Методическое пособие 701
.pdf1
Начало
2
Ввод текста
3
Формализация текста
4
Выделение терминов
5Преобразование терминов
кканоническому виду
|
|
6 |
|
|
|
|
|
|
||
|
|
|
Фильтрация терминов |
|
|
|
||||
|
|
|
|
|
по стоп-словарю |
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
7 |
|
|
|
|
|
|
|
|
|
|
|
Накопление частот |
|
|
|
||||
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
встречаемости используемых |
|
|
|
||
|
|
|
|
|
|
терминов |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8 |
|
|
|
|
|
|
|
|
|
|
|
Формирование ТПТ |
|
|
|
||||
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
9 |
|
|
|
Нет |
|||||
|
|
Идентификация |
||||||||
|
|
|
|
|
|
ТПТ |
|
|
|
|
|
|
|
|
10 |
|
Да |
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
Вывод результатов |
|
|
|
||
|
|
|
|
11 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
||
Конец
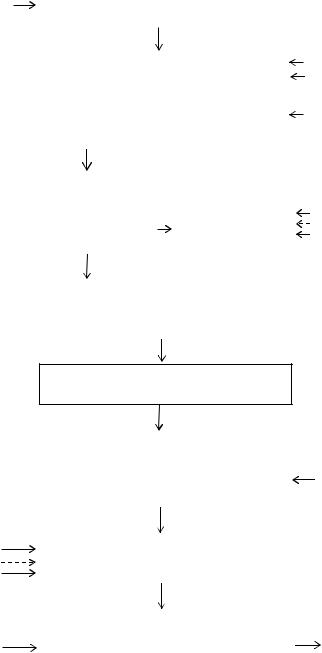
Рис. 3.3. Блок-схема алгоритма идентификации текста
Блоки 1, 11 реализуют начало и окончание процесса идентификации тек-
ста.
Блок 2 обеспечивает ввод исходного текста.
В блоке 3 осуществляется формализация текста на основе соответсвующей модели - многоуровневой иерархической схемы текстовых данных (см. рис. 3.1) [42], реализованной в ряде информационных систем [73, 77, 87, 110, 151]. В ней используется 5 уровней иерархии: дискурс (связный текст); предложение; словосочетание; слово; морфема. Уровни с 6 по 8 предназначены для звукового анализа и в данной работе не рассматриваются.
181
В блоке 4 реализовано выделение терминов. Для выделения терминов и построения терминологического портрета текста используется специальный иерархический терминопостроитель, содержащий соответствующую систему моделей и алгоритмов терминологического поиска. Его детализация приведена в п. 3.6.
Блок 5 используется для преобразования выделенных терминов к каноническому виду с целью определения их морфологических форм (отрицательная форма, нестандартная ситуация, существительное, сравнительная степень прилагательного, краткое прилагательное, краткая форма прилагательного или причастия, прилагательное или причастие, наречие или сложное прилагательное с дефисом, деепричастие от глагола совершенного вида, деепричастие от глагола несовершенного вида, повелительное наклонение глагола, неправильный глагол, глагол, прошедшее время глагола, возвратная форма глагола).
Блок 6 обеспечивает фильтрацию выделенных терминов по стоп–словарю для исключения из рассмотрения заведомо неперспективных терминов (предлоги, частицы, союзы, местоимения и др).
В блоке 7 реализовано накопление и анализ частот встречаемости выявленных терминов с целью определения их весов.
Блок 8 формирует ТПТ, представляющий собой вектор весов информационных признаков (v1,…,vк), где vi – вес i-го признака i=1,…,k в тексте, k – число признаков. Вес i-го информационного признака соответствует частоте встречаемости терминов, из которых он состоит, и определяется в соответствии с выражением
v |
ni |
, |
(3.61) |
|
N |
||||
i |
|
|
где ni – число терминов i-го признака в данном тексте; N – общее количество терминов.
В блоке 9 реализована идентификация ТПТ. Для принятия решения о соответствии данного текста исследуемой предметной области - ТПИС рассчитывается значение косинуса угла между весовыми векторами ТПТ и ТПИС. Порядок проведения расчетов следующий.
Рассмотрим в n-мерном пространстве два произвольных вектора АВ и CD
с координатами ai |
, bi , ci , di : |
|
|
AB b1 a1,b2 a2, ,bn an , |
(3.62) |
|
CD d1 c1,d2 c2, ,dn cn . |
(3.63) |
Координаты |
ai , bi , ci , di являются координатами случайных |
величин |
А= a1 ,a2 , ,an , В= b1 ,b2 , ,bn , С= c1,c2 , ,cn и D= d1,d2 , ,dn . На всей области определения , они имеютнормальное распределение.
Введем систему прямоугольных координат. Тогда случайные величины X и Y, равные A – B и C – D соответственно, будут представлять собой те же векторы, которые проведены из начала координат. Формально это записывается
182
следующим образом:
|
|
|
|
|
xi bi ai , |
|
|
|
|
|
|||||
Известно [19, 193], |
|
что r X , Y |
yi |
di ci . |
|
|
|
|
|
||||||
|
– |
выборочный коэффициент корреляции |
|||||||||||||
|
|
|
ˆ |
|
|
|
|
|
|
|
|
|
|
|
|
двух независимых случайных величин X и Y, определяется в соответствии с |
|||||||||||||||
выражением |
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
coˆv X,Y |
|
|
|
|
n xi mˆ X yi mˆ Y |
|
||||||
|
|
|
|
|
|
|
|
|
|||||||
rˆX, Y |
|
|
|
|
|
|
n i 1 |
|
|
|
, |
(3.64) |
|||
|
ˆX ˆY |
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
||||||||||
|
|
|
1 |
|
n |
2 |
n |
2 |
|
|
|||||
|
|
|
|
|
|
|
|
|
xi mˆ |
X |
yi mˆ |
Y |
|
||
|
|
|
|
|
|
|
n |
|
|
||||||
|
|
|
|
|
|
|
|
i 1 |
|
i 1 |
|
|
|
||
где ˆX и ˆY – оценки средних квадратических отклонений величин Х и Y соответственно; coˆv X,Y – оценка второго смешанного центрального момента случайной величины (X,Y), также называемого корреляционным моментом; mˆx и mˆ y – оценки математических ожиданий величин Х и Y.
Более подробно выражение (3.64) может быть записано следующим обра-
зом [54]:
|
|
1 xi mˆX yi mˆY |
|
|
|
|
|
1 bi ai mˆB A di ci mˆD C |
|
|
|
|||||||||
|
|
|
|
|
n |
|
|
|
|
|
|
n |
|
|
|
|
|
|
||
rˆX, Y |
|
n i 1 |
|
|
|
|
|
|
n i 1 |
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
n |
|
|
|
|
n |
|
|
n |
n |
|
|||||||||
|
|
xi |
2 |
|
2 |
|||||||||||||||
|
|
|
mˆX 2 yi mˆY |
|
bi ai mˆB A 2 di ci mˆD C |
|||||||||||||||
|
|
i 1 |
1 |
|
i 1 |
|
|
|
|
|
i 1 |
i 1 |
|
|
|
|||||
|
|
|
|
|
n bi ai mˆB |
mˆA |
di ci |
mˆD mˆC |
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
n i 1 |
|
|
|
|
|
|
|
|
. |
(3.65) |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
n |
bi ai mˆB mˆA 2 n di ci mˆD mˆC 2 |
|
|
|
|||||||||||
|
|
|
|
|
i 1 |
|
|
|
|
|
i 1 |
|
|
|
|
|
|
|||
Математические ожидания mˆ A , mˆB , mˆC , mˆD |
равны нулю [54], поскольку |
|||||||||||||||||||
величины А, В, С и D имеют нормальное распределение. С учетом этого выражение (3.65) примет вид
|
|
1 |
|
n |
bi ai di ci |
|
|
|
1 |
|
n xi yi |
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
rˆX, Y |
|
|
n i 1 |
|
|
|
|
|
|
n i 1 |
|
|
. |
(3.66) |
||||
|
|
|
|
|
|
|
|
|
|
|
||||||||
n |
bi |
ai 2 n |
di ci 2 |
n |
xi2 n |
|
||||||||||||
|
|
|
|
|
yi2 |
|
||||||||||||
|
|
i 1 |
|
i 1 |
|
|
|
|
i 1 |
i 1 |
|
|
|
|
||||
Выражение (3.66) формально отражает тот факт, что для двух случайных векторов, координаты которых нормально распределены в пространстве, значение косинуса угла между этими векторами представляет собой значение коэффициента корреляции.
Если рассчитанное значение коэффициента корреляции меньше некоторого порогового значения, то управление передается в блок 11. В противном случае управление передается в блок 10.
Блок10выводитрезультатопринадлежностиисследуемоготекстаТПИС.
183