

Методическое пособие 701
.pdfсложности нейронной сети и тесно связана с количеством содержащихся в ней весов. Значение уменьшается по мере возрастания отношения количества обучающих выборок к уровню сложности сети. Значение МВЧ функционально зависит от количества синаптических весов, связывающих нейроны между собой. Чем больше количество различных весов, тем больше сложность сети и соответственно значение меры VCd. Верхняя и нижняя границы МВЧ определяются в соответствии с неравенством
2 K N VC 2N |
w |
(1 lgN |
n |
) |
, |
(2.69) |
|||
|
2 |
|
d |
|
|
||||
|
|
|
|
|
|
|
|
|
|
где [ ] – целая часть числа, N – размерность входного вектора, К-количество нейронов скрытого слоя, Nw – общее количество весов сети, a Nn-общее количество нейронов сети.
Из выражения (2.69) следует, что нижняя граница диапазона приблизительно равна количеству весов, связывающих входной и скрытый слои, тогда как верхняя граница превышает двукратное суммарное количество всех весов сети. В связи с невозможностью точного определения меры VCd в качестве ее приближенного значения используется общее количество весов нейронной сети[174].
Таким образом, на погрешность обобщения оказывает влияние отношение числа обучающих выборок к количеству весов сети. Небольшой объем обучающего подмножества при фиксированном количестве весов вызывает хорошую адаптацию сети к его элементам, однако не усиливает способности к обобщению, так как в процессе обучения наблюдается относительное превышение числа подбираемых параметров (весов) над количеством пар фактических и ожидаемых выходных сигналов сети. Эти параметры адаптируются с чрезмерной (а вследствие превышения числа параметров над объемом обучающего множества - и неконтролируемой) точностью к значениям конкретных выборок, а не к диапазонам, которые эти выборки должны представлять. Фактически задача аппроксимации подменяется в этом случае задачей приближенной интерполяции. В результате всякого рода нерегулярности обучающих данных и измерительные шумы могут восприниматься как существенные свойства процесса. Функция, воспроизводимая в точках обучения, будет хорошо восстанавливаться только при соответствующих этим точкам значениях. Даже минимальное отклонение от этих точек вызовет значительное увеличение погрешности, что будет восприниматься как ошибочное обобщение. Результаты численных экспериментов показали, что высокие показатели обобщения достигаются при превышении числа обучающих выборок МВЧ в несколько раз. Однако при чрезмерном количестве нейронов и весов в сети возникает эффект гиперразмерности, приводящий к значительным ошибкам [174]. Поэтому для оптимизации числа используемых нейронов использовался алгоритм каскадной корреляции Фальмана. Его суть заключается в динамическом добавлении нейронов в ИНС по результатам оценки ее обобщающих свойств после определенного количества циклов обучения. Достоинством данного алгоритма является частич-
131
ное сохранение результатов обучения сети, полученных на предыдущих итерацияхобучения. Реализация данного алгоритма заключалась в следующем.
На начальном этапе обучения ИНС использовалось количество нейронов, заведомо недостаточное для решения задачи. Для обучения использовались вышеизложенные алгоритмы (обратного распространения ошибок, генетический или имитации отжига), обычные методы. Обучение происходило до тех пор, пока ошибка не переставала убывать и не выполнялисьусловия:
E(t) E(t ) |
|
|
|
||
|
|
|
r |
|
|
|
E(t0) |
, |
(2.70) |
||
|
|
||||
|
|
|
|
|
|
t t0 |
|
|
|
||
где t – время обучения; r – пороговое значение убыли ошибки; – ми-
нимальный интервал времени обучения между добавлениями новых нейронов; t0 – момент времени последнего добавления.
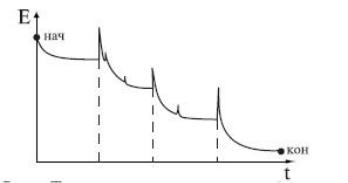
Когда выполнялись оба условия, добавлялся новый нейрон. Веса и порог нейрона инициализировались небольшими случайными числами. Обучение повторялось до тех пор, пока не выполнялось условие (2.68). Зависимость значения ошибки от времени обучения для алгоритма каскадной корреляции Фальмана приведена на рис. 2.36.
Рис. 2. 36. Зависимость значения ошибки от времени обучения ИНС для алгоритмаФальмана
Моменты добавления новых нейронов отмечены пунктиром. После каждого добавления ошибка сначала резко возрастает, т.к. параметры нейрона случайны, а затем быстро сходится к меньшему значению.
В интересах рационального подбора архитектуры ИНС, наряду с алгоритмом каскадной корреляции Фальмана, использовался способ минимизации сети, основанный на модификации целевой функции, позволяющей выявлять и исключать малоактивные скрытые нейроны. Его выбор обусловлен максимальной технологической приспособленностью к общему процессу обучения ИНС в данной работе. В данном способе учитывается, что если выходной сигнал како- го-либо нейрона при любых обучающих выборках остается неизменным (на его выходе постоянно вырабатывается 1 или 0), то его присутствие в сети излишне. И, напротив, при высокой активности нейрона считается, что его функциониро-
132

вание дает важную информацию. При этом модифицированная целевая функция, предложеннаяИ. Шовеном [174], имела вид:
|
K |
p |
|
E(w) E(0) |
(w) e( 2ij ). |
(2.71) |
|
|
i 1 |
j 1 |
|
В этом выражении ij означает изменение значения выходного сигнала i-го нейрона для j-й обучающей выборки, а e( 2ij ) – это корректирующий фак-
тор целевой функции, зависящий от активности всех К скрытых нейронов для всех j(j = 1, 2, ..., р) обучающих выборок. Коэффициент m определяет степень относительного влияния корректирующего фактора на значение целевой функции. Вид корректирующей функции подбирался так, чтобы изменение целевой функции зависело от активности скрытого нейрона, причем при высокой его активности (т.е. частых изменениях значения выходного сигнала). Величина
Е должна быть малой, а при низкой активности – большой. Это достигалось применением функции е, удовлетворяющей отношению:
|
|
|
e( 2i ) |
|
1 |
|
|
|
e |
|
2i |
(1 2i )n . |
(2.72) |
||||
|
||||||||
Индекс п позволяет управлять процессом штрафования за низкую активность.
При n = 2 функция е принимает вид: e 1 1 2i . Малая активность нейро-
нов карается сильнее, чем высокая, что в конечном итоге приводит к полному исключению пассивных нейронов из сети.
Оба подхода к оптимизации архитектуры сети, основанные как на учете чувствительности, так и на модификациях целевой функции, привели к минимизации количества весов и нейронов сети, уменьшив таким образом уровень ее сложности и улучшив соотношение между количеством обучающих выборок и МВЧ. Это обеспечило возрастание способности сети к обобщению.
При программной реализации алгоритма каскадной корреляции Фальмана в среде Delphi, в интересах задания межнейронных связей использован компонент StringGrid, позволяющий обрабатывать большие массивы данных
(рис.2.37).
Рис. 2.37. Компонент StringGrid, используемый в интересах задания межнейронных связей
133
Кроме того, в совокупности с данным компонентом использован компонент «Hint», обеспечивающий отображение реквизитов (номер строки и столбца) на сфокусированном элементе матрицы. Последнее обеспечило удобство поиска необходимой связи с целью последующего изменения ее состояния.
Модуль «Эвристическая оптимизация» обеспечивает оптимизацию выбора ряда параметров действующих алгоритмов формирования и обучения ИНС эмпирическим путем.
Применительно к алгоритму обратного распространения ошибок эвристический подход использовался для его модификации и уточнения ряда параметров. Проведенные вычислительные эксперименты показали, что, как и любой градиентный алгоритм, метод обратного распространения ошибок "застревает" в локальных минимумах функции ошибки, т.к. градиент вблизи локального минимума стремится к нулю. Это приводило к большим ошибкам сети и ее дальнейшей непригодности. Суть первого способа преодоления локального минимума заключалась в неоптимальном выборе шага дискретизации. Было обнаружено явление, оправдывающее неоптимальный выбор шага. Известно, что поверхность функции ошибок E(P) имеет множество долин, седел и локальных минимумов. Оказалось, что первый найденный минимум редко имел малую величину E. Чем больше нейронов и синапсов было в сети, тем менее часто определялся глобальный минимум целевой функции. Выбор неоптимального шага приводил к тому, что он, в силу своей большой величины, позволял выходить из окрестности одного локального минимума и попадать в окрестность другого минимума. Для того, чтобы из-за большого шага дискретизации не «проскочить» другие локальные минимумы и, возможно, глобальный минимум, был разработан специальный алгоритм. Его идейную основу составил алгоритм «упругого распространения» - Rprop [174]. Данный алгоритм использует знаки частных производных для подстройки весовых коэффициентов. Для определения величины коррекции используется следующее правило:
|
|
|
|
|
|
(t) |
|
|
E(t) |
|
|
E(t 1) |
||||||
|
|
|
|
|
|
|
ij |
|
, |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
wij |
|
|
|
wij |
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
(t) |
|
|
E |
(t) |
|
|
E |
(t 1) |
||||
|
|
(t) |
|
|
|
|
|
|
|
|
||||||||
|
|
|
ij |
|
|
|
ij |
|
, |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
wij |
|
|
|
wij |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
1 |
|
|
|||||||
|
|
|
|
|
0 |
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
где wijn |
E |
, а wijn |
jn |
yin 1. |
||||||||||||||
wij |
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
0
0 , (2.73)
Если на текущем шаге частная производная по соответсвующему весу wij изменила знак, то из этого следует, что последнее изменение было большим и алгоритм «проскочил» локальный минимум. Следовательно, величину измене-
134
ния необходимо уменьшить на и вернуть предыдущее значение весового ко-
эффициента, то есть сделать «откат» - wij (t) wij (t) (ijt 1) . В отличие от это-
го действия в разработанном модифицированном алгоритме Rprop «откат» заменяется «обратным ходом» с уменьшенным шагом дискретизации. Применительно к алгоритму имитации отжига это эквивалентно незначительному разогреву металла (вещества). Дальнейшие действия реализуются в соответствии с алгоритмом Rprop.
Если знак частной производной не изменился, то нужно увеличить величину коррекции на для достижения более быстрой сходимости. В результате
проведенных экспериментов было установлено, что целесообразно выбирать=1,2, а =0,5. Начальные значения для всех ij устанавливались равными
0,1. Для вычисления значения коррекции весов использовалось следующее правило:
|
(t) |
|
|
E(t) |
|
|
|
|
ij |
, |
|
|
|
0 |
|
||
wij |
|
|||||||
|
|
|
|
|
|
|
||
|
|
|
|
E |
(t) |
|
|
|
|
(t) |
|
|
|
|
|
|
|
wij (t) ij |
, |
|
|
|
0 |
|
||
wij |
|
(2.74) |
||||||
|
|
|
|
|
. |
|||
|
E |
(t) |
|
|
|
|
||
|
|
|
0 |
|
|
|
||
0, |
w |
|
|
|
|
|||
|
ij |
|
|
|
||||
|
|
|
|
|
|
|
||
Если производная положительна, т. е. ошибка возрастает, то весовой коэффициент уменьшался на величину коррекции, в противном случае – увеличивался.
Затем веса подстраивались в соответствии с выражением
wij (t 1) wij (t) wij (t). |
(2.75) |
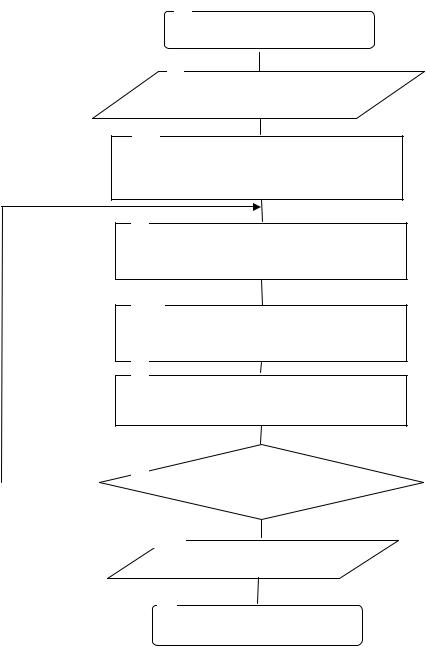
Блок-схемамодифицированного алгоритма Rprop приведена на рис. 2.38. Блоки 1,9 используются для пуска и остановки процесса обратного рас-
пространения ошибок.
В блоке 2 реализован ввод исходных данных.
Блок 3 обеспечивает инициализацию значений величин коррекции ij.
В блоке 4 предъявляются все примеры из выборки и вычисляются частные производные.
Блок 5 рассчитывает новые значения ij по формулам (2.73) и (2.74).
В блоке 6 реализуется корректировка весов в соответствии с выражением
(2.75).
Блок 7 проверяет условие останова данного процесса. Если условие останова не выполняется, то управление передается блоку 4. В противном случае управление передается блоку 8.
135
1
Начало
2
Ввод исходных данных
3
Инициализация ij
4
Расчет частных производных
5
Расчет нового значения ij
6
Корректировка весов
Нет |
7 |
Проверка условия |
|
|
останова |
|
|
8 Да
Вывод результатов
9
Конец
Рис. 2.38. Модифицированный алгоритм Rprop
В блоке 8 реализован вывод полученных результатов.
Совокупность проведенных экспериментов (более 200) показала, что данный алгоритм сходится почти в 6 раз быстрее, чем стандартный алгоритм обратного распространения ошибок, и на 30 % быстрее, чем алгоритм Rprop.
Другой способ преодоления локальных минимумов заключался в обучении с шумом.Корректировкавесовпроводиласьвсоответствииссоотношением
w |
E |
n, |
(2.76) |
|
w |
|
|
где n – случайная величина, имеющая нулевое математическое ожидание и не-
136
большую дисперсию.При выборе n использовалось нормальноераспределение. Реализация данного способа приводила к увеличению времени обучения до 20 %. Однако вероятность определения глобального максимума существенно
возрастала. После обучения ИНС модифицированным алгоритмом Rprop из ста предъявленных тестов ИНС ошибалась лишь в двух. Экспериментальным путем удалось установить, что оптимальная величинаn лежит в пределах 0,012-0,23.
Важными параметрами эвристической оптимизации являются границы нормированных значений входных и выходных сигналов ИНС. Известно, что общепринятый и описанный в литературе динамический диапазон нормированных входных и выходных сигналов ИНС лежит в пределах от 0 до 1 [174]. В ходе проведенных экспериментов было замечено, что применение нормированных значений в диапазоне ±½ уменьшает время сходимости алгоритма обратного распространения. Это обосновывается следующим образом. Так как величина коррекции веса wpq,k пропорциональна выходному уровню нейрона, порождающего OUTp,j, то нулевой уровень ведет к тому, что вес не меняется. При двоичных входных векторах половина входов в среднем будет равна нулю и веса, с которыми они связаны, не будут обучаться. Более эффективным оказывается приведение входов к значениям ±½ и добавление смещения к функции активации, чтобы она также принимала значения ±½. Новая функция активации стала выглядеть следующим образом:
OUT 12 1 e1 NET .
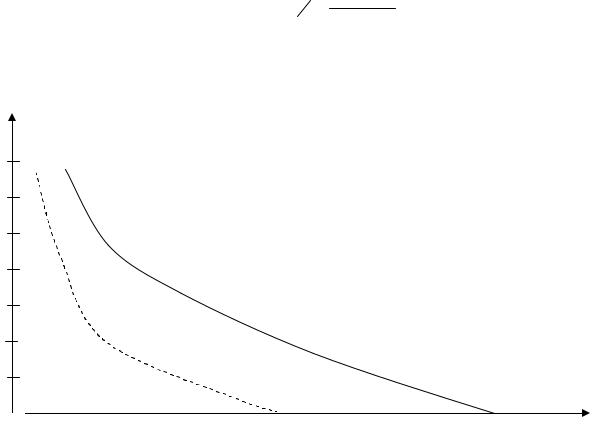
На рис.2.39 показаны графики зависимостей величины достигаемого уровня ошибки E (ось ординат) от числа итераций N (ось абсцисс) для различных видов функции активации, полученные экспериментальным путем.
E
0.07
0.06
0.05
0.04
0.03
0.02
0.01
E0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
N |
0 |
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
220 |
240 |
260 |
280 |
|
||||||||||||||||||||||||||||
Рис. 2.39. Зависимости величины достигаемого уровня ошибки от числа итераций
137
Из данного графика видно, что в результате использования функции активации нового вида (пунктирная кривая) сходимость (скорость достижения порогового значения) увеличилась почти в 2 раза. Последнее означает, что для достижения требуемой точности ИНС теперь требуется не 270 итераций, а лишь 150.
2.4.3. Специальное математическое и программноеобеспечение подсистемыуправления
Подсистема управления ПК НПВР включает модули управления и визуализации.
Модуль управления реализует интерфейс взаимодействия пользователя с подсистемами, общее проведение расчетов и взаимообмен информацией между соответствующими модулями и моделями.
Модуль визуализации (МВ) обеспечивает отображение исследуемой ИНС и проведение визуального моделирования путем исключения каких-либо нейронов, слоев и связей между ними, то есть оперативной корректировки структуры сети. Впервые описание данного процесса приведено в [154,158].
Известно, что в нервных системах реальных биологических объектов, откуда берут свое начало ИНС, некоторые связи между нейронами могут отсутствовать. Более того, отдельные нейроны (и даже группы) могут не действовать. При этом нервная система способна достаточно эффективно функционировать, не «обращая внимания» на существующие «неисправности». Применительно к ИНС данный момент в настоящее время мало изучен. Интересно учесть вышеизложенные особенности в рамках существующей технологии моделирования ИНС, чтобы восполнить этот пробел. Для этой цели в качестве инструмента совершенствования технологии моделирования ИНС для исследователейнеспециалистов в области программирования предлагается использоватьМВ.
МВ обеспечивает визуальное представление матрицы размером n m, где n – число нейронов в слое, m – количество слоев. Каждый элемент матрицы, представляющий собой факт наличия или отсутствия связи на k - м слое между i- м и j- м нейронами, может принимать значение либо «0» - связь отсутствует, либо «1» - связь присутствует.
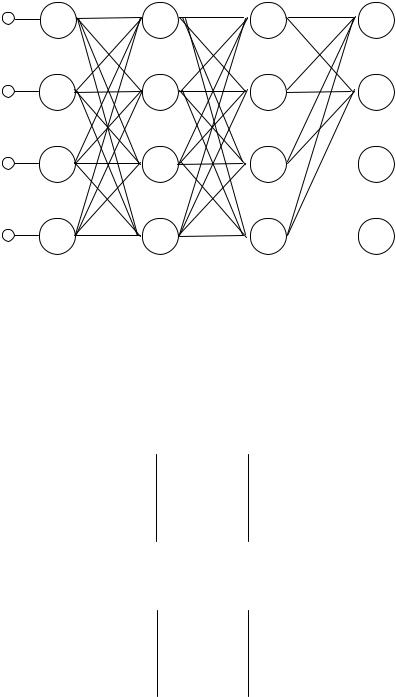
В качестве примера моделируемой ИНС (рис. 2.40) представлен персептрон, имеющий 4 входа, входной (0-й) слой, два скрытых слоя с 4-мя нейронами в каждом и выходной слой с 2-мя нейронами.
Матрица связей для данной ИНС представляется следующим образом:
С0 С0 С0 С0 С1 С1 С1 С1 С2 |
С2 С2 |
С |
2 |
|
|
|||||||||
11 |
12 |
13 |
14 |
11 |
12 |
13 |
14 |
11 |
12 |
13 |
14 |
|
|
|
С210 |
С220 |
С230 |
С240 |
С211 |
С221 |
С231 |
С241 |
С212 С222 |
С232 |
С242 |
. |
(2.77) |
||
С310 С320 |
С330 С340 С311 С321 С331 С341 С312 С322 С332 С342 |
|
|
|||||||||||
С410 |
С420 |
С430 |
С440 |
С411 |
С421 |
С431 |
С441 |
С412 С422 |
С432 |
С442 |
|
|
||
138
|
0 |
1 |
2 |
3 |
1 |
S1 |
S1 |
S1 |
S1 |
|
|
|
|
|
2 |
S2 |
S2 |
S2 |
S2 |
|
|
|
|
|
3 |
S3 |
S3 |
S3 |
S3 |
|
|
|
|
|
4 |
S4 |
S4 |
S4 |
S4 |
|
|
|
|
Рис. 2.40. Двухслойный персептрон
Рассмотрим элемент матрицы С110 . Верхний индекс указывает на номер
слоя (в данном случае 0-й, т.е входной). В нижнем индексе указаны номера взаимодействующих нейронов (в данном случае оценивается взаимодействие 1-го нейрона 0-го слоя с 1-м нейроном 1-го скрытого слоя).
Если рассматривается случай, когда имеются взаимодействия между всеми нейронами ИНС, представленный на рис. 2.40, то матрица связей с установленными значениями примет вид
111111111100
111111111111111111110000 . (2.78)
111111111100
Если рассматривается случай, когда в ИНС, представленной на рис. 2.40, отсутствует взаимодействие между 2 - м нейроном 1-слоя и 4-м нейроном 2-го слоя, то матрица связей с установленными значениями примет вид
111111111100
111111101111111111110000 . (2.79)
111111111100
Матрица (2.79) используется при проведении расчетов в рамках последующих действий с ИНС, в частности при обучении, тестировании или эксплуатации. Значения установленных коэффициентов используются в качестве сомножителей при определении значений суммарных сигналов, поступающих на нейроны с различных входов (в качестве входов рассматриваются нейроны предыдущего слоя). Нулевые значения коэффициентов исключают из рассмотрения соответствующие входы, что эквивалентно разрыву связи между соответствующими нейронами.
139
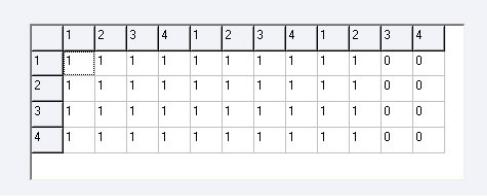
Для программной реализации технологии визуального моделирования в ПК НПВР использован стандартный компонент программной среды разработки Delphi 7.0 – StringGrid, представленный на рис. 2.37. Его безусловным достоинством является возможность обработки больших массивов данных. Визуальное представление моделируемой ИНС, приведенной на рис. 2.40, с использованием данного компонента отображено на рис. 2.41.
Рис. 2.41. Визуальноепредставление моделируемой ИНС
С целью повышения наглядности отображения ИНС совместно с компонентом StringGrid использован компонентом Hint. На его основе отображаются реквизиты (номер строки и столбца) на сфокусированном элементе матрицы, что обеспечивает удобство поиска необходимой связи с целью последующего изменения ее состояния. Применение МВ позволило более гибко моделировать структуру ИНС и обеспечило проведение исследований класса малоизученных (так называемых «изъянных») ИНС [80].
2.5. Порядок использования и результаты апробации программного комплекса нейросетевого прогнозирования временных рядов
Для запуска программного комплекса необходимо выполнение файла ПК НСПВР.exe. После запуска появится главное окно программы (рис. 2.42).
ПК НПВР выполнен в виде SDI – приложения с набором основных вкладок: «Подготовка данных», «Обучение», «Прогнозирование». Рассмотрим предназначение и функциональную составляющую каждой из вкладок.
Вкладка «Подготовка данных» обеспечивает реализацию этапа формирования обучающей выборки. От состава, полноты, качества обучающей выборки существенно зависят время обучения ИНС и достоверность получаемых прогнозов. Для ее загрузки необходимо выбрать соответствующий текстовый файл, в котором она хранится. При формировании обучающей выборки учитывался тот факт, что количество примеров должно быть достаточно большим, чтобы сеть могла учесть широкий диапазон колебаний цены. Кроме того, учитывались особенности, изложенные в разделе 2.4.2. После загрузки обучающей выборки необходимо указать поля, которые будут использоваться при обучении сети и
140