

Методическое пособие 701
.pdfинвестиционного портфеля.
Шаг 7. Построение границы эффективных портфелей и определение оптимального портфеля.
2.2.3. Программная реализацияопределения долей ценных бумаг, в оптимальном портфеле Шарпа
Реализация задачи определения долей ценных бумаг, входящих в оптимальный портфель Шарпа, представлена в виде программного модуля, влюченного в состав СППИР [153]. В качестве среды разработки модуля использована объектно–ориентированная среда разработки Delphi 7.0. Обоснование выбора данной среды представлено в [154].
Экранная форма расчета долей ценных бумаг, входящих в оптимальный портфельШарпа, приведена на рис. 2.7.
Рис. 2.7. Вид экранной формы расчета долей ценных бумаг, входящих в оптимальный портфель Шарпа
Верхняя часть экранной формы предназначена для ввода исходных данных для расчета. В левой верхней части экранной формы находится окно со списком ценных бумаг (облигаций), которые могут быть включены в состав портфеля. Рядом находится окно, в котором отображаются выбранные облигации. В средней части экранной формы находится окно «Доходность к погашению». В правой части формы размещены два окна, в которых задаются количество типов ЦБ (облигаций) и количество рассматриваемых временных интервалов соответственно. Они заполняются на начальном этапе работы с программным модулем. Затем осуществляется выбор конкретных ЦБ (облигаций). После выбора необходимой облигации пользователь нажимает правую кнопку мыши. Появляется кнопка «Добавить». Нажатием данной кнопки соответствующая ЦБ перемещается в окно «Выбранные облигации». Далее необходимо ввести требуемые периоды наблюдения за доходностями облигаций. Соответствую-
61
щие окна ввода размещены снизу окна «Выбранные облигации». Кнопки «Сброс» и «Принять», размещенные справа от этого окна, обеспечивают соответственно удаление или принятие списка выбранных ЦБ. Перечень выбранных (принятых) ЦБ и их доходность за выбранные периоды отобразится в окне «Доходность к погашению», размещенном в правой верхней части экранной формы. Значения доходности облигаций могут корректироваться и вводиться с клавиатуры.
В нижней части экранной формы отображаются результаты расчета. Они появляются после ввода исходных данных (заполнения верхней части экранной формы) и нажатия кнопки «Расчет». В состав результатов расчета включены доля капитала, вложенная в безрисковые облигации, риск портфеля и процентные соотношения выбранных ЦБ в виде соответствующих весов.
Кроме того, на данной экранной форме имеются кнопки «Справка» и «Выход». Нажатие кнопки «Выход» обеспечивает возврат на главную форму СППИР. При нажатии на кнопку «Справка» появляется соответствующая экранная форма, в которой отражаются основные сведения об используемой модели.
2.3.Нейромодифицированная одноиндексная модель Шарпа
Суть одного из существенных недостатков одноиндексной модели Шарпа заключается в том, что портфель ЦБ, рассчитываемый на основе данной модели, теряет свойства оптимальности в упреждающие моменты времени. В [36] это математически доказано. Потеря оптимальности обусловлена отсутствием в модели механизма учета прогноза. Парировать данный недостаток в [36] предложено экспертным путем [8]. В рамках нейромодифицированной одноиндексной модели Шарпа (НМШ) [121, 147] в качестве эквивалента экспертных прогнозных оценок предлагается использовать искусственные нейронные сети
(ИНС).
Математическое обоснование предлагаемой идеи состоит в следующем. В основу одноиндексной модели Шарпа положена регрессионная зависимость (2.22), устанавливающая взаимосвязь между доходностью ЦБ, включае-
мой в инвестиционный портфель, и доходностью рыночного индекса [3]:
ri(t) i irI (t) i (t), |
(2.22) |
где ri (t) – доходность i-й ЦБ в момент времени t; |
rI (t)– доходность ры- |
ночного индекса в момент времени t; i , i – оцениваемые параметры регрессионной модели; i (t)– случайная погрешность.
Параметр i , так называемый сдвиг (смещение), определяет составляю-
щую доходности ЦБ, не зависящую от динамики рынка. Фактически данный параметр является мерой недооценки или переоценки соответствующей ЦБ рынком. Положительное значение i указывает на переоценку рынком данной
ЦБ и наоборот. Он рассчитывается в соответствии с выражением
62
|
n |
yi |
β n xi |
|
|
|
α |
i 1 |
|
|
i 1 |
, |
(2.23) |
n |
|
n |
||||
|
|
|
|
|
||
где yi – доходность рынка в i-й период времени; xi – доходность ЦБ в i-й
период времени; n – количество периодов.
Параметр i представляет собой чувствительность данной ЦБ к изменению рынка. Если >1, то стоимость ЦБ изменятся быстрее, чем рыночный ин-
декс, и соответственно она является более рискованной, чем рынок в среднем. Если i <0, то движение ЦБ обратно движению рынка. Оценивается параметр i
путем сопоставления данных о соотношении доходности рассматриваемой ЦБ и доходности рынка (индекса) за определенный период времени. При этом используется метод наименьших квадратов.
Введем в выражение (2.22) дополнительное слагаемое pikti . Тогда выражение (2.22) примет вид
ri (t) i pikti irI (t) i (t) , |
(2.24) |
где p – параметр оценки средней величины скачкообразных изменений ЦБ, kti – дихотомическая переменная.
Дихотомическая переменная kti принимает значение +1 в случае превы-
шения фактической доходностью ЦБ трендового уровня, и значение -1 – в противном случае [121]. В символьном виде это записывается следующим образом:
1, |
ti 0 |
|
|
|
|
|
(2.25) |
|
, t 1,T |
,i 1,n . |
|||||||
kti |
|
|||||||
1, |
ti 0 |
|
|
|
|
|
|
|
Всоответствии с (2.25) доходность ЦБ зависит от доходности индекса и скачкообразных изменений, которые имеют место в динамике самой ЦБ. Эти скачкообразные изменения можно интерпретировать как «риск – эффекты», которые не имеют объяснения внутри рынка, но которые в каждый момент времени оказывают воздействие на уровень доходности ЦБ, изменяя ее то в одну, то в другую сторону. Средняя величина этих изменений на историческом периоде равна величине оцененного параметра p [36].
Винтересах прогнозирования значений «риск – эффектов» предлагается использовать ИНС, которые способны запоминать значения p для аналогичных условий, имевших место в прошлые периоды времени. По своей сути знания экспертов, на основе которых они оценивают текущую ситуацию, аналогичны. Только в данной модели в роли эксперта выступает ИНС [132, 141].
Вкачестве ИНС целесообразно использовать многослойный персептрон в совокупности с модифицированным обучающим алгоритмом обратного распространения ошибок. При прочих равных условиях данная ИНС обеспечивает
63
приемлемую точность и достаточно высокую оперативность обучения. Технология применения НМШ заключается в следующем.
Впроцессе электронных торгов на бирже в различные моменты времени множество ИНС обучается, тестируется и ее параметры заносятся в соответствующую базу данных с целью последующего воспроизведения. Проведение этих действий особенно актуально в период протекания аномальных ситуаций. При наличии достаточно полной базы ИНС параметры текущей ситуации на рынке сравниваются с имеющимися, и для подобных условий из базы извлекается и инициализируется соответствующая ИНС или их множество. Полученные на ее (их) основе прогнозные значения используются при проведении текущей оценки соответствующей ЦБ.
Вслучае если ИНС при работе на тестовом множестве и с реальными данными несколько раз подряд (более трех) формирует ошибочные результаты, предусмотрено ее отключение, что эквивалентно функционированию обычной одноиндексной модели Шарпа. Последнее важно для практики, поскольку исключает накопление ошибок.
Симбиоз ИНС, реализующей определение и оценку отклонений доходности ЦБ на упреждающем отрезке времени, и НМШ, призван повысить точность последней. Если ИНС настроена и работает корректно, то точность модели повышается, в противном случае возможно достижение такого состояния, когда точность получаемых результатов будет соответствовать одноиндексной модели Шарпа без каких-либо модификаций (НМШ не должна работать хуже одноиндексной модели Шарпа).
Винтересах поддержки НМШ разработан специальный программный комплекс нейросетевого прогнозирования временных рядов (ПК НПВР).
2.4.Характеристика программного комплекса
нейросетевого прогнозирования временных рядов
Основное целевое назначение ПК НПВР – обеспечить формирование и обучение ИНС в интересах прогнозирования значений «риск – эффектов» для НМШ. Достижение данной достаточно узкой цели оказалось невозможным без решения более широкой задачи – исследования ИНС. Процесс исследования ИНС заключается в поиске их оптимальных структур и рациональных обучающих методов и алгоритмов. Разработанный комплекс обеспечивает реализацию данного процесса.
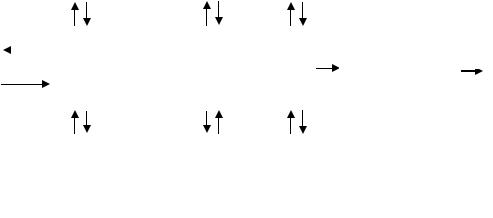
Структурно-функциональная схема ПК НПВРприведена на рис. 2.8. Для решения узкой и широкой задач целевого назначения ПК НПВР, в
его состав включены подсистемы ввода и хранения данных (обеспечивает поддержку НМШ) и исследования ИНС, соответственно. Выбор решаемой задачи и настройку ПК НПВР для ее решения обеспечивает подсистема управления.
64
|
|
|
Модуль |
|
Модуль |
|
|
Модуль |
|
|
|
|
|
|
|
«Алгоритм |
|
«Алгоритм |
|
|
|||
|
|
«Многослойный |
|
обратного |
|
имитации |
|
|
|||
|
|
персептрон» |
|
распространения |
|
отжига» |
|
|
|||
|
|
|
|
|
ошибки» |
|
|
|
|
|
|
Подсистема |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
Модуль |
Вых. |
|||
ввода |
|
|
|
|
Модули |
|
|
«Формирование |
|||
|
|
|
|
|
|
рез. |
|||||
и |
|
|
управления и визуализации |
|
|
отчетов» |
|
||||
хранения |
|
|
|
|
|
|
|
|
|
||
данных |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Модуль |
|
Модуль |
|
|
Модуль |
|
|
|
|
|
|
|
«Адаптация |
|
«Эвристическая |
|
|
|||
|
|
«Генетический |
|
архитектуры |
|
оптимизация» |
|
|
|||
|
|
алгоритм» |
|
нейронной |
|
|
|
|
|
|
|
|
|
|
|
|
сети» |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 2.8. Структурно-функциональная схема ПК НПВР
2.4.1.Специальноематематическоеипрограммноеобеспечение подсистемывводаихраненияданных
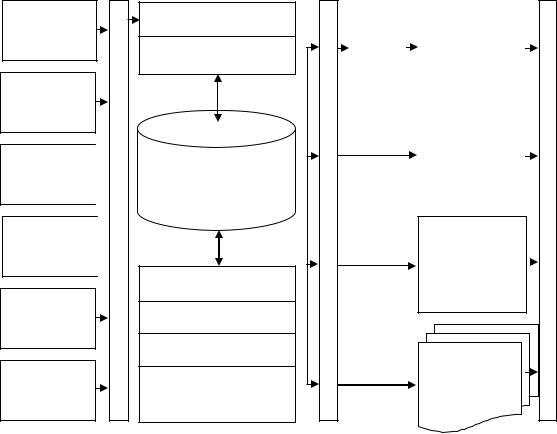
Структурно-функциональная схема подсистемы ввода и храненияданных(ПВХД) приведенанарис.2.9.ВсоставПВХДвходитхранилищеданных,загрузочнаясекция,набор витрин данных (поддержки НМШ, исследования ИНС, терминологическогопоиска, OLAPприложений)ипрограммныхмодулей(эвристическойоптимизацииХД,вводаданных,накопленияиочисткиданных,контролякачестваданных,оптимизацииОБДидоступакданным,архивацииданных,резервированияданных,формированияотчетов).
Хранилище данных (ХД), разработанное в рамках ПК НПВР, предназначено для долговременногохраненияданных.Оносоответствуетегоклассическомупониманию[88] ипредставляетсобойспециальнымобразомадминистрируемуюбазуданных,содержимое которойимеетследующиесвойства:
-предметная ориентация (данные, содержащиеся в ХД, ориентированы на задачи поддержкипринятиярешений,аненаиспользуемыеприложения);
-интегрированностьданных(очисткаданныхотиндивидуальныхпризнаковиприведениеихединомуформату);
-инвариантностьво времени (сохранение данными своей истинности влюбой моментпроводимыхснимиманипуляций);
-неразрушаемость - cтабильность информации (однажды загруженные данные практическиникогданеменяются).
РазработкаХДосуществляласьпоэтапно[23,47,63,73].
НаначальномэтапепроводилиськонцептуальноеилогическоепроектированиеХД, независящиеотдеталейеговоплощения(отиспользуемойСУБД).Восновуконцептуальногопроектированиябылаположена объектно-реляционнаямодельданных[63].Приэтом использовалсястандартIDEF0[70].
65
Документы
локальной
машины
Документы
ЛВС
Интернетсайты
Унаследован-
ные
системы
Файлы
Архивы

 Загрузочная секция
Загрузочная секция
Модуль накопления и
очистки данных
Модуль контроля качества данных
Хранилище
данных
Модульэвристической
оптимизацииХД
МодульоптимизацииВД идоступакданным 
Модуль архивации данных
Модуль
резервирования
данных
Модули ввода исходных данных
автоматизиМодульзагрузкированной |
данных |
|
Витрина |
|
данных |
||
|
|
|
поддержки |
|
|
|
НМШ |
|
|
|
|
|
|
|
|
|
|
|
Витрина |
|
|
|
данных |
|
|
|
для |
|
|
|
исследованиия |
|
|
|
ИНС |
|
|
|
|
Витрина
данных терминологиче-
ского
поиска
Витрины
данных
OLAP
приложений
Модули формирования выходных результатов
Рис. 2.9. Структурно-функциональная схема подсистемы ввода и хранения данных
В IDEF0 система представляется как совокупность взаимодействующих работ или функций. Функции системы анализируются независимо от объектов, которыми они оперируют. Это позволяет более четко смоделировать логику и взаимодействие процессов ПК НПВР [71, 72]. Основу методологии IDEF0 составляет графический язык описания бизнес-процессов. Модель в интерпретации IDEF0 представляет собой совокупность иерархически упорядоченных и взаимосвязанных диаграмм [23]. Каждая диаграмма является единицей описания системы и располагается на отдельном листе. При разработке информационных моделей ХД и ВД использовались модели «сущность-связь» (ER-модели) [75]. Модель "сущность-связь" представляет собой высокоуровневую концептуальную модель данных. Данная модель – это набор концепций, которые описывают структуру БД и связывают с ней транзакции обновления и извлечения данных. На основании модели «сущность-связь» были построены таблицы для занесения данных. Таблицы строились с помощью программного средства Database Desktop в среде визуального программирования Delphi 7.0 с использованием Paradox 7. Процесс их проектирования проводился с использованием инструмента BP-Win [63]. На его основе из логической модели данных была сформированафизическая база данных. При этом были реализованы такие процессы, как
66
-преобразование логической модели данных в набор таблиц с учетом ограниченийцелостности данных;
-выбор конкретных структур хранения и методов доступа к данным, обеспечивающих необходимый уровень производительности при работе с БД;
-проектирование мер защитыданных.
Вышеизложенный подход к проектированиюХД обеспечил:
-контроль избыточности данных;
-непротиворечивость данных;
-увеличение количества полезной информации при фиксированном объеме хранимых данных;
-совместное использование данных;
-поддержку целостности данных;
-повышенную безопасность;
-возможность применения стандартов представления данных;
-повышение эффективности обработки данных с ростом масштабов системы;
-повышение оперативности доступа к данным и их готовности к использованию;
-упрощение сопровождения системы;
-развитие службы резервного копирования и восстановления данных. ПриразработкеХД учитывалисьследующиеособенностиегоэксплуатации:
-использование для хранения текстовых, качественных и количественных данных;
-обеспечение возможности варьирования требований к запрашиваемой информации (изменение структуры запросов и др.);
-обеспечение гибкости модели хранения данных и приемлемой производительности обработки запросов.
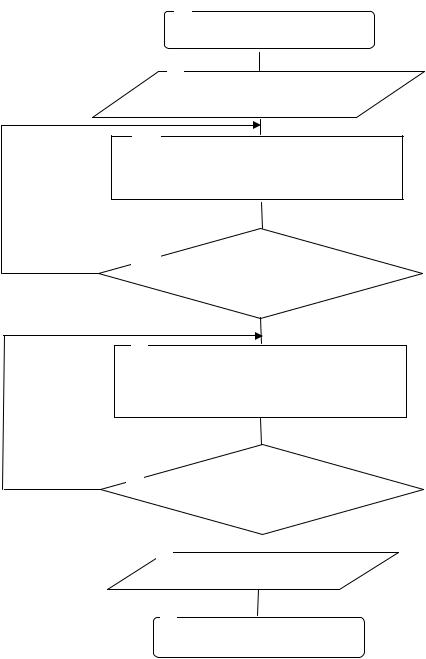
Модуль эвристической оптимизации ХД обеспечил формирование рациональной структуры ХД. С этой целью в рамках данного модуля был разработан специальный алгоритм эвристической оптимизации, блок-схема которого представлена на рис. 2.10.
Блоки 1 и 8 используются для пуска и остановки алгоритма эвристической оптимизации структуры базы данных.
В блоке 2 реализован ввод исходных данных, таких как число уровней нормализации и число индексируемых полей.
В блоке 3 реализована многоуровневая нормализация ХД. Нормализация
-это формальный метод анализа отношений на основе их первичного ключа и существующих функциональных зависимостей. В ходе нормализации формат отношений становится все более ограниченным (строгим) и менее восприимчивым к аномалиям обновления. В теории реляционных баз могут использоваться 5 нормальных форм. Любой нормальной форме соответствует известныйнабор
67
1
Начало
2
Ввод исходных данных
Нет
Нет
3
Многоуровневая нормализация
базы данных
4
Достаточен ли уро-
вень нормализации БД ?
Да
5
Индексирование базы данных
6 |
|
Достаточен ли уро- |
|
|
|
вень индексирования |
|
|
|
БД ? |
|
|
7 |
|
Да |
|
|
||
|
|
|
|
|
|
Вывод результатов |
|
|
8 |
|
|
|
|
Конец |
|
Рис. 2.10. Блок-схема алгоритма эвристической оптимизации
структуры базы данных
ограничений. Отношение находится в определенной нормальной форме, если оно удовлетворяет набору ограничений этой формы. С переводом структуры отношений базы данных в формы более высокого порядка происходит удаление изтаблиц избыточной неключевой информации [199].
Первая нормальная форма (1НФ) - отношение, в котором на пересечении каждой строки и каждого столбца содержится одно и только одно значение.
Вторая нормальная форма (2НФ) - отношение, которое находится в первой нормальной форме и каждый атрибут которого, не входящий в состав пер-
68
вичного ключа, характеризуется полной функциональной зависимостью от этого первичного ключа
Третья нормальная форма (ЗНФ) - отношение, которое находится в первой и во второй нормальных формах и не имеет атрибутов, не входящих в первичный ключ атрибутов, которые находились бы в транзитивной функциональной зависимости от этого первичного ключа.
Четвертая нормальная форма (4НФ) - отношение в нормальной форме Бойса-Кодда, которое не содержит нетривиальных многозначных зависимостей.
Пятаянормальнаяформа(5НФ)-отношениебез зависимостейсоединения. Чтобы избежать аномалий обновления, нормализацию рекомендуется выполнять как минимум до третьей нормальной формы (ЗНФ) [33]. Также третья нормальная форма (3НФ) служит компромиссом между полной нормализацией и функциональностью в совокупности с легкостью реализации. Нормальные формы, выше третьей, затрудняют разработку структур данных и снижают их
функциональность. Поэтому была проведена нормализация до ЗНФ.
Блок 4 обеспечивает проверку достаточности уровня нормализации ХД. Если он достаточен, то управление передается в блок 5. В противном случае управление передается в блок 3.
Вблоке 5 реализовано индексирование ХД. Индекс – это структура данных, которая помогает системе управления базами данных быстрее обнаружить отдельные записи в файле и сократить время выполнения запросов пользователей. Индекс в ХД аналогичен предметному указателю в книге. Он позволяет избежать проведения последовательного или пошагового просмотра файла в поисках нужных данных. Как и предметный указатель книги, индекс базы данных упорядочен, и каждый элемент индекса содержит название искомого объекта, а также один или несколько указателей (идентификаторов записей) на место его расположения. Индекс занимает намного меньший, чем таблица, объем памяти, поэтому даже полный перебор значений в нем является более быстрой операцией, чем считывание и поиск информации в отношении. Кроме того, значения в индексе хранятся упорядоченно, что позволяет ускорить поиск нужной строки. Индексы дают возможность выбирать строки отношений, значения индексируемого атрибута которых принадлежит некоторому заданному интервалу. Для одного отношения может быть создано несколько индексов. Если разные отношения содержат одинаковые атрибуты, то для них может быть сформирован мультииндекс. В нем каждому значению общего атрибута соответствует несколько ссылок, каждая из которых указывает на строку с таким значением в том или ином отношении.
Блок 6 обеспечивает проверку уровня достаточности индексирования ХД. Если он достаточен, то управление передается в блок 7. В противном случае управление передается в блок 5.
Блок 7 обеспечивает вывод результатов в видеоптимизированного ХД.
Вкачестве примера в табл. 2.5 приведены данные, хранящиеся в ХД,
69
предназначенные для обучения искусственной нейронной сети. В качестве данных приведены значения котировок акций ОАО «Газпром», имевших место в период с 25.03.2014 по 04.04.2014 г.
Таблица 2.5
Данные, хранящиеся вХД для обучения ИНС
Дата |
25.03.14 |
28.03.14 |
29.03.14 |
30.03.14 |
31.03.14 |
01.04.14 |
04.04.14 |
Цены открытия |
224,87 |
223,01 |
225,9 |
225,51 |
229,38 |
229,1 |
235,98 |
Норм. цена от- |
|
|
|
|
|
|
|
крытия |
0,23 |
0,15 |
0,27 |
0,26 |
0,42 |
0,40 |
0,69 |
Цены закрытия |
222,81 |
225,5 |
224,01 |
229,32 |
229,09 |
235,1 |
237,7 |
Норм. цена за- |
|
|
|
|
|
|
|
крытия |
0,11 |
0,22 |
0,16 |
0,38 |
0,37 |
0,62 |
0,73 |
Прогнозная |
|
|
|
|
|
|
|
цена |
223,01 |
225,9 |
225,51 |
229,38 |
229,1 |
235,98 |
238,46 |
Норм. прогноз |
0,14 |
0,26 |
0,25 |
0,41 |
0,40 |
0,68 |
0,79 |
Встроках таблицы используются значения таких характеристик, как
-«Дата» – дата, на которую приведены значения акций;
-«Цена откр.» – цена за акцию на момент открытия торгов;
-«Цена закр.» – цена за акцию на момент закрытия торгов;
-«Прогнозная цена» – цена открытия торгов на следующий день, значение которой необходимо спрогнозировать;
-«Норм. цена откр.», «норм. цена закр.», «норм. прогноз» – нормализованные значения.
Определение рациональной структуры ХД проводилось экспериментальным (эвристическим ) путем.
Для различных вариантов структур ХД для подсистемы исследования ИНС формировалось множество запросов на поиск определенных атрибутов информации (по одному полю и по множеству полей). При этом время обработки каждого одноаспектного или многоаспектного запроса фиксировалось.
После завершения реализации множества запросов для соответствующего варианта структуры ХД оценивалось среднее время обработки множества запросов. Затем полученные значения сравнивались и выбирался тот вариант структуры ХД, для которого значение среднего времени обработки множества запросов было минимальным.
Полученные значения усредненного времени реализации запросов приведены в табл. 2.6.
Анализ полученных данных показывает, что время обработки запросов для ХД в 1НФ гораздо больше, чем время обработки запросов для ХД в 3НФ. Таким образом, можно сделать вывод о том, что оптимальной структурой ХД для подсистемы исследования ИНС является структура ХД, приведенная к 3НФ, все поля которой проиндексированы.
70