

1.9. Полиномиальные модели экспоненциально взвешенных средних
В этом направлении разработан целый комплекс моделей. Кратко рассмотрим несколько из них. Здесь предполагается, что анализируемые ряды нестационарны и имеют линейный или квадратичный тренды.
Хольта линейное экспоненциальное сглаживание предполагает, что среднее прогнозируемого показателя yt изменяется линейно по времени:
yt = μt + λt t + εt,
где μt – среднее процесса, λt – его скорость (меняются во времени), а εt – случайная ошибка. При этом оценка λt осуществляется по показателю роста bt, который вычисляется как экспоненциально взвешенное среднее разности между текущими экспоненциально взвешенными средними значениями элементов временного ряда ut и их предыдущими значениями ut-1 и предыдущим значением bt-1. В свою очередь, текущее значение экспоненциально взвешенного среднего ut включает в себя значение прошлого показателя роста bt-1, адаптируясь таким образом к предыдущему значению линейного тренда.
Уравнения метода Хольта:
ut = αyt +(1-α)(ut-1 + bt-1) и bt = β(ut - ut-1) + (1 – β)bt-1,
где α и β – параметры сглаживания.
Если τ – горизонт прогнозирования, то прогноз на τ моментов времени по модели Холта вычисляется по формуле
ft+τ = ut + bt τ.
Здесь ut – оценка среднего текущего значения, bt – ожидаемый показатель изменения.
Значения α и β подбираются по минимальной ошибке прогноза. Параметр α предназначен для сглаживания оценки постоянного уровня элементов временного ряда, β – для оценки тренда.
Брауна линейное экспоненциальное сглаживание предполагает, что прогноз на τ моментов времени вычисляется по формуле
ft+τ = ut + bt τ,
где ut = ut-1+ bt-1+ (1– γ)2et, et = yt– ft и bt = bt-1+ (1– γ)2et.
Брауна квадратичное экспоненциальное сглаживание предполагает, что прогноз на τ моментов времени вычисляется по формуле
ft+τ = а0 + а1 τ + а2 τ2,
причём параметры а0, а1 и а2 выбираются так, чтобы на любой момент времени i взвешенная сумма квадратов отклонений между наблюдаемыми и ожидаемыми значениями обращалась в минимум:
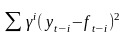 =
min.
=
min.
Параметр γ в методе Брауна аналогичен параметру (1-α) в методе Хольта (показатель дисконтирования наблюдений) и задаётся из априорных соображений, в том числе и из условия минимизации указанной суммы.
Модель Винтера с сезонной компонентой. Эта модель, как и модели Хольта и Брауна, основывается на экспоненциально взвешенных средних. Оценке здесь подлежат отдельно каждая из составляющих ряда: стационарная, трендовая (в виде линейного тренда) и сезонная. Для каждой такой оценки вводятся свои параметры сглаживания: α, β и γ. При компьютерных расчётах они определяются в автоматическом режиме по минимальной ошибке прогноза. При этом прогноз на τ периодов времени строится по линейному тренду с учётом сезонности St+τ:
ft+τ = (ut + btτ) St-s+τ.
При этом оценки ut и bt оцениваются аналогично, как и в модели Хольта (с учётом сезонности):
ut = α(yt/St) +(1-α)(ut-1 + bt-1) и bt = β(ut - ut-1) + (1 – β)bt-1,
а для оценки сезонной составляющей используется
St = γ(yt/ut) + (1- γ)St-s+ τ.
Здесь s – длина сезонности.
Двойное экспоненциальное сглаживание предполагает экспоненциаль-
но сгладить простую экспоненциально сглаженную:
![]() ,
,
![]() ,
,
где
![]() – простая экспоненциально сглаженная;
– простая экспоненциально сглаженная;
![]() –
двойная
экспоненциально сглаженная.
–
двойная
экспоненциально сглаженная.
Прогноз по этой модели осуществляется по соотношению
![]() ,
,
т.е.
по линейному тренду с константой, равной
![]() и наклоном
и наклоном
![]() .
.
В заключение отметим, что здесь были приведены только простейшие адаптивные методы моделирования нестационарных временных рядов, на основе которых можно анализировать и прогнозировать тенденции уровней временных рядов (в том числе и с учётом сезонности).
При выборе той или иной модели при работе с конкретным временным рядом можно пользоваться различными критериями. Один из них – минимальная ошибка прогноза.
В программе Statgraphics имеется процедура, позволяющая выбрать среди нескольких моделей лучшую по одной из таких ошибок. На рисунке 1.19 приведён пример использования такой процедуры.
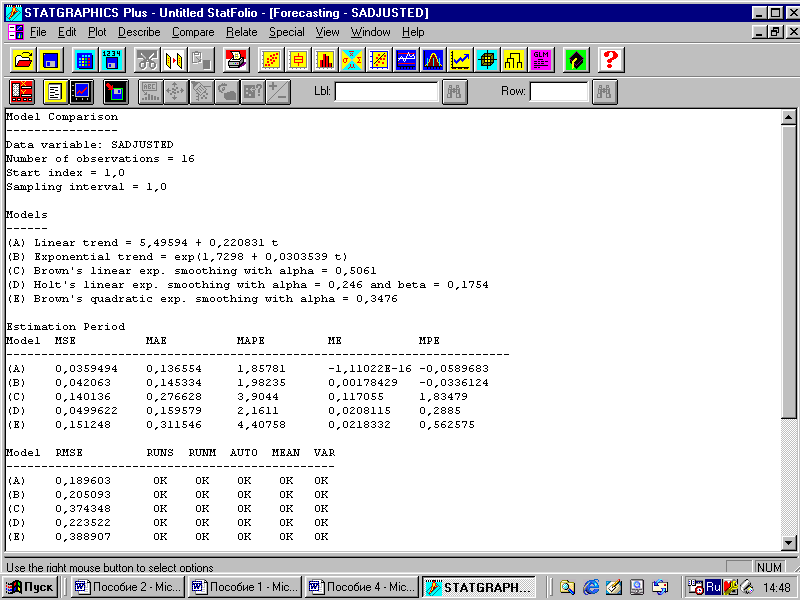
Рисунок 1.19 – Отчёт о расчёте моделей с использованием ошибок прогноза
Как видно из этого рисунка, имеется пять моделей, и если среди них надо выбрать лучшую, ориентируясь на ошибку, то можно предпочесть модель (А) – линейный тренд, хотя у модели (В) средняя процентная ошибка (МРЕ) меньше.
В EViews результат расчёта по модели Хольта приведены на рисунке 1.20. Здесь исходная информация несколько отличается от предыдущего примера. Так, наравне с вычисленными значениями коэффициентов α и β приведены прогнозные значения ut и bt.
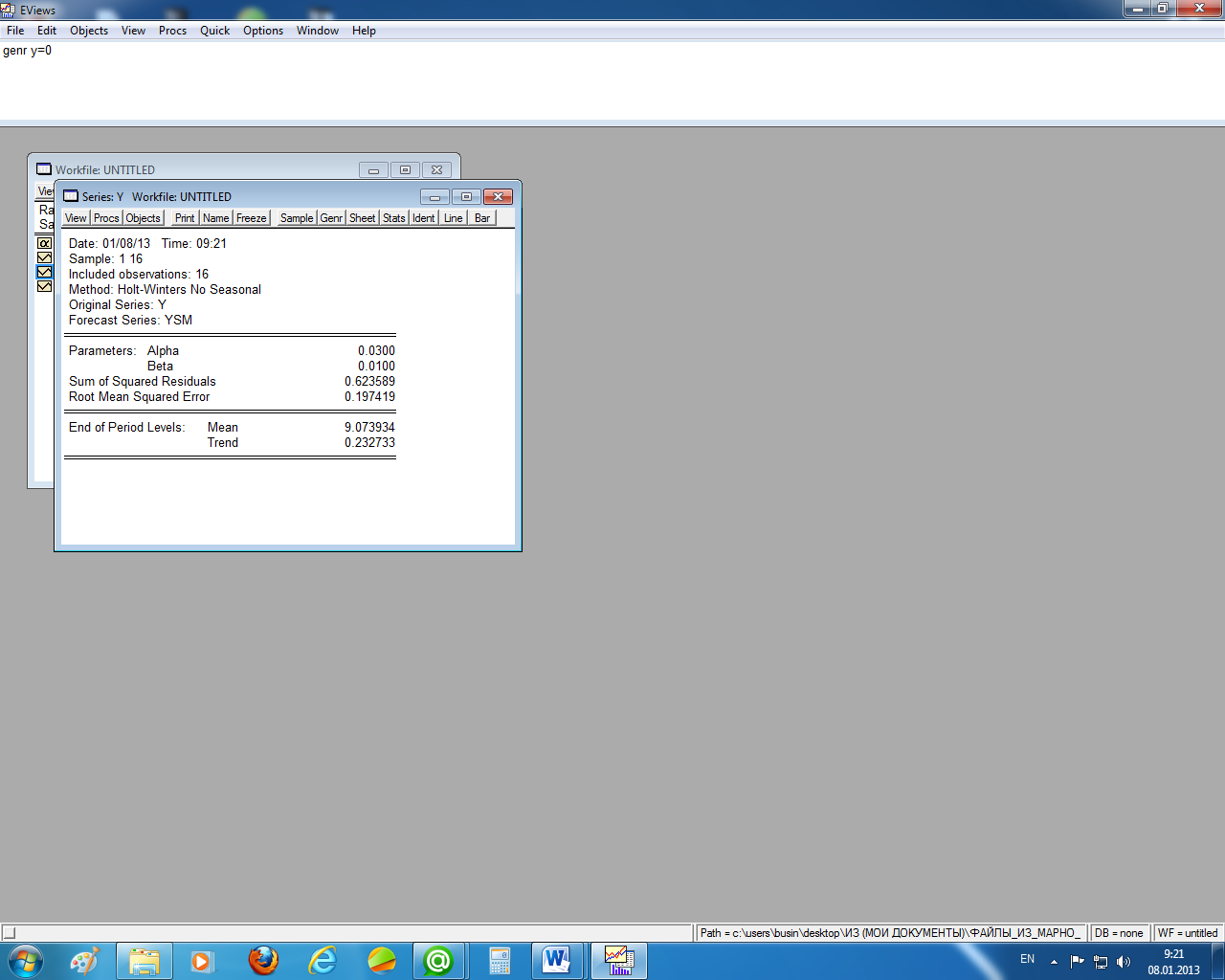
Рисунок 1.20 – Окно отчёта для модели Хольта из EViews