нижние Верхние |
|||
|
фицие |
тная |
статист Значени |
95% |
95% |
95,0% |
95,0% |
|
|
нты |
ошибка |
ика |
е |
1,550 |
|
|
|
Y- |
6,176 |
1,891 |
3,266 |
0,017 |
10,803 |
1,550 |
10,803 |
|
пересеч |
|
|
|
|
|
|
|
|
ение |
|
|
|
|
|
|
|
|
x |
2,785 |
0,406 |
6,852 |
0,000 |
1,791 |
3,780 |
1,791 |
3,780 |
Рис. 1.3.1