


188 Глава 15 • Переполнение буфера
выполнения таких задач предусмотрен suid, что позволяет программе выполняться с заданным набором привилегий, который может отличаться от привилегий вызвавшего эту программу пользователя.
Такие файлы являются хорошей целью для атакующего. Также на компьютерах есть программы с расширенными привилегиями, запускающиеся в момент запуска ОС. В Windows это сервисы, а в Unix — так называемые демоны. Наличие расширенных привилегий и доступность (стандартные демоны и сервисы всегда присутствуют на компьютере жертвы и всегда запущены) делают их основной и наилучшей целью для атакующего.
Итак, основной целью атакующего является использование возможности переполнения буфера программы, обладающей повышенными привилегиями, для выполнения своего кода на машине жертвы.
Основы компьютерной архитектуры
Исходя из классической модели фон Неймана, компьютер состоит из:
арифметико-логического устройства (АЛУ), занимающегося обработкой данных;
памяти, каждая ячейка которой пронумерована, а нумерация начинается с 0 (ее можно разделить на энергозависимую оперативную память и энергонезависимую — жесткий диск);
устройства управления;устройства ввода и вывода (клавиатура, сетевой интерфейс, принтер и т. д.).
АЛУ (англ. CPU) обычно называют процессором, оно содержит набор регистров, предназначенных для манипуляции с данными и их обработки. Каждый регистр имеет указатель инструкции (instruction pointer, IP), необходимый для отслеживания выполнения программой инструкций и содержащий адрес следующей инструкции, которую необходимо выполнить. Указатель — в основном запись, содержащая адрес сегмента памяти.
Наименьшее количество информации, которое компьютер может обработать, называется битом. Но работа с битами не является эффективной. Для оптимизации работы компьютера был разработан тип данных, называемый словом (word). В настоящее время слово имеет размер в 32 бита, а процессор, умеющий работать со словом размером в 64 бита, был изобретен еще в далеком 1993 году.
Организация памяти
После того как к программе подключились необходимые библиотеки, она была скомпилирована и запущена, все ее компоненты размещаются в различных сегментах памяти компьютера.
|
Атаки, направленные на переполнение буфера 189 |
||
4G ( |
В а а |
|
а а |
|
|||
а |
|
|
|
32 ) |
0 ffffffff |
|
|
|
|
С (stack) |
|
|
|
Х • (heap) |
|
|
|
|
Н - € а ‚ ƒ а-- |
exec а |
|
|
|
а-- (bss) |
а |
|
|
|
И- € а ‚ ƒ а-- |
exec а |
|
|
|
а-- (data) |
||
|
|
|
а |
|
0 |
Н а а |
Т (code) |
||
|
||||
|
0 00000000 |
|
|
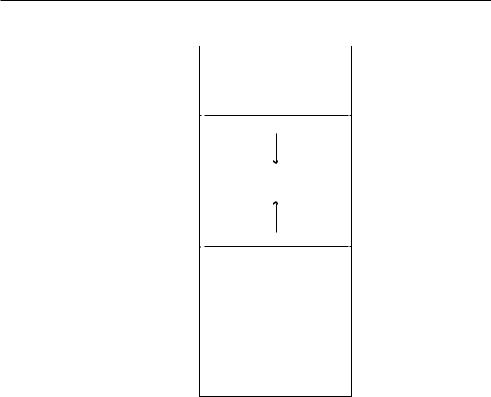
Рис. 15.1. Структурная схема организации памяти
Область памяти для программ, написанных на языке C, выглядит следующим образом.
1.Текстовый сегмент
Текстовый сегмент, кодовый сегмент или просто текст — одна из частей программы в памяти компьютера. Она содержит набор исполняемых инструкций. Обычно помечается атрибутом «только для чтения». Текстовый сегмент памяти может быть доступен и другим приложениям. Это сделано для того, чтобы не создавать множества копий одного и того же часто используемого кода.
Данный сегмент не является целью атакующего, так как любая попытка записать в него какую-либо информацию приведет к аварийному завершению программы.
В памяти текстовый сегмент может быть расположен ниже или выше областей динамически распределяемой памяти (хипа) и стека.
2.Инициализируемый сегмент данных
Инициализируемый сегмент данных, или просто сегмент данных, хранит в себе блок виртуальных адресных пространств, содержащих глобальные переменные, которые задает программист.

190 Глава 15 • Переполнение буфера
Данная область памяти может быть перезаписана во время выполнения программы. Но программист может создавать сегменты, доступные в режиме «только для чтения».
3.Сегмент неинициализированных данных
Сегмент неинициализированных данных, часто называемый BSS (block started by symbol). Этот сегмент выделяется ядром ОС, и все данные в нем обнуляются перед запуском программы.
4.Стек
Область стека традиционно граничит с хипом и заполняется в противоположном направлении. Когда область стека достигает хипа, это означает, что свободной памяти не осталось.
Эта область содержит программный стек типа LIFO (last in first out) и располагается в более высоких областях памяти. Это означает, что получить доступ можно только к первому элементу в «голове» очереди. В архитектурах х86 адресация начинается с нуля, в других реализациях адресация может двигаться в противоположном направлении.
ВАЛУ существует специальный регистр SP (stack pointer), хранящий информацию об элементе, который находится в начале, «голове» очереди.
Встеке хранятся локальные переменные, а также связанная с ними информация.
5.Хип
Хип — это область динамически распределяемой памяти. Область хип управляется такими операторами, как malloc() (memory allocation), realloc() и free(). Malloc() позволяет программисту запрашивать у ОС необходимое количество памяти для хранения данных, например область величиной 5000 символов, с целью записать туда предоставленный пользователем адрес веб-страницы. Одной из особенностей оператора malloc() является то, что он может возвращать самый низший из доступных для записи адресов ячейки памяти, а иначе откуда бы мы знали, куда заносить данные? Адрес такой ячейки содержится в специальной переменной, именуемой указателем (pointer). Free() — освобождает память и возвращает ОС управление ею.
Область хип совместно используется различными библиотеками и динамически подключаемыми модулями.
Разбиение стека (Smashing the stack)
Для того чтобы понять основы разбиения стека, нам необходимо разобраться в том, что происходит в случае, когда одна функция вызывает другую.
Атаки, направленные на переполнение буфера 191
Для примера возьмем часть программы my_func(param1, param2, ..., paramn),
которая использует локальные переменные var1, var2, ... , varm и некоторый набор, необходимый для занесения в param1, param2, ..., paramn.
Перед выполнением программы стек будет выглядеть следующим образом:
В |
|
|
|
|
Р |
|
а а |
|
|
|
|
|
|
X |
|
|
|
BP |
|
|
|
|
|
IP |
Z |
||
|
|
|
SP Y
BP X
Y |
|
SP |
|
Н
а а
Рис. 15.2. Стек перед вызовом функции
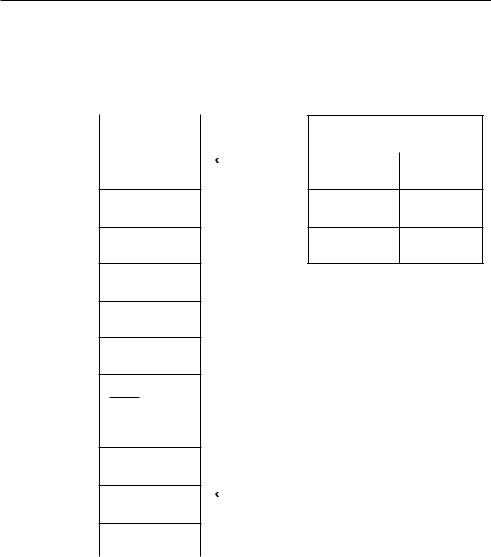
Указатель стека SP будет содержать адрес верхушки стека (Y), указатель инструкций IP будет содержать информацию о следующей инструкции, которая должна будет выполняться АЛУ (Z). В нашем случае данные указатели подготавливают все необходимое для выполнения функции my_func().
Как мы уже упоминали выше, стек используется для хранения локальных переменных, но на самом деле он содержит более развернутую информацию. В действительности в стек помещается весь контекст, необходимый для работы функции, включая параметры ее вызова. Вся область памяти, выделенная под выполнение функции, называется стековым фреймом.
Также процессору необходимо каким-то образом ориентироваться в стековом фрейме. Одним из самых разумных способов для этого является выделение фиксированного адреса для каждого стекового фрейма. Указатель на этот адрес содержится в указателе фрейма — BP (base pointer или frame pointer).
Вернемся к вызову my_func(). Первое, что происходит при вызове, — это передача данных для параметров param1, param2, ..., paramn. Данные будут передаваться в обратном порядке от paramn к param1.
192 Глава 15 • Переполнение буфера
После вызова функции и передачи параметров нам необходимо выполнить саму функцию. Для того чтобы это произошло, нам надо добавить в стек адрес инструкции (V), которая должна быть выполнена процессором.
|
|
|
|
|
Р |
|
X |
|
|
|
BP |
|
|
|
|
|
IP |
U |
||
|
|
|
SP W
BP X
Y
paramn
param1
W |
V |
|
SP |
Рис. 15.3. Стек после занесения параметров и адреса возврата
Следующая инструкция, находящаяся по адресу U, является точкой вызова my_ func(). По факту в этой ячейке содержится адрес, взятый из регистра IP и указывающий на первую инструкцию, которая должна быть выполнена.
На этом этапе завершается подготовка к исполнению my_func(). Но прежде чем это произойдет, должны быть соблюдены следующие требования:
1.Предыдущее значение указателя фрейма (BP) должно быть сохранено и занесено в стек. Это необходимо для того, чтобы впоследствии мы могли вернуться на ту точку, на которой находились до выполнения функции.
Атаки, направленные на переполнение буфера 193
2.В указатель фрейма (BP) копируется значение указателя стека (SP), которое указывало на указатель фрейма.
3.Путем перемещения указателя стека вниз резервируется место для локальных переменных var1, var2, ... , varm.
Первые два шага выполняются для любых функций одними и теми же инструментами, машинным кодом или инструкциями. Третий шаг отличается только количеством места, которое необходимо выделить для хранения переменных.
Эти три шага, являющиеся общими и одинаковыми для вызова любых функций, называются прологом (prolog) функции.
X
Y
paramn
param1
WV
W’ |
X |
|
BP |
|
var1
Р
IP S
SP T
BP W’
func()_my а Ф
T
varm
SP
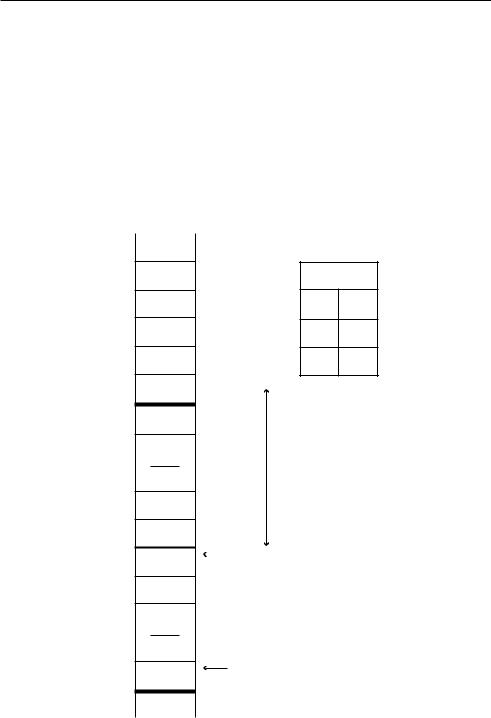
Рис. 15.4. Вид стека после выполнения пролога функции

194 Глава 15 • Переполнение буфера
Регистр IP содержит адрес S, указывающий на первую «реальную» инструкцию функции, которая должна быть выполнена. Регистр B содержит адрес ячейки W’, данный адрес может быть представлен в виде: адрес W минус общая сумма байтов в слове.
Можно заметить, что параметры и локальные переменные функции расположены в памяти симметрично, над и под регистром BP. Как следствие, по отношению к BP адреса параметров будут возрастать, а адреса локальных переменных — уменьшаться.
Как вы могли догадаться, поскольку у функции есть пролог, то должен быть и эпилог. Эпилог (epilog) необходим, чтобы «прибрать за собой» после того, как функция выполнит свою работу.
Это также произойдет в три шага:
1.Значение регистра W’, в котором находится копия адреса BP, будет присвоено SP. Это позволит избавиться от локальных переменных.
2.Назад в ВР копируется Х — сохраненное значение указателя фрейма (выполняется командой «pop», так как SP указывает на адрес стека, содержащего нужное значение). Сравнивая рис. 15.3 и 15.5, а также пренебрегая возможностью изменения значений параметров и переменных, можно увидеть, что стек стал выглядеть так же, как до выполнения пролога функции. Единственная разница в том, что указатель инструкций теперь содержит адрес R.
3.R указывает на другую «pop» операцию, которая скопирует адрес возврата V назад, в указатель инструкции.
Инструкция по адресу V переместит указатель стека вверх на такое количество адресов, на какое оно было увеличено до вызова функции, во время добавления в буфер параметров param1, param2, ..., paramn. Теперь мы получили такое же состояние буфера, показанное на рис. 15.2, как и до вызова функции.
Пока все выглядит хорошо, так где же возникнет проблема, а вместе с ней и уязвимость?
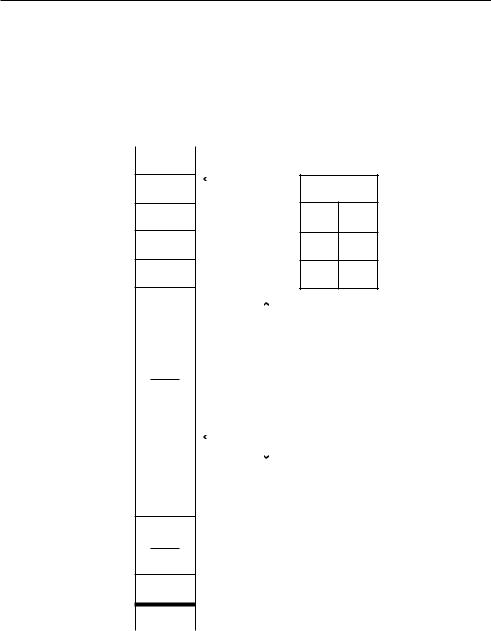
Представьте, что одна из вполне обычных и безобидных переменных var1, var2, ..., varm может оказаться чем угодно, информацией любого типа. По определению ячейки буфера расположены в памяти таким образом, что первая из них будет иметь наименьший адрес. То есть адреса буфера растут по направлению к наибольшему адресу.
Предположим, что программа не проверяет введенную пользователем строку на количество символов, а она оказалась больше зарезервированного под нее места в памяти. Теперь, если строка не является последним параметром, то вначале излишком символов будут перезаписаны все переменные, находящиеся после нее. А затем оставшаяся часть строки перезапишет значения указателя фрейма и адрес возврата, на который должен вернуться указатель после выполнения эпилога функции. Все это открывает для нас интересные возможности! Предположим, что мы
Атаки, направленные на переполнение буфера 195
подадим на вход программы строку, сформированную таким образом, чтобы она переписала адрес возврата на тот, в котором уже находится тщательно сформированный вредоносный код. Данный код может находиться там до или после адреса возврата. Если сделать все правильно, то после выполнения эпилога функции компьютер перейдет по подделанному адресу и выполнит вредоносный код.
X |
|
BP |
Р |
|
IP R
SP W
BP X
Y |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
paramn |
|
|
|
my а Ф |
|
|
|
|
|
|
|
|
||||
|
param1 |
|
|
|
func() |
|
|
|
|
|
|
|
|
|
|
SP |
|
W |
V |
|
|
|
|
|
|
||||
|
|
|
|
|
|
W’ |
X |
|
|
|
|
|
|
|
|
|
|
|
var1 |
|
|
|
|
T
varm
Рис. 15.5. Вид стека после шага 2 эпилога функции
В Unix-подобных системах самым популярным видом кода у злоумышленников является шелл-код. Шелл в Unix — это программная оболочка, которая представляет собой интерфейс для командной строки. По умолчанию в большинстве систем используется командный интерпретатор Борна (Bourne Shell), находящийся в директории /bin/sh. Целью сформированного злоумышленником шелл-кода является

196 Глава 15 • Переполнение буфера
запуск интерпретатора из директории /bin/sh. Это поможет атакующему получить доступ к интерфейсу, в котором он сможет выполнять любые команды от имени пользователя, запустившего подвергнувшуюся взлому программу.
X
Y
S
W
W’
T
В •
S
П • •
varm
BP |
Р |
|
|
|
|
|
IP |
P |
|
|
|
|
SP |
T |
|
|
|
|
BP |
W’ |
П а • а а
BP
На•а • -а
SP
Рис. 15.6. Состояние стека после переполнения буфера
Примеры такого шелл-кода можно найти в Интернете. Главное его преимущество — это размер, обычно он содержит не более 60 байт! Это очень важно, так как защищает атакующего во время выполнения переполнения буфера от выхода сформированного кода за пределы отведенной программе памяти.
Для атак на ПО, работающее под управлением ОС Windows, также используется шелл-код, но под этим подразумевается нечто иное. Одна из проблем при удален-

Атаки, направленные на переполнение буфера 197
ном переполнении буфера win32-систем заключается в использовании классического метода, когда необходимо заставить машину жертвы скачать файл из сети и выполнить его.
Наверное, это происходит из-за того, что большинство посвященных информационной безопасности руководств освещает именной такой метод атаки. Однако, как показывает практика, шелл-код для Windows может работать по такому же принципу, как и для Unix.
Даже в случае если ваш шелл-код предоставит вам после удачной атаки доступ к командной строке жертвы, имеющей контекст взломанной программы, всегда существуют препятствия для выполнения направленной на переполнение буфера атаки.
К таким препятствиям относятся:
1.Необходимость угадать значение, которое нужно поместить в подделанный адрес возврата.
2.Необходимость угадать местонахождение адреса возврата в стеке (в нашем случае W).
3.Необходимость убедиться в том, что шелл-код не содержит нулей, так как это приведет к немедленной остановке его выполнения.
Первая и вторая проблемы обычно встречаются одновременно. Основным способом их преодоления является:
1.Использование NOP (No Operation)-инструкций. Такая инструкция не делает ничего и ставится перед шелл-кодом.
2.В сформированном коде, используемом для направленной на переполнение буфера атаки, следует повторять несколько раз предполагаемый начальный адрес.
Ш-
NOP
NOP
…
NOP
На а а
На а а
На а а
Рис. 15.7. Состояние памяти во время направленной на переполнение буфера атаки