

2.4. Моделирование факторного пространства рисков и оценка воздействия
Следующий этап – определение влияния рисков на реализацию проекта строительства высотного здания. Иными словами, необходимо определить, какова величина наиболее вероятного ущерба, который будет иметь инвестор при строительстве объектов повышенной этажности, в случае наступления неблагоприятных ситуаций. Это могут быть и техногенные катастрофы, и неблагоприятные климатические условия, и инфляция, и политические протесты общества и множество других факторов, которые в конечном итоге могут существенно повлиять на доходность проекта.
Кластеры сформированы таким образом, что в кластер попадают риски независимо от природы возникновения, но приблизительно одинаковые по количественным характеристикам. Таким образом, выделены три основных кластера, которым даны новые групповые определения.
Необходимо оценить влияние каждой кластера на результат реализации проекта. Использован метод определения кластерного расстояния [98].
Для определения близости пары точек в многомерном пространстве используется евклидово расстояние
![]() I,j
= 1, …, n.
(2.10)
I,j
= 1, …, n.
(2.10)
где dij - евклидово расстояние между i-м и j-м объектами; xit, - значение i-то показателя для i-го объекта.
На основании полученных значений цены риска вычислим расстояние между каждой парой объектов по формуле (2.9), получим квадратную матрицу D, имеющую размеры nxn (по числу объектов); эта матрица симметрична, т.е. dij = dij (i,j=1,…,n).
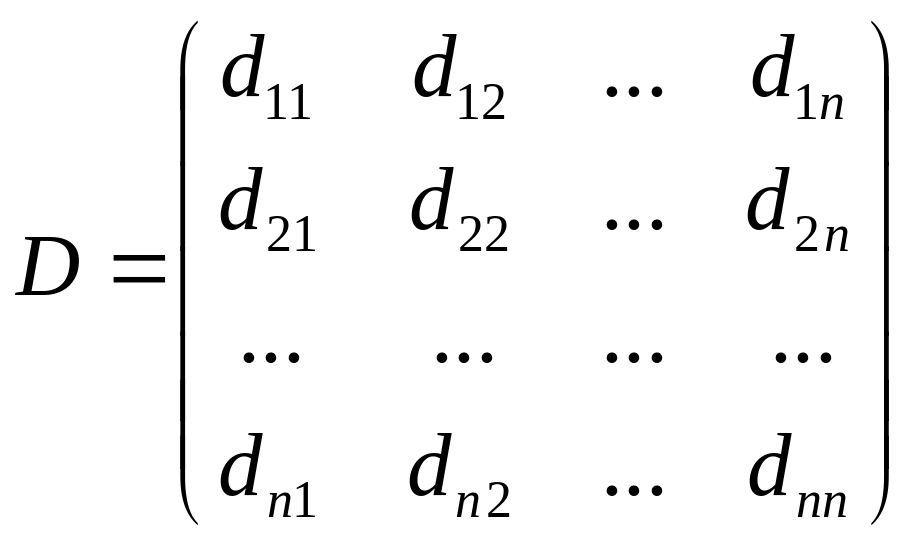 (2.11)
(2.11)
Матрица расстояний D служит основой при реализации методов кластерного анализа, в том числе и агломеративно-иерархического метода, который часто используется для многомерной классификации объектов в социально-экономических исследованиях. Основная идея этого метода заключается в последовательном объединении группируемых объектов - сначала самых близких, затем более удаленных друг от друга. Процедура построения классификации состоит из последовательности шагов, на каждом из которых производится объединение двух ближайших групп объектов (кластеров).
В результате формализуется кластер рисков, наиболее активно влияющих на прогноз доходности проекта. Все виды возможных рисков сгруппированы в кластеры по отдельным характерным признакам. Характер распределения объектов внутри каждой группы предполагает построение многомерной классификации на основе методов кластерного анализа. Такой подход позволяет идентифицировать группу рисков, наиболее существенно влияющих на прогноз развития проекта, и позволяет своевременно проработать механизм нейтрализации рисков и мер по снижению его воздействия.
Существуют различные способы определения расстояния между группами объектов (различающие методы кластерного анализа). Обычно близость двух кластеров определяется как средний квадрат расстояния между всеми такими парами объектов, где один объект пары принадлежит к одному кластеру, а другой - к другому:
![]() (2.12)
(2.12)
где Dpq - мера близости между р-м и q-м кластерами; Rp - р-й кластер; Rq - q-й кластер; nq- число объектов в p-м кластере; nq- число объектов в q -м кластере.
На первом шаге процедуры агломеративно-иерархического метода кластерного анализа рассматривается начальная матрица расстояний между объектами и по ней определяется минимальное число di1j1; далее, наиболее близкие объекты с номерами i1 и j1 объединяются в один кластер, в матрице вычеркиваются строки и столбец с номером j1 , а расстояния от нового кластера (он получает номер i1 ) до всех остальных кластеров (на первом шаге - объектов) вычисляются по формуле (2.11); в данном случае квадраты таких расстояний равны полусуммам квадратов расстояний от i1-го и j1-го объектов до каждого из остальных. Эти вновь вычисленные значения расстояний заносятся в i1-ю строку и i1-й столбец матрицы D.
На втором шаге процедуры по матрице D, содержащей уже n-1 строк и столбцов, определяют минимальное число di2j2 и формируют новый кластер с номером i2. Этот кластер может быть построен в результате объединения либо двух объектов, либо одного объекта с i1 -м кластером, построенным на первом шаге. Далее, в матрице D вычеркиваются строка столбец с номером j2, а строка и столбец с номером i2 перечитываются, и т.д.
Таким
образом, метод кластерного анализа
включает п-1
аналогичных шагов. При этом после
выполнения k-го
шага (k
![]() n-1)
число кластеров равно n-k
(некоторые из них могут быть отдельными
объектами), а матрица D имеет размеры
(n-k)x
(n-k).В
конце этой процедуры, на (n-1)-м
шагe, получится кластер, объединяющий
все n
объектов.
n-1)
число кластеров равно n-k
(некоторые из них могут быть отдельными
объектами), а матрица D имеет размеры
(n-k)x
(n-k).В
конце этой процедуры, на (n-1)-м
шагe, получится кластер, объединяющий
все n
объектов.
Результаты классификации, построенной изложенным методом, можно изобразить в виде дерева иерархической структуры (дендрограммы), содержащего n уровней, каждый из которых соответствует одному из шагов описанного процесса последовательного укрупнения кластеров.
В кластерном анализе существенным является выбор необходимого числа кластеров. В некоторых случаях число кластеров может быть выбрано из априорных соображений, однако чаще это число определяется в процессе формирования кластеров на основе значений некоторых показателей их однородности и степени удаленности друг от друга (например, показателей внутригрупповой дисперсии или вариации).
Таким образом, алгоритм решения предполагает несколько этапов. Первый этап – идентификация рисков по качественным и количественным признакам на основе кластерного анализа, что позволит группировать риски не только по источникам их возникновения, но и по вероятности возникновения и величине ущерба.
Необходимо выделить риски по степени значимости, которая предполагает максимально возможный ущерб при реализации инвестиционного проекта. Риски характеризуются вероятностью наступления и ценой риска.
Вторым этапом оценки кластеров риска предлагается измерение весового фактора или влияния их на результат реализации проекта. При анализе рисков и величине возможного ущерба от его наступления невозможно оперировать детерминированными величинами. Для более точных оценок воспользуемся задачей в стохастической постановке.
Так как случайные величины могут определяться как реализациями, так и их количественными характеристиками и законами их распределения, то на этапе планирования, как правило, неизвестны, и поэтому пользуются только характеристиками случайных величин и законами их распределения. Кроме того, говоря о рисках, необходимо учесть возможность различных временных интервалов их наступления.
Задача стохастического программирования может быть сформулирована в M- или P-постановках.
При M-постановке целевая функция, означающая максимизацию (минимизацию) математического ожидания, записывается в виде:
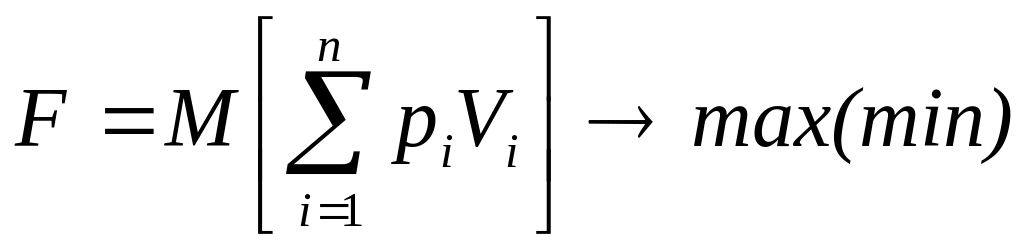 .
(2.13)
.
(2.13)
Если
от математического ожидания целевой
функции перейти к математическим
ожиданиям случайных величин
![]() ,
то получим:
,
то получим:
![]() .
(2.14)
.
(2.14)
Таким
образом, при M-постановке
задачи стохастического программирования
для ее решения требуется найти такие
значения искомых переменных
![]() ,
при которых математическое ожидание
целевой функции имеет оптимальное
(минимальное, максимальное) значение.
,
при которых математическое ожидание
целевой функции имеет оптимальное
(минимальное, максимальное) значение.
При
P-постановке
задача стохастического программирования
формулируется несколько иначе. Прежде
всего, должно быть задано предельно
допустимое наихудшее значение целевой
функции. При максимизации задается
минимально допустимое значение
![]() и требуется выполнение условия
и требуется выполнение условия
![]() .
При минимизации задается максимально
допустимое значение
.
При минимизации задается максимально
допустимое значение
![]() и требуется выполнение условия
и требуется выполнение условия
![]() .
.
Суть P-постановки заключается в том, что необходимо найти такие значения , при которых максимизируется вероятность того, целевая функция будет не хуже предельно допустимого значения.
Целевая функция при P-постановке задачи стохастического программирования имеет вид:
а) при максимизации
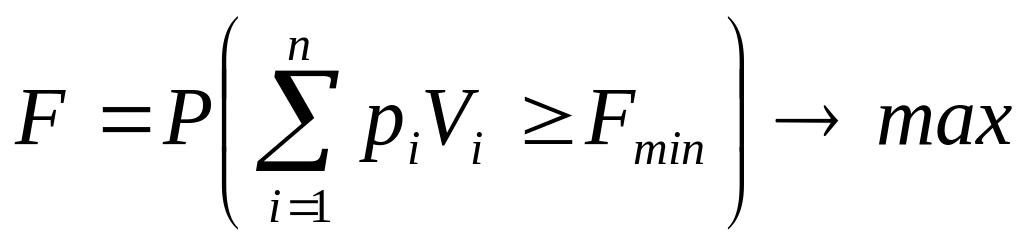 ;
(2.15)
;
(2.15)
б) при минимизации
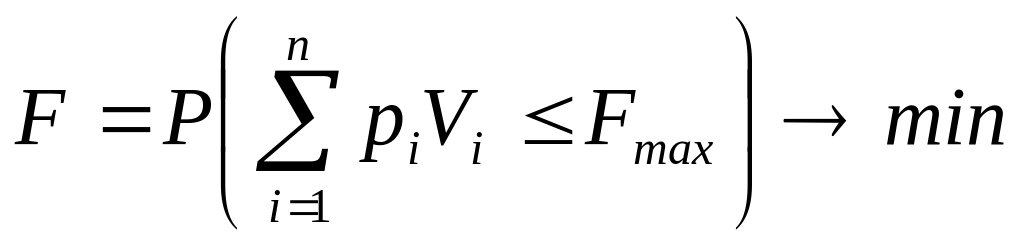 .
(2.16)
.
(2.16)
Следует отметить, что в обоих случаях, как при минимизации, так и при максимизации, целевой функции следует стремиться к максимизации вероятности.
Пусть задана некоторая конкретная область возможных значений вариации величины возможных потерь Vi, значения которых есть случайные величины, принадлежащие интервалу [0; Vmax], где значение Vmax определяется для каждого вида риска. Заданную область обозначим через . При этом необходимо выполнение условия:
![]() ,
(2.17)
,
(2.17)
где - значение i-той величины возможных потерь.
Возникает вопрос: какова вероятность наступления события A с числовым значением ? В данном случае воспользуемся понятием геометрической вероятности и вычислим ее с помощью меры Лебега [2]. Условно разобьем на n частей одинаковой меры Лебега. Пусть событие A таково, что оно целиком состоит из множества k таких частей. Тогда эксперимент случайного выбора точки из множества может быть описан с помощью классической схемы. Всего n равновозможных исходов. При этом вероятность события A равна отношению числа частей, составляющих A, к общему числу частей. Символом mes обозначим меру Лебега [2]:
P(A)
=
![]() (2.18)
(2.18)
По формуле (2.17) вычислим вероятность приближения к максимальному значению всех видов ущерба. Применяя М-постановку, найдем значения математических ожиданий:
![]() (2.19)
(2.19)
Цена риска определена как математическое ожидание события. Этот вариант оценки является наиболее точным. При этом рассмотренная модель позволит оценить интервальную вероятность. В этом случае все остальные параметры также будут иметь некоторый интервал значений. Следовательно, разработанная модель оценки рисков позволяет использовать различные методы вычисления.
На основании метода кластерного анализа определим кластерные расстояния по признаку «цена риска». Кластерные расстояния рассчитываются как евклидово расстояние (2.10). Прежде всего, определяются квадраты расстояний (табл. 2.7).
Таблица 2.7
Матрица квадратов расстояний
-
код
101
102
103
211
212
213
221
222
231
232
233
301
302
303
304
401
402
403
501
502
503
601
602
Цена риска
9,0
9,0
8,0
1,5
1,5
2,0
10,0
12,0
3,0
2,0
0,5
10,0
7,5
9,0
16,0
17,5
12,5
6,0
18,0
18,0
15,0
22,5
4,0
101
9,0
0
0
1
56,3
56,3
49
1
9
36
49
72,3
1
2,25
0
49
72,3
12,3
9
81
81
36
182
25
102
9,0
0
0
1
56,3
56,3
49
1
9
36
49
72,3
1
2,25
0
49
72,3
12,3
9
81
81
36
182
25
103
8,0
1
1
0
42,3
42,3
36
4
16
25
36
56,3
4
0,25
1
64
90,3
20,3
4
100
100
49
210
16
211
1,5
56,3
56,3
42,3
0
0
0,25
72,3
110
2,25
0,25
1
72,3
36
56,3
210
256
121
20,3
272
272
182
441
6,25
212
1,5
56,3
56,3
42,3
0
0
0,25
72,3
110
2,25
0,25
1
72,3
36
56,3
210
256
121
20,3
272
272
182
441
6,25
213
2,0
49
49
36
0,25
0,25
0
64
100
1
0
2,25
64
30,3
49
196
240
110
16
256
256
169
420
4
221
10,0
1
1
4
72,3
72,3
64
0
4
49
64
90,3
0
6,25
1
36
56,3
6,25
16
64
64
25
156
36
222
12,0
9
9
16
110
110
100
4
0
81
100
132
4
20,3
9
16
30,3
0,25
36
36
36
9
110
64
231
3,0
36
36
25
2,25
2,25
1
49
81
0
1
6,25
49
20,3
36
169
210
90,3
9
225
225
144
380
1
2
 32
322,0
49
49
36
0,25
0,25
0
64
100
1
0
2,25
64
30,3
49
196
240
110
16
256
256
169
420
4
233
0,5
72,3
72,3
56,3
1
1
2,25
90,3
132
6,25
2,25
0
90,3
49
72,3
240
289
144
30,3
306
306
210
484
12,3
301
10,0
1
1
4
72,3
72,3
64
0
4
49
64
90,3
0
6,25
1
36
56,3
6,25
16
64
64
25
156
36
302
7,5
2,25
2,25
0,25
36
36
30,3
6,25
20,3
20,3
30,3
49
6,25
0
2,25
72,3
100
25
2,25
110
110
56,3
225
12,3
303
9,0
0
0
1
56,3
56,3
49
1
9
36
49
72,3
1
2,25
0
49
72,3
12,3
9
81
81
36
182
25
304
16,0
49
49
64
210
210
196
36
16
169
196
240
36
72,3
49
0
2,25
12,3
100
4
4
1
42,3
144
401
17,5
72,3
72,3
90,3
256
256
240
56,3
30,3
210
240
289
56,3
100
72,3
2,25
0
25
132
0,25
0,25
6,25
25
182
402
12,5
12,3
12,3
20,3
121
121
110
6,25
0,25
90,3
110
144
6,25
25
12,3
12,3
25
0
42,3
30,3
30,3
6,25
100
72,3
403
6,0
9
9
4
20,3
20,3
16
16
36
9
16
30,3
16
2,25
9
100
132
42,3
0
144
144
81
272
4
501
18,0
81
81
100
272
272
256
64
36
225
256
306
64
110
81
4
0,25
30,3
144
0
0
9
20,3
196
502
18,0
81
81
100
272
272
256
64
36
225
256
306
64
110
81
4
0,25
30,3
144
0
0
9
20,3
196
503
15,0
36
36
49
182
182
169
25
9
144
169
210
25
56,3
36
1
6,25
6,25
81
9
9
0
56,3
121
601
22,5
182
182
210
441
441
420
156
110
380
420
484
156
225
182
42,3
25
100
272
20,3
20,3
56,3
0
342
602
4,0
25
25
16
6,25
6,25
4
36
64
1
4
12,3
36
12,3
25
144
182
72,3
4
196
196
121
342
0


Таким образом, получена симметричная матрица. Подсчитав значения коэффициентов dij или Sij для всех пар объектов, получили квадратную матрицу размером nxn аналогичную матрице расстояний D (и также симметричную), которую далее можно анализировать с помощью какого-либо метода автоматической классификации.
Минимизация среднего расстояния между кластерами, которая производится на каждом шаге, эквивалентна минимизации некоторого критерия качества классификации, оценивающего степень однородности формируемых кластеров.
Для удобства проведения дальнейших процедур переформатируем табл. 2.7 таким образом, чтобы группировка кластеров просматривалась наиболее явно (табл.2.8).
Таблица 2.8
Кластеры рисков
-
код
233
211
212
213
232
231
602
403
302
103
101
102
303
221
301
222
402
503
304
401
501
502
601
№ кластера
1
2
3
№ кластера
Цена риска
0,5
1,5
1,5
2,0
2,0
3,0
4,0
6,0
7,5
8,0
9,0
9,0
9,0
10,0
10,0
12,0
12,5
15,0
16,0
17,5
18,0
18,0
22,5
233
1
0,5
0
1
1
2,25
2,25
6,25
12,3
30,3
49
56,3
72,3
72,3
72,3
90,3
90,3
132
144
210
240
289
306
306
484
211
1,5
1
0
0
0,25
0,25
2,25
6,25
20,3
36
42,3
56,3
56,3
56,3
72,3
72,3
110
121
182
210
256
272
272
441
212
1,5
1
0
0
0,25
0,25
2,25
6,25
20,3
36
42,3
56,3
56,3
56,3
72,3
72,3
110
121
182
210
256
272
272
441
213
2,0
2,25
0,25
0,25
0
0
1
4
16
30,3
36
49
49
49
64
64
100
110
169
196
240
256
256
420
232
2,0
2,25
0,25
0,25
0
0
1
4
16
30,3
36
49
49
49
64
64
100
110
169
196
240
256
256
420
231
3,0
6,25
2,25
2,25
1
1
0
1
9
20,3
25
36
36
36
49
49
81
90,3
144
169
210
225
225
380
602
4,0
12,3
6,25
6,25
4
4
1
0
4
12,3
16
25
25
25
36
36
64
72,3
121
144
182
196
196
342
403
6,0
30,3
20,3
20,3
16
16
9
4
0
2,25
4
9
9
9
16
16
36
42,3
81
100
132
144
144
272
3
 02
027,5
49
36
36
30,3
30,3
20,3
12,3
2,25
0
0,25
2,25
2,25
2,25
6,25
6,25
20,3
25
56,3
72,3
100
110
110
225
103
2
8,0
56,3
42,3
42,3
36
36
25
16
4
0,25
0
1
1
1
4
4
16
20,3
49
64
90,3
100
100
210
101
9,0
72,3
56,3
56,3
49
49
36
25
9
2,25
1
0
0
0
1
1
9
12,3
36
49
72,3
81
81
182
102
9,0
72,3
56,3
56,3
49
49
36
25
9
2,25
1
0
0
0
1
1
9
12,3
36
49
72,3
81
81
182
303
9,0
72,3
56,3
56,3
49
49
36
25
9
2,25
1
0
0
0
1
1
9
12,3
36
49
72,3
81
81
182
221
10,0
90,3
72,3
72,3
64
64
49
36
16
6,25
4
1
1
1
0
0
4
6,25
25
36
56,3
64
64
156
301
10,0
90,3
72,3
72,3
64
64
49
36
16
6,25
4
1
1
1
0
0
4
6,25
25
36
56,3
64
64
156
222
12,0
132
110
110
100
100
81
64
36
20,3
16
9
9
9
4
4
0
0,25
9
16
30,3
36
36
110
402
12,5
144
121
121
110
110
90,3
72,3
42,3
25
20,3
12,3
12,3
12,3
6,25
6,25
0,25
0
6,25
12,3
25
30,3
30,3
100
503
15,0
210
182
182
169
169
144
121
81
56,3
49
36
36
36
25
25
9
6,25
0
1
6,25
9
9
56,3
304
3
16,0
240
210
210
196
196
169
144
100
72,3
64
49
49
49
36
36
16
12,3
1
0
2,25
4
4
42,3
401
17,5
289
256
256
240
240
210
182
132
100
90,3
72,3
72,3
72,3
56,3
56,3
30,3
25
6,25
2,25
0
0,25
0,25
25
501
18,0
306
272
272
256
256
225
196
144
110
100
81
81
81
64
64
36
30,3
9
4
0,25
0
0
20,3
502
18,0
306
272
272
256
256
225
196
144
110
100
81
81
81
64
64
36
30,3
9
4
0,25
0
0
20,3
601
22,5
484
441
441
420
420
380
342
272
225
210
182
182
182
156
156
110
100
56,3
42,3
25
20,3
20,3
0
Определим расстояние между кластерами и построим соответствующую матрицу (табл.2.9).
Таблица 2.9
Матрица кластерных расстояний
Наименование кластеров |
Консервативный |
Умеренный |
Агрессивный |
Консервативный (1) |
0 |
23,2 |
34,5 |
Умеренный (2) |
23,2 |
0 |
24,6 |
Агрессивный (3) |
34,5 |
24,6 |
0 |
Получен «треугольник рисков», который графически представлен на рис. 2.4.
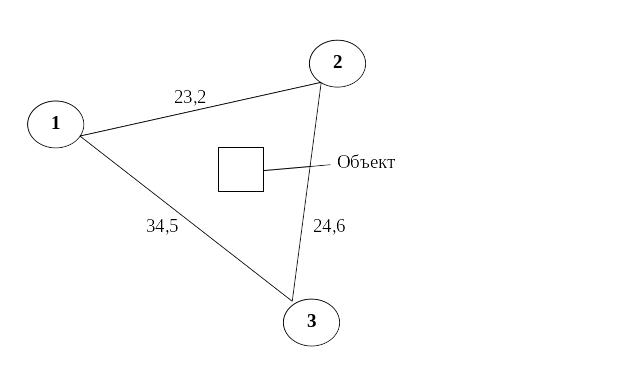
Рис. 2.4. «Треугольник рисков».
Геометрическая интерпретация ситуации рисков, представленная на рис. 2.9, трактуется следующим образом. Объект находится в центре тяжести треугольника. Как известно, центр тяжести или центр масс – это точка пересечения медиан треугольника. Степень влияния каждого кластера рисков (вершины треугольника) определена геометрически как 2/3 медианы.
Кластеры рисков сформированы по признаку цены рисков, то есть величины ожидаемых потерь от наступления риска с учетом вероятности и максимального ущерба. Расстояние между кластерами, соответственно, также выражено в единицах цены риска.
Если расстояние между вершинами треугольника будет увеличиваться, следовательно, цена риска будет расти. Для определения степени влияния кластеров рисков на объект необходимо определить длины медиан треуголика (рис 2.5).
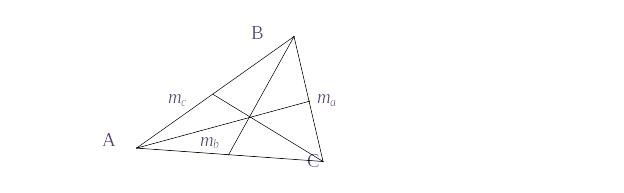
Рис. 2.5. Геометрическая интерпретация рисков.
Определим длины медиан треугольника.
![]() (2.20)
(2.20)
![]() (2.21)
(2.21)
![]() (2.22)
(2.22)
Для кластера рисков:
![]()
![]()
![]()
Центр тяжести треугольника находится на пересечении медиан, причем медианы в этой точке имеют отношение 2:1. Следовательно, степень влияния кластера рисков Rki на объект можно определить как 2/3 длины медианы соответствующей кластерной вершины:
Rk1 = 226,7/3 = 17,8; Rk2 = 216,6/3 = 11,04; Rk3 = 227,6/3 = 18,4.
Таким образом, определена цена кластерных рисков и выявлены степени их влияния на реализацию объекта. Несмотря на то, что кластеры представляю три группы рисков (консервативные, умеренные и агрессивные) согласно разработанной классификации, степени влияния различаются незначительно. Это происходит в силу того, что вероятность возникновения риска с высоким уровнем ущерба, как правило, намного ниже, чем вероятность возникновения консервативных рисков с незначительным возможным ущербом. Следовательно, происходит «нивелирование» цены риска, и в результате кластерные группы рисков оказывают на объект практически равное воздействие.
Оценка рисков позволяет не только оценить величину возможного ущерба с наибольшей вероятностью, но и принять меры по нейтрализации рисков. Например, в сейсмоактивных зонах, где вероятность землетрясений высока, здания и сооружения строятся с использованием более прочных конструкций.
Таким образом, на основании предложенной модели проведена идентификация рисков, группировка их в кластеры с целью выделить наиболее значимые, а также проведена оценка их влияния на условия реализации проекта.