

Методическое пособие 701
.pdf1
Начало
2
3
Формирование
M- начальных популяций
4
Расчет приспособленности инди-
видуума и популяции в целом
5
Выбор индивидуумов для
скрещивания
6
Скрещивание индивидуумов
7
Реализация процедуры
мутации
8
Формирование новой
популяции n=n+1; n N
Нет |
9 |
Определение мак- |
|
||
|
|
симума ЦФ |
10 Да
Анализ результатов параллельных вычислений: обмен индивидуумами для формирования родительских пар, определение и отбор лучшего индивидуума во всей популяции
11
Вывод результатов
12
Конец
Рис. 2.60. Блок–схема генетического алгоритма, совмещенного с островной моделью параллельных вычислений
161
В качестве аппаратной платформы использовались два персональных компьютера (сервера) Intel Pentium IV Dual Xeon 2.8 (двухпроцессорные) с объемом оперативной памяти – 1 Gb, объединенных в единую сеть. Это позволило реализовать проведение параллельных вычислений на 1, 2, 3, и 4 процессорах.
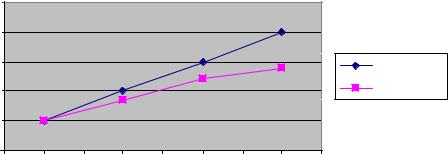
На рис. 2.61 приведены зависимости изменения ускорения проведения вычислений от числа используемых процессоров для теоретических и реальных условий. Результаты получены относительно расчетов, проведенных на одном процессоре. Данные зависимости имеютразличия.
Ускорение5 |
|
|
|
|
4 |
|
|
|
|
3 |
|
|
|
Теоретич. |
|
|
|
С |
|
2 |
|
В |
Реальное |
|
1 |
|
|
|
|
А |
|
|
|
|
0 |
|
|
|
|
Количество процессоров1 |
2 |
3 |
4 |
|
Рис. 2.61. Зависимости изменения ускорения проведения вычислений от количества используемых процессоров
На участке |АВ| различие незначительное, оно обусловлено несовершенством используемого программного обеспечения (используется относительно «медленная» среда разработки Delphi). На участке |ВС| различие более существенно, поскольку для реализации глобальных операций параллельных вычислений используется сетевой обмен данными, что существенно замедляет оперативность. Тем не менее, прирост в быстродействии при использовании 4 процессоров значителен (примерно на 3 порядка по скорости).
Таким образом, применение модифицированного генетического алгоритма распределения финансовых инвестиций, базирующегося на островной модели параллельных вычислений, позволило при приемлемой точности искомого решения почти на 3 порядка повысить оперативность проведения расчетов.
2.6.2.Программная реализациямодифицированногогенетического алгоритма распределения инвестиций
Реализация генетического алгоритма распределения финансовых инвестиций представлена в виде программного комплекса [95]. В качестве среды разработки модуля использована объектно–ориентированная среда разработки Delphi7.0. Обоснование выбора данной среды представлено в [86,132,154].
Для запуска программы необходимо выполнить файл ProjectGene.exe, расположенный в корневом каталоге клиентской составляющей. В случае его успешного выполнения на экране монитора появится окно главной экранной формыпрограммы, внешний вид которого представлен на рис. 2.62.
162
Рис. 2.62. Окно главной экранной формы программы
Главная экранная форма программы содержит 5 закладок: «Проекты»; «Исходные данные»; «Результаты»; «Помощь»; «Опрограмме».
После выбора закладки «Проекты» пользователю необходимо пройти процедуры аутентификации и идентификации. В результате появится меню «Проекты», содержащее опции: «создать»; «открыть»; «закрыть»; «сохранить»; «печать»; «свойства»; «выход». Пользователь имеет возможность загружать, редактировать и сохранять готовые проекты или формировать новые. Доступ к проектам обеспечивается в интерактивном режиме путем выбора соответствующих дисков, каталогов и папок, в которых они хранятся. При открытии существующего проекта пользовать должен ввести свою учетную запись и пароль, после чего ему будет обеспечен доступ к соответствующей базе данных. При нажатии кнопки «открыть» осуществится загрузка данных из хранилища данных в витринудля текущей работы с ними. Далее пользователю необходимо выбрать закладку «Исходные данные».
При выборе закладки «Исходные данные» появляется меню, содержащее две опции: «Настройка ГА» и «Данные по проектам». Выбор опции «Настройка ГА» приводит к появлению соответствующей экранной формы (рис. 2.63).
Группа исходных данных для настройки ГА включает: количество генов; максимальное число генов; длина гена; максимальное количество хромосом; размер популяции; количество поколений; интенсивность селекции; вероятность кроссовера; вероятность мутации; вероятность инверсии. Для настройки островной модели параллельных вычислений вводятся количество запущенных параллельных процессов и частота обмена данными между островами.
Выбор опции «Данные по проектам» приводит к появлению соответствующей экранной формы (рис. 2.64).
163
Рис. 2.63. Экранная форма «Настройка ГА»
Рис. 2.64. Экранная форма «Данные по проектам»
Для ввода соответствующих значений необходимо нажать кнопку «Применить». После ее нажатия на экране появится экранная форма «Данные по проектам» (рис. 2.64) с внесенными изменениями. После повторного отображения данного окна на нем становится доступной кнопка «Рассчитать». Для дальнейшего проведения расчетов необходимо ее нажатие. Если значения параметров не требуется вводить по каким - либо причинам, нажимается кнопка «Отмена». Кроме того, на данной форме имеются кнопки «Сохранить» и «Закрыть форму», реализующие соответствующие действия.
После проведения расчетов отображается окно с временными затратами
(рис. 2.65).
164
Рис. 2.65. Экранная форма «Завершение процесса расчета»
Результаты работы программы представляются в табличном и графическом видах. На рис. 2.66 приведена экранная форма представления результатов в табличном виде.
Рис. 2.66. Экранная форма «Распределение инвестиций»
Результирующая таблица содержит:
-перечень финансовых инструментов, выбранных пользователем;
-общее распределение суммы по финансовым инструментам;
-помесячное распределение сумм по финансовым инструментам.
На рис. 2.67 приведена гистограмма распределения инвестиций на примере казначейских обязательств.
На оси абсцисс приведенной гистограммы представлены месяцы, а по оси ординат отложены значения инвестиций в тыс. рублях. Подобные гистограммы могут быть представлены для любого финансового инструмента в рамках рассматриваемого проекта. Кроме того, пользователю может быть представлена обобщенная точечная диаграмма распределения инвестиций по всем финансовым инструментам данного проекта (рис.2.68).
165
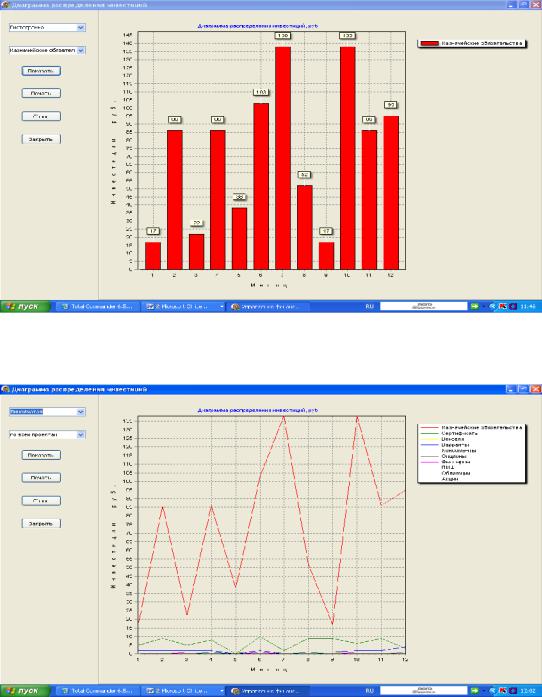
Рис. 2.67. Гистограмма распределения инвестиций
Рис. 2.68. Сводная диаграмма распределения инвестиций
166

РАЗДЕЛ 3 МОДЕЛИ И АЛГОРИТМЫ ТЕРМИНОЛОГИЧЕСКОГО ПОИСКА
3.1.Модель формализации текстовой информации
Реализация терминологического поиска в СППИР предполагает формализацию текстов. Формализация обеспечивает представление текстовой информации в виде формальной системы [30, 68], базирующейся на определённых взаимосвязанных абстракциях – элементах (понятиях, аксиомах, теоремах, свойствах и др.), идеализации и искусственных символических языках (предикатах, моноидах и др.). Иерархическая схема уровней формализации текстовых данныхпредставлена на рис. 3.1 [42].
|
Уровни |
Страты |
Дискурс |
1 |
8 |
|
|
|
Предложение |
2 |
7 |
|
|
|
Словосочетание |
3 |
6 |
|
|
|
Слово |
4 |
5 |
|
|
|
Морфема |
5 |
4 |
|
|
|
Слог |
6 |
3 |
|
|
|
Фонема |
7 |
2 |
|
|
|
Дифференциальный |
8 |
1 |
признак |
Рис. 3.1. Иерархическая схема представления текстовых данных
Формализация позволяет систематизировать, уточнить и методологически прояснить содержание представления текстов, выяснить характер взаимосвязи между собой различных положений их обработки, выявить и сформулировать ещё не решённые проблемы [49]. Важное значение для формализации текста имеет модель, лежащая в ее основе [161]. В различные исторические периоды разрабатывались разнообразные модели формализации текстовой информации. Результаты сравнительного анализа основных моделей формализации текстовой информации представлены в табл. 3.1 [79].
167
168
Таблица 3.1 Результаты сравнительного анализа основных моделей формализации текстовой информации
Название |
Краткое содержание |
|
Достоинства |
Недостатки |
||||
Модель |
Общность языков обусловлена их предназначени- |
1. Впервые пред- |
1. Малое число глу- |
|||||
И. Ньютона |
ем для обозначения субстанций (духов или тел), |
ложена |
оценоч- |
бинных падежей и их |
||||
[171] |
которые у всех народов одинаковы. Носитель слов |
ная шкала |
ис- |
примеров |
|
|
||
|
– предикат, обозначающий отношения. Корень |
пользования |
2. Временная |
шкала |
||||
|
универсального языка относится к какой-то одной |
грамматических |
не походит в качестве |
|||||
|
субстанции (например, необходима специальная |
префиксов и аф- |
формальной |
модели |
||||
|
буква для обозначения видов людей, ангелов, до- |
фиксов |
(плохой- |
времени в силу значи- |
||||
|
мов и т.д.). Предпринята попытка первичной лек- |
хороший, |
боль- |
тельной идеализации |
||||
|
сической категоризации |
шой-маленький и |
|
|
|
|||
|
|
др.) |
|
|
|
|
|
|
|
|
2. |
Проработаны |
|
|
|
||
|
|
глубинные |
паде- |
|
|
|
||
|
|
жи |
|
|
|
|
|
|
|
|
3. |
Разработана |
|
|
|
||
|
|
шкала времени |
|
|
|
|||
Модель |
Все имена собственные произошли от нарица- |
1. |
Категоризация |
Недостаточная |
кате- |
|||
Г.Лейбница |
тельных (общих). Суть механизма метонимиче- |
лексики |
|
|
горизация |
и |
прими- |
|
[205] |
ского переноса локативных предлогов заключает- |
2. |
Введение пер- |
тивный |
семантиче- |
|||
|
ся в их переходе от "чувствительного" простран- |
вого шага семан- |
ский анализ |
|
||||
|
ственного значения к "нечувственному" менталь- |
тического анали- |
|
|
|
|||
|
ному осмыслению. Реальное определение – это |
за на основе но- |
|
|
|
|||
|
определение, которое задает объект, существова- |
минальных и ре- |
|
|
|
|||
|
ние которого подтверждено нашим опытом или |
альных |
опреде- |
|
|
|
||
|
конструктивным доказательством |
лений |
|
|
|
|
|
|
169
Окончание табл. 3.1
|
Название |
Краткое содержание |
|
Достоинства |
|
Недостатки |
|||
|
Лямбда-исчисление |
Разработка формальной семантики на основе ис- |
Применение |
- |
1. |
Сложность полу- |
|||
|
|
пользования -оператора и двух ( и ) операций |
исчисления |
для |
чаемых формул |
||||
|
|
конверсии. -оператор является синтаксическим |
представления |
2. |
Низкая |
эффектив- |
|||
|
|
аналогом кванторов всеобщности и существова- |
смысла высказы- |
ность при работе с на- |
|||||
|
|
ния. Он ставится перед переменной, после чего |
ваний и построе- |
сыщенными |
фрагмен- |
||||
|
|
эта переменная считается связанной и ждет за- |
ния теоретико- |
тами языка |
|
||||
|
|
полнения формулой. Операция -конверсия реа- |
множественных |
|
|
|
|||
|
|
лизует подобные заполнения |
интерпретаций |
|
|
|
|||
|
Семантическая сеть |
Представляет собой множество взаимосвязанных |
1. |
Приемлемая |
1.Высокие требования |
||||
|
|
элементов - слов и словосочетаний. Они несут ос- |
точность темати- |
к вычислительным ре- |
|||||
|
|
новную смысловую нагрузку и наиболее часто |
ческого |
поиска, |
сурсам |
|
|||
|
|
встречаются в тексте. Статистическая обработка |
реферирования и |
2. |
Низкое быстродей- |
||||
169 |
|
элементов (оценка частоты встречаемости) позво- |
др |
|
|
|
ствие |
|
|
|
ляет выявить их вклад в общее содержание доку- |
2. Простота и на- |
3.Необходимость при- |
||||||
|
мента, а последующая весовая обработка позволя- |
глядность |
|
|
влечения |
экспертов |
|||
|
|
|
|
||||||
|
|
ет определить плотность их распределения в до- |
|
|
|
|
для настройки сети |
||
|
|
кументе |
|
|
|
|
|
|
|
|
Искусственная |
Для смысловой обработки текста используется |
1. |
Высокая |
опе- |
1. Сложность |
|||
|
нейронная сеть |
нейронная функциональная алгебра. Нейроны вы- |
ративность |
|
2. Проблемы обучения |
||||
|
|
полняют операции дизъюнкции, конъюнкции и |
2. |
Приемлемое |
|
|
|
||
|
|
отрицания. Структура ИНС определяет порядок |
качество |
обра- |
|
|
|
||
|
|
применения базовых операций к тексту. Отдель- |
ботки тектов |
|
|
|
|
||
|
|
ный нейрон из состава сети, извлекающей смысл |
|
|
|
|
|
|
|
|
|
из текста на естественном языке, соответствует |
|
|
|
|
|
|
|
|
|
элементарному понятию (слово, термин, абзац и |
|
|
|
|
|
|
|
|
|
др.) анализируемого языка |
|
|
|
|
|
|
|
170
Проведенный анализ моделей формализации текстовой информации показывает, что в интересах реализации терминологического поиска необходимо использовать категоризацию лексики, обеспечивающую построение более простых и адекватных моделей представления текстовой информации. Она впервые возникла в моделях Ньютона и Лейбница, а дальнейшее развитие получила в лямбда-исчислении и семантической сети. В ее состав могут быть включены такие важные для терминологического поиска категории, как тезаурус и терминологический портрет. Это позволяет дополнить иерархическую схему представления текстовых данных (см. рис. 3.1) данными категориями и, на начальном этапе, сформировать математическую модель весовой распределенной информационной системы на тезаурусе, а затем на терминологическом портрете.
3.2. Математическая модель весовой распределенной информационной системы на тезаурусе
Рассмотрим ряд понятий необходимых для определения распределенной информационной системы, основанной на тезаурусе [112].
Определение 3.2.1. Тезаурусом будем называть конечное непустое множество T слов t, отвечающих условиям:
1) имеется непустое подмножество T0 T , называемое множеством
дескрипторов; 2) имеется симметричное, транзитивное рефлексивное отношение
R T T, такое, что:
а) t1 t2 |
t1Rt2 (t1 T \T0 ) (t2 T \T0 ); |
(3.1) |
б) t1 T |
\T0 ( t T0 )(tRt1 ); |
(3.2) |
при этом отношение R называется синонимическим отношением, а слова t1 и t2 ,
отвечающим этому отношению, называются синонимическими дескрипторами; 3) имеется транзитивное и несимметричное отношение K T0 T0 , назы-
ваемое обобщающим отношением.
В случае если два дескриптора t1 и t2 удовлетворяют отношению t1Kt2 , то полагается, что дескриптор t1 более общий, чем дескриптор t2 .
Элементы множества T \ T0 называются множеством аскрипторов.
Определение 3.2.2. Информационной системой (ИС) с тезаурусом называется четверка (T, D, M, ), где T – тезаурус с дескрипторным множеством T0; D– коллекция документов; М – множество вопросов; :M 2D – отображение,
сопоставляющее каждому вопросу множество документов.
Пусть описание любого документа d Dможет быть представлено в виде
t(d) {t1 ,t2 , ,tk }, |
(3.3) |
и удовлетворяет отношению К.
Можно также считать, что каждый вопрос m M представляется в форме, аналогичной описанию документов.
Множество описаний вопросов и документов частично упорядочено от-
170