

Методическое пособие 701
.pdfТаблица 2.6
Значения усредненного времени реализации запросов
Количество записей в ХД:10000
Значения среднего времени выполнения запросов: ms
Поля не проиндексированы
1НФ
Цена от- |
Нормальная |
Цены |
Нормальная |
Прогнозная |
Нормальный про- |
крытия |
цена откры- |
закрытия |
цена закры- |
цена |
гноз |
|
тия |
|
тия |
|
|
700 |
790 |
775 |
770 |
680 |
700 |
|
|
|
3НФ |
|
|
Цена от- |
Нормальная |
Цены |
Нормальная |
Прогнозная |
Нормальный про- |
крытия |
цена откры- |
закрытия |
цена закры- |
цена |
гноз |
|
тия |
|
тия |
|
|
400 |
380 |
390 |
370 |
410 |
415 |
|
|
Все поля проиндексированы |
|
||
|
|
|
1НФ |
|
|
Цена от- |
Нормальная |
Цены |
Нормальная |
Прогнозная |
Нормальный про- |
крытия |
цена откры- |
закрытия |
цена закры- |
цена |
гноз |
|
тия |
|
тия |
|
|
518 |
500 |
490 |
530 |
515 |
530 |
|
|
|
3НФ |
|
|
Цена от- |
Нормальная |
Цены |
Нормальная |
Прогнозная |
Нормальный про- |
крытия |
цена откры- |
закрытия |
цена закры- |
цена |
гноз |
|
тия |
|
тия |
|
|
180 |
150 |
160 |
130 |
160 |
150 |
Анализ проведенных экспериментов показал, что среднее время обработки многоаспектных запросов меньше среднего времени обработки одноаспектных запросов. Следовательно, в СУБД MS Access целесообразнее осуществлять многоаспектный поиск.
Загрузочная секция (ЗС) является буфером, предназначенным для временного хранения данных перед их загрузкой в ХД. В технологическом плане она представляет собой набор временных промежуточных таблиц, в которых находятся данные в необработанном формате. В интересах оперативной пересылки данных для их хранения использован внутренний формат системы. Данные, содержащиеся в ЗС, становятся доступными для пользователя, после их пересылки в ХД. Информация в ЗС поступает из различных источников (локальная машина, ЛВС, интернет-сайты, унаследованные системы, файлы, архивы).
Для сопряжения БД унаследованных систем «DB2» с текущей СУБД «Access 2007» использовалась специальная служба словаря информационных ресурсов (Information Resource Dictionary System — IRDS). Она обеспечивала стандартизацию интерфейсов словарей данных двух СУБД для достижения большей доступности и упрощения их совместного функционирования. Данная служба входит в один из стандартов Международной организации стандартиза-
ции (International Organization for Standardization — ISO) [48]. Она включает оп-
ределение таблиц, содержащих словарь данных, и операций, которые могут
71
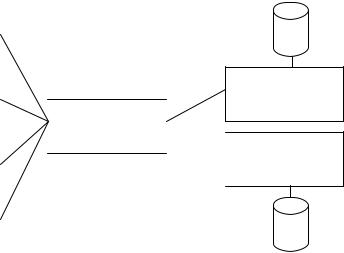
быть использованы для доступа к этим таблицам. Данные операции обеспечивают непротиворечивый метод доступа к словарю данных и способ преобразования определений данных из словаря одного типа в определения другого типа.
Всхематичном видереализацияданногоподходапредставленанарис.2.11.
Словарь
данных
Графический |
|
|
интерфейс |
|
|
|
|
|
|
|
|
Интерфейс |
|
|
командного |
|
|
языка |
|
Интерфейс |
|
|
cлужб |
|
||
Интерфейс |
|
IRDS |
экспорта/ |
|
|
импорта |
|
|
|
|
|
Пользова- |
|
|
тельские |
|
|
приложения |
|
|
БД «DB2»

 БД «Access»
БД «Access»
Словарь
данных
Рис. 2.11. Структурная схема обеспечения сопряжения различных типов БД службой IRDS
С помощью службы IRDS информация, хранимая в IRDS– совместимом словаре данных СУБД «DB2», передавалась в IRDS-совместимый словарь данных СУБД «Access 2007» или направлялась приложению системы DB2. Кроме того, данная служба обеспечила возможность расширения словаря данных. Если у пользователя возникала задача сохранения определения нового типа информации в каком-то инструменте (например, инициализации новыхотчетов в новой СУБД), то система IRDS в данной СУБД обеспечивала соответствующее расширение для включения этой информации. Служба IRDS построена на основе интерфейса служб, состоящего из набора функций, доступного для вызова с целью получения доступаксловарюданных. Интерфейсслужбможетвызыватьсясосторонытаких типовпользовательскихинтерфейсов,как
-графическийинтерфейс;
-командныйязык;
-файлыэкспорта/импорта;
-прикладныепрограммы.
В демонстрационном варианте ПК НПВР используется СУБД Microsoft Access 2007 в совокупности с языком запросов QBE (Query-by-Example — языкзапросов по образцу). В языке QBE используется визуальный подход для организации доступа к информации в базе данных, основанный на применении шаблонов запросов [57]. Применение QBE осуществляется путем задания образцов значений
72
вшаблонезапроса, предусматривающемтакойтипдоступакбазеданных, который требуется в данный момент, например получение ответа на некоторый вопрос. Средстваподдержкиязыка QBE вСУБД Microsoft Access простывэксплуатациии втожевремяимеютдостаточноширокийспектрвозможностейработысданными. В ПК НПВР средства языка QBE используются для ввода запросов к информации, сохраняемой в одной или нескольких таблицах, а также для определения набора полей,которыедолжныприсутствоватьврезультирующейтаблице.
Учет особенностей технологии хранения данных позволил при выборе инструмента использования ХД отдать предпочтение витрине данных. Витрина данных (ВД) обеспечивает работу с актуальными данными. Она представляет собой интегрированный, статичный, поддерживающий хронологию набор данных из разных источников, используемый для поддержки принятия инвестиционных решений. ВД базируется на нормализованной реляционной модели хранения данных. В состав ПВХД входит несколько витрин данных (поддержки НМШ, исследования ИНС, терминологического поиска,OLAP приложений). Тематические ВД (поддержки НМШ, исследования ИНС, терминологического поиска) реализованы в настоящей версии ПК НПВР. Применение нескольких ВД обусловлено необходимостью поддержки различных форматов данных в соответствующих приложениях. ВД оптимизированы под специфические требования соответствующих приложений. ВД OLAP (on-line analytical processing - оперативной аналитической обработки) приложений являются перспективными и в данной версии ПК НПВР не используются.
Модуль накопления и очистки данных обеспечивает проверку данных, поступающих в хранилище из различных источников. Необходимость этих действий обусловлена причиной существования данных с ошибками («замусоренных» данных), возникающих в результате ввода данных операторами ПК, различных форматов используемыхсловарейиотсутствиемсистемыконтролявводимыхданных.
Модуль контроля качества данных предназначен для сохранения консистентности, целостности и непротиворечивости последних, а также устранения их избыточности.
Модуль оптимизации ВД и доступа к данным предназначен для повышения оперативности реализации запросов пользователя и размещения актуальных данных на ВД.С целью повышения оперативности реализации запросов пользователя был пересмотрен стандартный метод индексирования записей в БД и разработан модифицированный алгоритм обобщенного индексного дерева. Индексирование данных призвано ускорить все операции, связанные с поиском соответствующей информации [179]. В процессе реализации индексирования выявилось некоторое противоречие, суть которого заключалась в следующем. Если поиск удаляемых (корректируемых) записей осуществлялся по условиям, наложенным на индексированный столбец, то имело место ускорение данного процесса. Однако в случае добавления записи происходило, наоборот, его замедление, поскольку происходи-
73
ло выполнение нескольких операций - добавления информации в файл данных и модификации индексов. Поэтому увеличение индексов в таблице привело к замедлению процесса модификации. Для разрешения данного противоречия была использована идея применения при индексировании Р*-дерева. В основном Р*- деревья используются при индексировании пространственных объектов. Исследовались классический метод индексирования пространственных объектов и алгоритм обобщенного индексного дерева [40]. Кроме того, был разработан модифицированный алгоритм обобщенного индексного дерева. Его суть заключалась в дополнении основной функции «деления узла» поиском непересекающихся множеств и процедурой деления узла без пересечений. Для просмотра всех записей, находящихся в узле, строились списки разбиения ребер охватывающего прямоугольника без пересечений. После чего в главном цикле функции «деления узла» проводился анализ возможных разбиений, что обеспечило алгоритмическую сходимость метода. В случае нескольких вариантов разбиения узла без пересечений выбирался тот, при котором площадь охватывающих прямоугольников была минимальной. Если деление без пересечений было невозможным, выполнялся уже существующий алгоритм. В итоге к существующему алгоритму индексирования Р*-дерева был добавлен ряд дополнительных процедур, часть которых реализованасиспользованием стандартнойбиблиотекиDelphi7.0.
Врезультате проведенных экспериментов установлено [78], что по временным параметрам реализация классических Р-деревьев уступает реализациям обобщенных Р-деревьев достаточно весомо (более 26 %). Поэтому в дальнейшем сравнивались метод обобщенного индексного дерева и модифицированный алгоритм обобщенного индексного дерева. В ходе проведенных экспериментов были получены зависимости производительности индексных структур этих типов от их внутреннейархитектуры.
Были созданы три группы типов объектов: малые, большие и объекты случайных размеров. Для каждой из групп были сформированы случайным образом множества, состоящие из 5, 10, 100, 1000, 10000, 1000000 объектов соответственно.Всегоисследовалось50пакетовэкспериментальныхданных.
Входе проведения каждого эксперимента выполнялась следующая последовательностьдействий:
-добавление вБД единичногомножестваобъектов; -заданиеколичествазапросов,связанныхспересечениемнекоторыхзаписей; -реализация сформированныхзапросов;
- хронометраж времени реализации всех запросов и определение среднего времениреализации запроса; -формированиевыходныхрезультатов.
Втабл. 2.7 представлены значения длительностей (в ms) реализаций запросов,дляразличныхметодовформированияипротяженностейобъектов.
74
Таблица 2.7 Экспериментальные значения длительностей (ms) реализаций запросов для различных алгоритмов их формирования и протяженности объектов
Количество |
Алгоритм обобщен- |
Модифицированный |
Временной |
записей в таблице |
ного индексного |
алгоритм обобщен- |
выигрыш, % |
|
дерева |
ного индексного |
|
|
|
дерева |
|
5 |
4,34 |
4,12 |
5,3 |
10 |
35,16 |
33,08 |
6,3 |
100 |
201,53 |
175,2 |
15 |
1000 |
408,51 |
317,14 |
28,8 |
10000 |
3152,33 |
2178,21 |
44,7 |
1000000 |
8677,12 |
5405,59 |
60,5 |
Анализ полученных результатов показывает, что модифицированный алгоритм обобщенного индексного дерева превосходит по быстродействию существующий в среднем более чем на 25%. В случае увеличения количества записей в таблице, производительность предложенного алгоритма возрастает в среднем более чем на 50%, что актуально для БД данной предметной области.
Это позволяет сделать вывод о перспективности его использования.
Вмодуле оптимизации ВД и доступа к данным реализован алгоритм взаимообмена данными между ВД и ХД, названный алгоритмом оптимизации доступа, которыйобеспечивает:
- эффективный обмен данными между ХД и ВД; - быстрый доступ к актуальным данным;
- долговременное гарантированное хранение наборов данных включенных вХД.
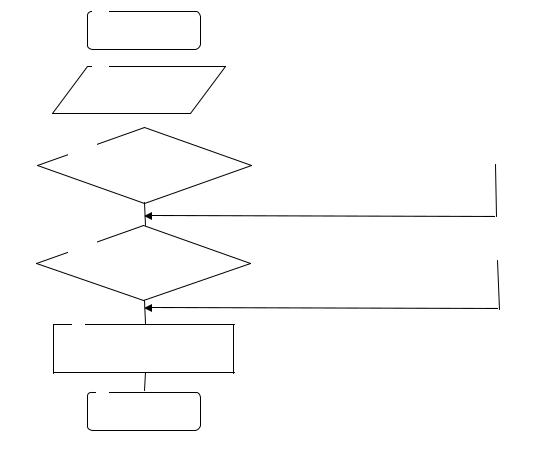
Блок-схема алгоритмаоптимизации доступа, представлена на рис. 2.12. Блоки 1,8 используются для пуска и остановки процесса обмена данными.
Вблоке 2 реализован ввод исходных данных, таких как значение верхнего уровня объема данных ВД и значение нижнего уровня объема данных ВД. Запуск и остановка процедуры перемещения данных реализуется в соответствии со следующими критериями:
- система перемещения данных из ВД в ХД запускается, если общий объем хранимых в ВД данных превышает верхний допустимый уровень;
- система перемещения данных из ВД в ХД прекращает работу, когда общий объем хранимых в ВД данных становится меньшим, чем нижний допустимый уровень.
Блок 3 используется для проверки состояния загруженности ВД. Если ВД не загружено, то осуществляется переход к блоку 5. В противном случае управление переходит к блоку 4.
Блок 4 реализует архивацию и перемещение данных из ВД в ХД.
Вблоке 5 реализован поиск данных, запрашиваемых пользователем. Если
75
1 |
|
|
|
|
|
|
Начало |
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
Ввод исход- |
|
|
|
|
|
|
ных данных |
|
|
|
|
|
|
3 |
|
Да |
|
4 |
|
|
|
|
|
|
|||
|
|
|
|
|||
|
|
|
||||
Заполнена ли |
|
Архивация иперемеще- |
|
|||
|
|
ние данных из ВД в ХД |
|
|||
ВД? |
|
|
|
|||
|
|
|
||||
|
|
|
|
|
||
Нет |
|
|
|
|
|
|
|
|
|
|
|
||
5 |
|
|
|
6 |
|
|
|
Нет |
|
Перемещение и распа- |
|
||
Удовлетворен |
|
|
||||
|
ковка запрашиваемых |
|
||||
ли запрос? |
|
|
|
|||
|
|
|
||||
|
|
|
данных из ХД в ВД |
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Да
7
Сохранение оператив-
ных данных
8
Конец
Рис. 2.12. Блок-схема алгоритма оптимизации доступа
онисодержатсявХД,тоосуществляетсяихнепосредственнаязагрузкаидальнейшая работасними.ВслучаеихразмещениявХДуправлениепередаетсяблоку6.
Блок 6 используется для поиска запрашиваемых данных в ХД. В случае их наличия последние перемещаются из ХД в ВД, распаковываются (разархивируются) и предоставляются пользователю для дальнейшей работы.
Блок 7 реализует запись полученных оперативных данных вВД. Большое значение при архивации данных имеет определение последова-
тельности их переноса. В ХД переносятся не все данные - об этом свидетельствует наличие нижнего допустимого уровня хранения данных в ВД. Перемещение производится в соответствии с рангом популярности данных: очередь на перенос формируется в очередности, обратной популярности данных, которую имеют данные с минимальным рангом. В качестве меры популярности использовалась эмпирическая оценка вероятности поступления запроса: чем выше вероятность поступления запроса, тем выше ранг данных.
Для оценки вероятности поступления запроса использовано предположение о том, что запросы формируют поток событий, подчиняющийся статистике простого пуассоновского потока [1]. В рамках данного предположения интенсивность потока (количества событий в единицу времени) запросов на i-й набор данных определяется в соответствии со следующей эмпирической оценкой:
76
|
i |
Ni |
|
|
|
|
|
|
|
, |
(2.26) |
|
ti |
ti |
|||
где Ni |
|
N |
O |
|
|
- полное количество запросов на i-й набор данных, tOi |
– время по- |
||||
ступления данных в архив, tNi – время поступления Ni -го запроса. Вероятность
поступления запроса на i-й набор данных при интенсивности потока заказов i в момент времени t tNi определяется выражением (вероятность единичного
события на интервале t tNi |
0 |
) [1] |
. |
(2.27) |
|
pi |
1 exp i t tNi |
Полученныеоценкиопределяютрангнабораданных.Длямножестваиз Kнаборовданныхранжированиесводитсяксортировкеданныхвсоответствиисправилом:
pi pj , при i<j для любых i 1,K; j 1,K . (2.28)
В результате данной сортировки наборов данных набор с индексом i является искомым, который необходимо перенести в ХД. В этом случае минимизируются расчетные затраты на повторное извлечение данных из ХД. При реализации данного алгоритма сортировка проводится при потенциально большом количестве кандидатов на перенос. В случае, когда количество переносимых файлов (наборов данных) невелико, реализуется простой последовательный перенос файлов, имеющих минимальные вероятности поступления заказа.
Предложенныйподходреализованввиденаборапроцедур,обеспечивающих:
1)контроль ресурсовВД;
2)расчет ранга популярности данных;
3)автоматический перенос данных, инициируемых процедурами контроля состоянияВД.
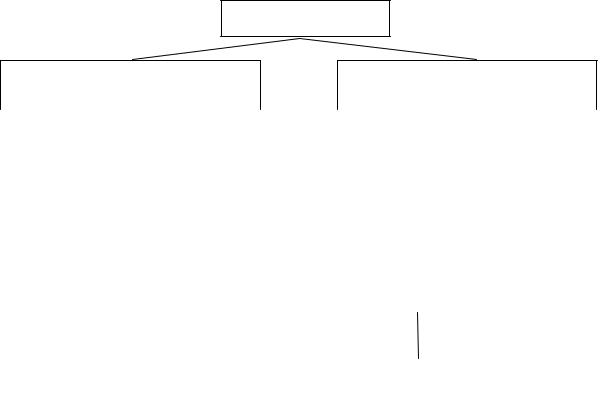
Модуль архивации данных используется в интересах архивации и распаковки данных, соответственно при их передаче и приеме в ХД. Обобщенная схема классификация методов сжатия информации приведена на рис. 2.13.
Подробное обоснование методов архивации данных приведено в [154]. Анализ эффективности архиваторов, базирующихся на методах сжатия
данных, представленных на рис. 2.13 и используемых на практике, показал следующее. Оценивались следующие архиваторы [24]:
-7-Zip, автор Игорь Павлов (Pavlov);
-АСЕ, автор Маркел Лемке (Weinke);
-ARJ, автор Роберт Джанг (Jung);
-ARJZ, автор Булат Зиганшин (Ziganshin);
-CABARC, корпорация Microsoft;
-Imp, фирма Technelysium Pty Ltd.;
-JAR, автор Роберт Джанг (Jung);
-PKZIP, фирма PKWARE Inc.;
-RAR, автор Евгений Рошал (Roshal);
-WinZip, фирма Nico Mak Computing;
-1Zip, Info-ZIP group.
77
Методы сжатия
данных
Универсальные методы
(без потерь информации)
Специальные методы
(с потерями информации)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Посимвольное |
|
|
|
Кодирование |
|
|
|
|
Для графики |
|
|||||
|
|
кодирование |
|
|
|
цепочек |
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Статистиче- |
|
|
|
Кодирование |
|
|
|
|
«Блочное» |
|
||||
|
|
скоекодиро- |
|
|
|
однородных |
|
|
|
|
сжатие |
|
||||
|
|
вание |
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
(по Хаффма- |
|
|
|
повторов |
|
|
|
|
(JPEG) |
|
||||
|
|
ну) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Кодирование |
|
|
|
|
«Волновое» |
|
|||
|
|
|
|
|
|
|
разнородных |
|
|
|
|
сжатие |
|
|||
|
|
|
|
|
|
|
повторов |
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
(по Лемпелю- |
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
Фрактальное |
|
||||
|
|
|
|
|
|
|
|
Зиву) |
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
сжатие |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
Рис. 2.13. Классификация методов сжатия данных |
|
|||||||||||
Данные архиваторы являются или одними из самых эффективных в классе, применяющих методы Зива-Лемпела, или пользуются популярностью, или оказали существенное влияние на развитие словарных алгоритмов, или интересны с точки зрения нескольких указанных критериев.
В табл. 2.8 представлены результаты сравнения ряда архиваторов по степени сжатия файлов, времени кодирования и декодирования на специальном наборе данных CalgCC [24].
Коэффициент сжатия оценивался с помощью набора файлов, получивше-
го название Calgary Compression Corpus2 (CalgCC). В состав CalgCC входят файлы различных типов данных. Набор состоит из 14 файлов, большая часть которых представляет собой тексты на английском языке или языках программирования [24].
При проведении исследований применялся тот алгоритм, который обеспечивал наилучшее сжатие. Следует отметить, что 7-Zip использует специальные методы препроцессинга нетекстовых данных, "отключить" которые не удалось, что до некоторой степени исказило картину. Тем не менее преимущество этого архиватора на данном тестовом наборе несомненно. В случае WinRAR и АСЕ режим мультимедийной компрессии намеренно не включался.
Полученные результаты показали, что скорость сжатия ARJ и PKZIP была примерно в 4,5 раза выше, чем у RAR и АСЕ, которые, в свою очередь, были
78
Таблица 2.8 Сравнительная характеристика архиваторов по степени сжатия файлов,
времени кодирования и декодирования специального набора
|
ARJ |
PKZIP |
ACE |
RAR |
CABARC |
7-Zip |
Bib |
3,08 |
3,16 |
3,38 |
3,39 |
3,45 |
3,62 |
Book1 |
2,41 |
2,46 |
2,78 |
2,80 |
2,91 |
2,94 |
Book2 |
2,90 |
2,95 |
3,36 |
3,39 |
3,51 |
3,59 |
Geo |
1,48 |
1,49 |
1,56 |
1,53 |
1,70 |
1,89 |
News |
2,56 |
2,61 |
3,00 |
3,00 |
3,07 |
3,16 |
Obj1 |
2,06 |
2,07 |
2,19 |
2,18 |
2,20 |
2,26 |
Obj2 |
3,01 |
3,04 |
3,39 |
3,38 |
3,54 |
3,96 |
Paper1 |
2,84 |
2,85 |
2,91 |
2,93 |
2,99 |
3,07 |
Paper2 |
2,74 |
2,77 |
2,86 |
2,88 |
2,95 |
3,01 |
Pic |
9,30 |
9,76 |
10,53 |
10,39 |
10,67 |
11,76 |
Progc |
2,93 |
2,94 |
3,00 |
3,01 |
3,04 |
3,15 |
Progl |
4,35 |
4,42 |
4,49 |
4,55 |
4,62 |
4,76 |
Progp |
4,32 |
4,37 |
4,55 |
4,57 |
4,62 |
4,73 |
Trans |
4,65 |
4,79 |
5,19 |
5,23 |
5,30 |
5,56 |
Итого |
3,47 |
3,55 |
3,80 |
3,80 |
3,90 |
4,10 |
Ткод |
2,60 |
1,68 |
2,73 |
2,55 |
3,77 |
1,0 |
Тдек |
2,5 |
1,90 |
2,80 |
2,97 |
3,98 |
1,0 |
быстрее CABARC и 7-Zip приблизительно на 30 %. Размер словаря в ARJ и PKZIP в десятки раз меньше, чем в остальных программах.
Для Ткод и Тдек за единицу принято время сжатия всего CalgCC архиватором 7-Zip. Следует отметить, что единица соответствует скорости кодирования 2 Гб/с для ПК с процессором типа Pentium IV 2,8 ГГц, объемe оперативной памяти 1 ГГц, частоте шины 800 МГц, объемe жесткого диска 160 ГГб.
Дальнейшая оценка возможностей архиваторов с целью выбора наиболее эффективного проводилась на выборке данных, непосредственно используемых в подсистеме поддержки нейромодифицированной одноиндексной модели Шарпа. В состав выборки были включены файлы с числовыми данными, а также файлы, содержащие растровые изображения используемых графиков, диаграмм и гистограмм. Всего в состав выборки было включено 18 файлов. Количество файлов было определено экспериментальным путем. При меньших значениях числа файлов имел место достаточно большой разброс значений коэффициента сжатия, а при больших значениях числа файлов наступало так называемое насыщение, при котором разброс значений коэффициента сжатия имел незначительные приращения.
Среди исследуемых архиваторов рассматривались PKZIP, RAR и 7-Zip. В настоящее время они находят наибольшее распространение и являются представителями определенных диапазонов значений коэффициентов сжатия дан-
79
ных (см. табл. 2.8).
В табл. 2.9 приведены результаты сравнения архиваторов по степени сжатия файлов на реальном наборе данных, состоящем из 18 файлов фиксированного размера 1639139 байт. Анализ полученных данных показывает, что они незначительно отличаются от данных, приведенных в табл. 2.8 (на десятые доличто повышает степень доверия к полученным результатам.
Таблица 2.9 Результаты сравнения архиваторов по степени сжатия файлов
на реальном наборе данных
|
PKZIP |
RAR |
7-Zip |
I1.txt |
2,94 |
3,15 |
3,55 |
I2.txt |
2,46 |
3,08 |
3,44 |
I3.txt |
2,22 |
2,93 |
3,18 |
I4.txt |
2,12 |
2,81 |
2,80 |
I5.txt |
2,08 |
2,66 |
3,40 |
R1.doc |
2,01 |
2,11 |
2,18 |
R2.doc |
2,00 |
2,05 |
2,16 |
R3.doc |
2,05 |
2,07 |
2,22 |
R4.doc |
2,00 |
2,01 |
2,15 |
R5.doc |
1,92 |
2,05 |
2,31 |
F1.bmp |
2,94 |
3,01 |
3,15 |
F2.bmp |
4,42 |
4,55 |
4,76 |
F3.bmp |
4,37 |
4,57 |
4,73 |
F4.bmp |
4,79 |
5,23 |
5,56 |
G1.jpeg |
4,01 |
4,25 |
4,75 |
G1.jpeg |
4,17 |
4,46 |
4,98 |
G1.jpeg |
4,23 |
4,29 |
5,17 |
G1.jpeg |
5,01 |
5,59 |
5,97 |
Итого |
3,09 |
3,38 |
3,69 |
Ткод |
1,60 |
1,12 |
2,55 |
Тдек |
1,8 |
1,25 |
2,68 |
Лучшие характеристики продемонстрировал архиватор 7-Zip. Ему незначительно уступает RAR.
В результате анализа временных характеристик при проведении экспериментов было установлено, что ценой увеличения степени сжатия является падение скорости в среднем в 2 и более раза.
По результатам проведенных экспериментов для архивации данных при пересылке последних из оперативного хранилища в долговременное хранилище был выбран алгоритм 7-Zip.
Модуль резервирования данных обеспечивает резервное копирование данных из ХД и ВД на внешние носители информации (жесткие магнитные
80