

Методическое пособие 701
.pdfравен нулю. Данная технология аналогична сплайновому подходу к аппроксимации кривых, поскольку нейроны работают в изолированных областях. Сплайн является примером такой кусочной полиномиальной аппроксимации.
В [225] предложено обоснование использования двух скрытых слоев в контексте обратных задач. Постановка данной задачи формулировалась следующим образом.
Для данной непрерывной вектор-функции f : m M , компактного
подмножества C M , которое содержится в пространстве образов функции f, и некоторого положительного 0 требуется найти вектор-функцию :
M m , удовлетворяющую условию

 (f)(u) u
(f)(u) u
 для любого u C.
для любого u C.
Эта задача относится к области обратной динамики, где наблюдаемое состояние х(n) системы является функцией текущих действий u(n) и предыдущего состояния х(n — 1) системы
x(n) = f(x(n-l),u(n)).
Здесь предполагается, что функция f является обратимой, т.е. u(n) можно представить как функцию от х(n) для любого х(n - 1). Функция f описывает прямую динамику, а функция – обратную. В контексте излагаемого материала
необходимо построить такую функцию , которая может быть реализована
многослойным персептроном. В общем случае для решения обратной задачидинамики функция должна быть разрывной. Для решения подобных обратных
задач одного скрытого слоя недостаточно, даже при использовании нейронной модели с разрывными активационными функциями, а персептрона с двумя скрытыми слоями вполне достаточно для любых возможныхС, f и [225].
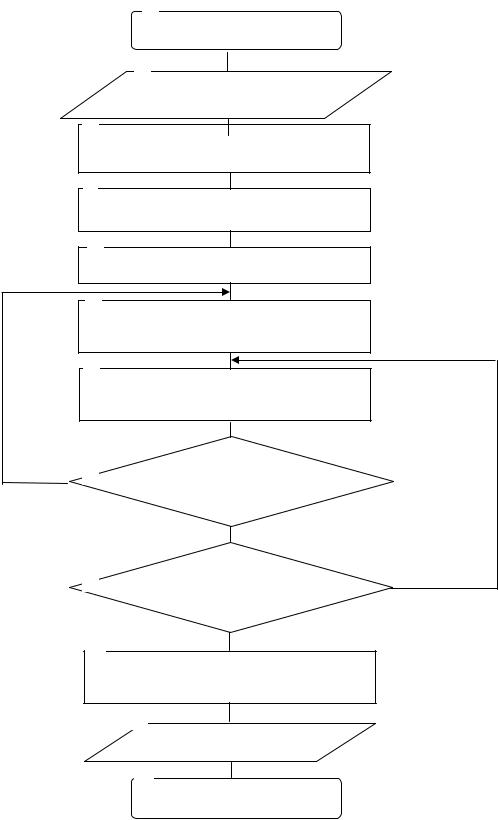
Блок-схема алгоритма формирования многослойного персептрона представлена на рис. 2.27.
Блоки 1, 12 обеспечивают пуск и остановку алгоритма формирования многослойного персептрона.
В блоке 2 реализован ввод исходных данных, таких как:
-начальные значения весовых коэффициентов межнейронных связей;
-вид функции активации. При проведении исследований использовались такие функции активации, как: линейная; пороговая; сигмоидальная; логистическая; гиперболический тангенс; радиально-базисная. Специальный компонент, реализующий сигмоидальную функцию активации в среде Delphi, приведен на рис. 2.28.
В блоке 3 задается число входов во входном слое.
Блок 4 предназначен для задания значений обучающей выборки. Блок 5 используется для нормализации обучающей выборки. В блоке 6 задается число скрытых слоев персептрона.
В блоке 7 задается число нейронов в скрытом слое.
111
1
Начало
2
Ввод исходных данных
3
Задание числа входов
4
Задание обучающей выборки
5
Нормализация обучающей выборки
6
Задание числа скрытых слоев
персептрона
7
Задание числа нейронов в скрытом
слое
Нет 8 |
Удовлетворяет ли |
|
число слоев ? |
Да
Нет
9Удовлетворяет ли
число нейронов?
Да
10
Задание числа разрывов связей ней-
ронов в скрытых слоях
11
Вывод результатов
12
Конец
Рис. 2.27. Блок-схема алгоритма формированиямногослойного персептрона
112
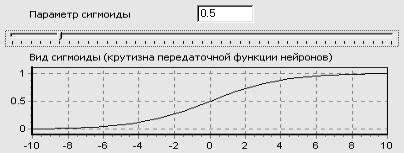
Рис. 2.28. Компонент Delphi, реализующий сигмоидальную функцию активации
Блок 8 обеспечивает проверку условия удовлетворенности пользователем заданного числа слоев.
Блок 9 обеспечивает проверку условия удовлетворенности пользователем заданного числа нейронов.
В блоке 10 в интересах исследования нового класса ИНС задается число разрывов связей нейронов в скрытых слоях. Детализация данного вида исследований приведена в описании подсистемы управления.
Блок 11 реализует вывод результатов. В качестве результата выступает сформированный многослойный персептрон.
Ниже приведен фрагмент программного кодадля данногоалгоритма. nset := TNSet.Create; // создаем нейросеть
// вводим число слоев
//LayerCount:=se3.Value;
LayerCount:=se3.Value+2; //вводим число нейронов в слоях
Layers[0]:=StrToInt(FrmPers.strngrd1.Cells[1,1]);// число нейронов во входном слое
for i:=1 to se3.Value do Layers[i]:=StrToInt(FrmPers.strngrd1.Cells[1,i+1]); // число нейроновв выходном слое
Layers[se3.Value+1]:=StrToInt(FrmPers.strngrd1.Cells[1,se3.Value+2]); // Layers[2]:=0;
//выводим напросмотр for i:=1 to se3.Value do begin
FrmPers.strngrd2.Cells[1,0]:='Кол.нейронов';
FrmPers.strngrd2.Cells[0,1]:='Входнойслой';
FrmPers.strngrd2.Cells[1,1]:=IntToStr(Layers[0]); FrmPers.strngrd2.Cells[0,i+1]:='Скрытый '+IntToStr(i); FrmPers.strngrd2.Cells[1,i+1]:=IntToStr(Layers[i]); FrmPers.strngrd2.Cells[0,i+2]:='Выходной слой'; FrmPers.strngrd2.Cells[1,i+2]:=IntToStr(Layers[i+1]); end;
113

Экранная форма исследования персептронов приведена на рис. 2.29.
Рис. 2.29. Экранная форма исследования персетронов
Модуль «Алгоритм обратного распространения ошибок» предназначен для обучения многослойного персептрона вышеназванным методом в интересах минимизации ошибок его функционирования. Впервые данный метод обучения был предложен Руммельхартом и Хинтоном в 1986 г. На рис. 2.30 показаны потоки функциональных сигналов и сигналов ошибок в многослойном персептроне.
 Функциональные сигналы
Функциональные сигналы
 Сигналы ошибки
Сигналы ошибки
Рис. 2.30. Потоки функциональных сигналов и сигналов ошибок в многослойном персептроне
Сигнал ошибки берет свое начало на выходе сети и распространяется в обратном направлении (от слоя к слою). Он получил свое название благодаря тому, что вычисляется каждым нейроном сети на основе функции ошибки, представленной в той или иной форме. Установлено, что ошибки, делаемые нейронами выходного слоя, возникают вследствие неизвестных пока ошибок нейронов скрытых слоев. Чем больше значение синаптической связи между нейроном скрытого слоя и выходным нейроном, тем сильнее ошибка первого влияет на ошибку второго. Следовательно, оценку ошибки элементов скрытых
114
слоев можно получить как взвешенную сумму ошибок последующих слоев.
С целью упращения пояснения механизма обучения ИНС на основе алгоритма обратного распространения ошибки, ограничимся рассмотрением персептрона с одним скрытым слоем. Матрицу весовых коэффициентов от входов к скрытому слою обозначим W, а матрицу весов, соединяющих скрытый и выходной слой, V. Для индексов примем следующие обозначения: входы будем нумеровать только индексом i, элементы скрытого слоя - индексом j, а выходы, соответственно, индексом k.
Пусть сеть обучается на выборке (X ,Y ), =1..p. Активности нейронов будем обозначать малыми буквами y с соотвествующим индексом, а суммарные взвешенные входы нейронов малыми буквами x.
Пошаговое описание алгоритма обратного распостранения ошибок представлено в табл. 2.11.
Как видно из описания шагов 2-3, обучение сводится к решению задачи оптимизации функционала ошибки градиентным методом.
Параметр характеризует темп обучения ИНС. При его выборе необхо-
дим компромисс. С одной стороны его увеличение приводит к более быстрому обучению ИНС, а с другой – к возрастанию ее неустойчивости (сходимости). Теоретически он (параметр) выбирается достаточно малым для сходимости метода. Результаты экспериментов показали, что сходимость данного метода не высокая. Это обусловлено несовпадением локального направления градиента с направлением к минимуму и независимостью подстройки весов для каждой пары образов обучающей выборки. Последнее означает, что улучшение функционирования на некоторой заданной паре может приводить к ухудшению работы на предыдущих образах.
Для повышения темпа обучения ИНС с учетом сохранения ее устойчивости использовалась следующая методика.
Рассмотрим детализацию шага 3 вышеизложенного алгоритма. Обратный проход начинается с выходного слоя предъявлением ему сигнала ошибки, который передается справа налево от слоя к слою с параллельным вычислением локального градиента для каждого нейрона. Этот рекурсивный процесс предполагает изменение синаптических весов в соответствии с дельта-правилом:
wji(n) j(n)yi(n) |
(2.59) |
где j (n) – локальный градиент; yi (n) – входной сигнал нейрона.
Для нейрона, расположенного в выходном слое, локальный градиент равен соответствующему сигналу ошибки, умноженному на первую производную нелинейной функции активации. Затем соотношение (2.59) используется для вычисления изменений весов, связанных с выходным слоем нейронов. Зная локальные градиенты для всех нейронов выходного слоя, с помощью (2.60) можно вычислить локальные градиенты всех нейронов предыдущего слоя, а значит, и величину коррекции весов связей с этим слоем:
j (n) 'j (vj (n)) k (n)wkj (n). |
(2.60) |
115

|
|
|
|
|
|
|
|
|
|
Таблица 2.11 |
|
Описание алгоритма обратного распространения ошибок. |
|||||||||
Шаг 0. |
Начальные значения весов всех нейронов всех слоев V(t=0) и |
|||||||||
|
W(t=0) полагаются случайными числами. |
|
||||||||
Шаг 1. |
Предъявлениесетивходного образа -X . В результате формируется |
|||||||||
|
выходной образ y Y . При этом нейроны последовательно от слоя |
|||||||||
|
к слою функционируют по следующим формулам: |
|||||||||
|
скрытый слой |
xj WijXi ; |
|
|
|
|
||||
|
|
|
yj f(xj) |
|||||||
|
|
|
i |
|
|
|
|
|
|
|
|
выходной слой |
xk VjkYj ; |
|
|
|
|||||
|
|
|
yk f (xk ) |
|||||||
|
|
|
j |
|
|
|
|
|
|
|
|
Здесь f(x) - сигмоидальная функция, определяемая по формуле |
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
y 1 (1 exp( Wixi |
)) |
|||||||
|
|
|
|
|
|
|
|
i |
|
|
Шаг 2. |
Минимизация функционала квадратичной ошибки сети для данного |
|||||||||
|
входного образа, имеющего вид: |
|
|
|
|
|
||||
|
|
E 1/2 (yk |
|
Yk )2 |
|
|||||
|
|
|
|
|
k |
|
|
|
|
|
|
В основе минимизации классический градиентный метод оптимиза- |
|||||||||
|
ции. Его суть состоит в итерационном уточнении аргумента со- |
|||||||||
|
гласно формуле: Vjk (t 1) Vjk (t)-h |
E |
|
|
|
|||||
|
|
|
|
|
|
Vjk |
|
|
||
|
Функция ошибки в явном виде не содержит зависимости от веса Vjk, |
|||||||||
|
поэтому воспользуемся формулами неявного дифференцирования |
|||||||||
|
сложной функции: E |
k (yk |
Yk )2 |
|
||||||
|
Vjk |
|
|
|
|
|
|
|
|
|
|
|
E |
k |
(y |
k |
Y ); |
||||
|
|
yk |
|
|
|
k |
|
|||
|
|
|
|
|
|
|
|
|
||
|
E |
E yk |
|
|
|
yk (1 yk ); |
||||
|
хk |
yk хk |
k |
|||||||
|
E |
E |
yk |
|
хk |
k yk (1 yk ) yj . |
||||
|
Vjk |
yk |
хk |
Vjk |
|
|
|
|
||
|
Здесь учтено полезное свойство сигмоидальной функции f(x): ее |
|||||||||
|
производная выражается только через само значение функции, |
|||||||||
|
f’(x)=f(1-f). Таким образом, все необходимые величины для под- |
|||||||||
|
стройки весов выходного слоя V получены. |
|||||||||
|
|
116 |
|
|
|
|
|
|
|
|

Окончание табл. 2.11
Шаг 3.
Шаг 4.
Подстройка весов скрытого слоя. Градиентный метод по-прежнему
дает: Wij (t 1) Wij (t)- |
E |
. |
|
||
|
Wij |
|
Вычисления производных выполняются по тем же формулам, за исключением некоторого усложнения формулы для ошибки α j.
|
|
|
|
E |
|
|
E yk |
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
k yk (1 yk ); |
|
|
|||||||
|
|
|
|
хk |
yk |
хk |
|
|
|||||||||||||||
E |
|
|
|
|
|
E |
|
|
хk |
k yk (1 yk ) Vjk |
|
||||||||||||
|
|
j |
|
|
yj |
|
|||||||||||||||||
Vj |
|
|
|
k |
|
|
|
хk |
|
|
|
|
k |
|
|
; |
|||||||
|
|
E |
|
|
|
E |
|
|
|
yj |
|
|
|
хj |
|
|
|
|
|||||
|
|
|
|
|
|
|
|
y (1 y ) Х |
|
||||||||||||||
|
Wij |
|
yj |
|
хj |
Wij |
|
||||||||||||||||
|
|
|
|
|
|
|
|
j j |
j |
j |
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
.
При вычислении δj частные производные берутся только по переменным последующего слоя. По полученным формулам модифицируются веса нейронов скрытого слоя. Если в нейронной сети имеется несколько скрытых слоев, процедура обратного распространения применяется последовательно для каждого из них, начиная со слоя, предшествующего выходному, и далее до слоя, следующего за входным. При этом формулы сохраняют свой вид с заменой элементов выходного слоя на элементы соотвествующего скрытого слоя.
Повторение шагов 1-3 для всех обучающих векторов. Обучение за-
вершается по достижении малой полной ошибки или максимально допустимого числа итераций, как и в методе обучения Розенблатта.
Такие вычисления проводятся для всех слоев в обратном направлении. После предъявления очередного обучающего примера он "фиксируется"
на все время прямого и обратного проходов [223-225].
Модифицируем дельта-правило (2.59) путем ввода в него нового слагаемого – момента инерции:
wji(n) wji(n 1) j(n)yi(n), |
(2.61) |
где – постоянная момента (положительное число). Как показано на рис. 2.31, она является управляющим воздействием в контуре обратной связи для w ji (n) , где z-1 – оператор единичной задержки.
Уравнение (2.61) называется обобщенным дельта-правилом. При =0 оно вырождается в обычное дельта-правило.
117
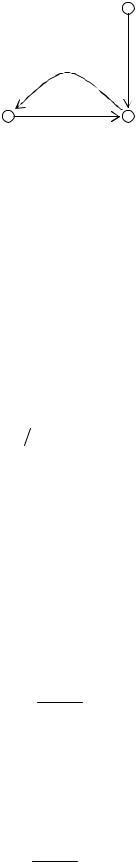
j (п)уi (п)
z-1 |
|
|
|
w ji (п 1) |
wji (п) |
Рис. 2.31. Граф прохождения сиrнала, иллюстрирующий эффект постоянной момента
Для того чтобы оценить влияние последовательности представления обучающих примеров на синаптические веса в зависимости от константы , перепишем (2.61) в виде временного ряда с индексом t. Значение индекса t будет изменяться от нуля до текущего значения п. При этом выражение (2.61) можно рассматривать как разностное уравнение первого порядка для коррекции весовwji (n). Решая это уравнение относительно wji (n), получим временной ряд
длины п + 1: |
|
|
|
|
|
wji (n) n t j (t)yi (t). |
(2.62) |
||||
Поскольку j (n)yi (n) E(n) wji (n), то выражение (2.62) можно перепи- |
|||||
сать в эквивалентной форме: |
|
E(t) |
|
|
|
wji (n) n |
n t |
. |
(2.63) |
||
|
|||||
t 0 |
|
wji (t) |
|
||
Анализ выражения (2.63) позволяет сделать ряд выводов [224]. |
|
||||
1. Текущее значение коррекции весов wji (n) |
представляет собой сумму |
||||
экспоненциально взвешенного временного ряда. Для того чтобы этот ряд сходился, постоянная момента должна находиться в диапазоне 0< <1. Если константа равна нулю, алгоритм обратного распространения работает без момента. Следует также заметить, что константа может быть и отрицательной, хотя эти значения не рекомендуется использовать на практике.
2. Если частная производная E(t) имеет один и тот же алгебраический
wji (t)
знак на нескольких последовательных итерациях, то экспоненциально взвешенная сумма wji (n) возрастает по абсолютному значению, поэтому веса wji (n)
могут изменяться на очень большую величину. Включение момента в алгоритм обратного распространения ведет к ускорению спуска в некотором постоянном направлении.
3. Если частная производная E(t) на нескольких последовательных ите-
wji (t)
118
рациях меняет знак, экспоненциально взвешенная сумма wji (n) уменьшается по абсолютной величине, поэтому веса w ji (n) изменяются на небольшую вели-
чину. Таким образом, добавление момента в алгоритм обратного распространения ведет к стабилизирующему эффекту для направлений, изменяющих знак.
Включение момента в алгоритм обратного распространения ошибок обеспечивает незначительную модификацию метода корректировки весов, оказывая положительное влияние на работу алгоритма обучения. Кроме того, слагаемое момента может предотвратить нежелательную остановку алгоритма в точке какого-либо локального минимума на поверхности ошибок.
Результаты экспериментов показали, что параметр целесообразно задавать для каждой конкретной связи ji . Это значит, что, применяя различные па-
раметры скорости обучения в разных областях сети, можно оптимизировать процедуру обучения. Кроме того, при реализации алгоритма обратного распространения ошибки можно изменять как все синаптические веса сети, так и только часть из них, оставляя остальные на время адаптации фиксированными. В последнем случае сигнал ошибки распространяется по сети в обычном порядке, однако фиксированные синаптические веса будут оставаться неизменными. Этого можно добиться, установив для соответствующих синаптических весов w ji (n) параметр интенсивности обучения ji равным нулю.
Для эффективного обучения ИНС использовался ряд эмпирических приемов, в частности: выбор размера обучающего множества; применение перекрестной проверки; использование раннего останова, применение последовательного и пакетного режимов обучения, обоснование критерия останова обучения.
При выборе размера обучающего множества учитывалось важное эмпирическое правило. Размер обучающего множества N должен удовлетворять следующему соотношению:
N = O(W/ ), |
(2.64) |
где W - общее количество свободных параметров (т.е. синаптических весов и порогов) сети; - допустимая точность ошибки классификации; О(-) - порядок заключенной в скобки величины. Например, для ошибки в 10 % количество примеров обучения должно в 10 раз превосходить количество свободных параметров сети. Выражение (2.64) получено из эмпирического правила Видроу для алгоритма LMS. Данное правило устанавливает, что время стабилизации процесса линейной адаптивной временной фильтрации примерно равно объему памяти линейного адаптивного фильтра в задаче фильтра на линии задержки с отводами, деленному на величину рассогласования [222]. Рассогласование в алгоритме LMS выступает в роли ошибки из выражения (2.64).
Суть использования перекрестной проверки состояла в следующем. Обучение методом обратного распространения заключается в кодировании отображения входа на выход (представленного множеством маркированных приме-
119
ров) в синаптических весах и пороговых значениях многослойного персептрона. Предполагается, что на примерах из прошлого сеть будет обучена настолько хорошо, что сможет обобщить их на будущее. С такой точки зрения процесс обучения обеспечивает настройку параметров сети для заданного множества данных. Более того, проблему настройки сети можно рассматривать как задачу выбора наилучшей модели из множества структур-"кандидатов" с учетом определенного критерия. Решить такую задачу возможно на основе стандартного статистического подхода, получившего название перекрестной проверки [222]. В рамках этого подхода имеющиеся в наличии данные сначала случайным образом разбиваются на обучающее множество и тестовое множество. Обучающее множество, в свою очередь, разбивается на подмножество для оценивания (используется для выбора модели) и проверочное подмножество (используется для тестирования модели). Целесообразность применения проверочного множества, отличного от оценочного, обусловлена необходимостью исключения переобученности ИНС.
Применение метода обучения с ранним остановом тесно связано с перекрестной проверкой. Обычно обучение многослойного персептрона методом обратного распространения происходит поэтапно, переходя от более простых к более сложным функциям отображения. Это объясняется тем фактом, что при нормальных условиях среднеквадратическая ошибка уменьшается по мере увеличения количества эпох обучения: она начинается с довольно больших значений, стремительно уменьшается, а затем продолжает убывать все медленнее по мере продвижения сети к локальному минимуму на поверхности ошибок. Если главной целью является хорошая способность к обобщению, то по виду кривой довольно сложно определить момент, когда следует остановить процесс обучения. Если вовремя не остановить сеанс обучения, то существенно повышается вероятность излишнего переобучения. Наступление стадии излишнего переобучения определялось с помощью перекрестной проверки, в которой данные разбиты на два подмножества — оценивания и проверки. Множество оценивания использовалось для обычного обучения сети с небольшой модификацией: сеанс обучения периодически останавливался (через каждые несколько эпох), после чего сеть тестировалась на проверочном подмножестве. Более точно, периодический процесс оценивания-тестирования выполнялся следующим образом. После завершения этапа оценивания (обучения) синаптические веса и уровни порогов многослойного персептрона фиксировались, и сеть переключалась в режим прямого прохода. Ошибка сети вычислялась для каждого примера из проверочного подмножества. После завершения тестирования наступал следующий этап процесса обучения, и все повторялось. Использовалась так называемая процедура обучения с ранним остановом. На рис. 2.32 показаны зависимости среднеквадратических ошибок от числа эпох для тестирования и обучения. Первая кривая относится к измерениям на подмножестве для оценивания, а вторая - к измерениям на проверочном подмножестве. Анализ данных функций
120