

3.4.12. Доменно-ключевая нормальная форма
Отношение находится в ДКНФ, если оно не имеет аномалий модификации.
Другими словами, что бы ни менялось — ничего не потеряется, если соблюдены все ограничения относительно ключей и доменов.
На примере эти правила действуют примерно так: нельзя просто удалить категорию из таблицы категорий, если с этой категорией связаны, например, продукты из таблицы продуктов. Прежде чем удалять категорию, необходимо выполнить предварительные действия в таблице продуктов (например, поле отвечающее за ID категории этого товара нужно сделать NULL).
3.4.13. Ещё раз, кратко, все нормальные формы
1НФ - все атрибуты отношения атомарны;
2НФ - отношение находится в 1НФ и не содержит частичных ФЗ;
3НФ - отношение находится во 2НФ и не содержит транзитивных ФЗ от ключа;
НФБК - отношение находится в 3НФ и не содержит ФЗ ключей от неключевых атрибутов;
4НФ, применяется при наличии более чем одной многозначной ФЗ - отношение находится в НФБК или 3НФ и не содержит многозначных ФЗ;
5НФ - отношение находится в 4НФ и удовлетворяет зависимости по соединению относительно своих проекций.
ДКНФ - отношение не имеет аномалий модификации.
3.4.14. Ещё раз, кратко, в ErWin
Шаг 0. Ужасное отношение.
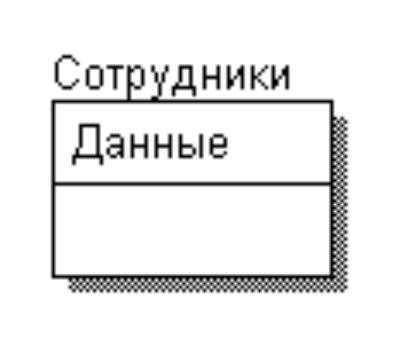
Рисунок 3.4.14.1 – Ужасное отношение
Шаг 1. 1НФ: делаем атрибуты атомарными
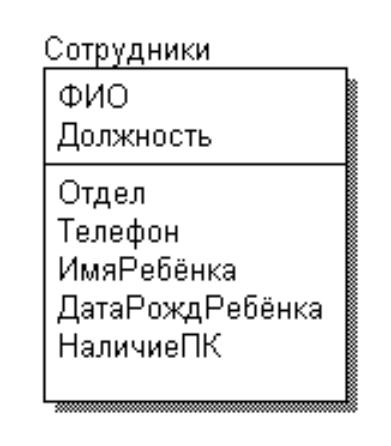
Рисунок 3.4.14.2 – Отношение в 1НФ
Шаг 2. 2НФ: убираем частичные ФЗ
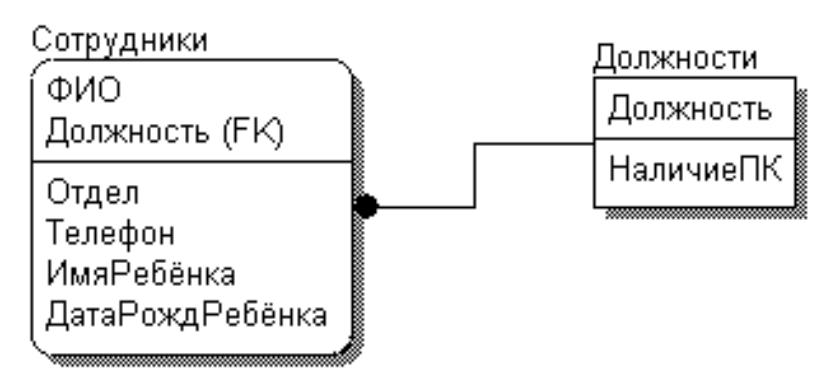
Рисунок 3.4.14.3 – Отношения во 2НФ
Шаг 3. 3НФ: убираем транзитивные ФЗ
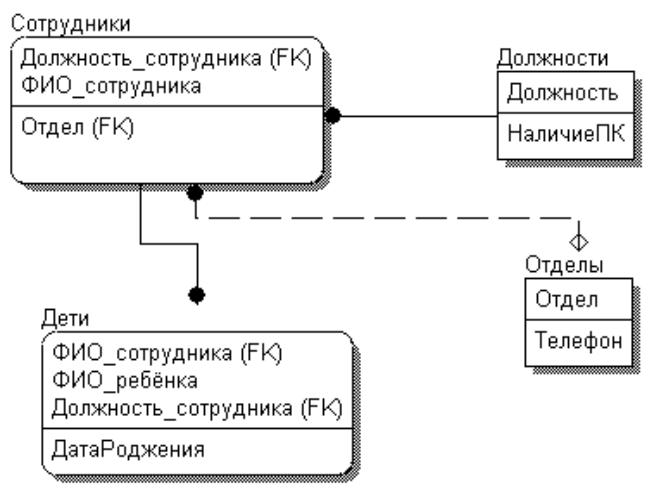
Рисунок 3.4.14.4 – Отношения в 3НФ
Шаг 4. Приводим к удобной для реальной работы форме…
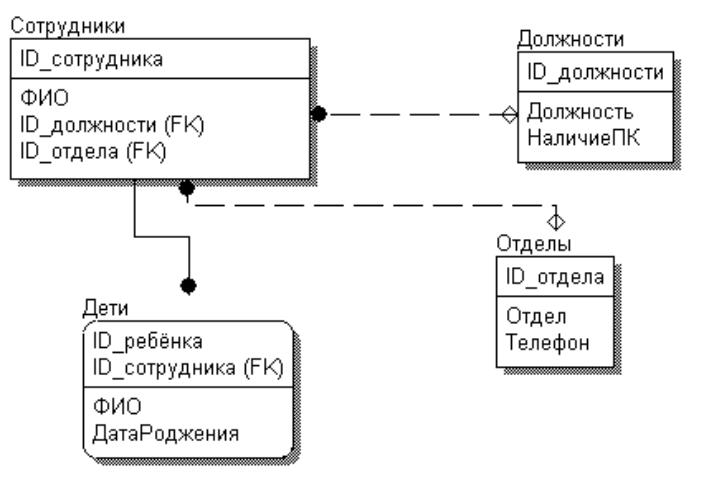
Рисунок 3.4.14.5 – Итоговый вид схемы БД
3.4.15. Обратное проектирование бд
Об обратном проектировании БД мы скажем всего два слова: оно сводится к построению схемы БД на основе существующей БД. Это можно сделать вручную или (лучше) с помощью специальных инструментальных средств.
После построения такой схемы с ней можно (иногда – нужно) выполнить все только что рассмотренные операции.
Когда схема «приведена в норму», её можно дорабатывать, т.е. заниматься прямым проектированием БД.
3.4.16. Итог
На этом мы заканчиваем рассмотрение теоретических основ работы с базами данных.
У нас осталась только одна тема в этом разделе – посвящённая качеству БД.
3.5. Повышение качества бд на стадии проектирования
3.5.1. Памятки разработчикам бд
Поскольку в первую очередь качество результата разработки любого проекта зависит от процесса разработки, рассмотрим несколько памяток, которые помогут этот процесс улучшить…
(На основе текста «10 заповедей разработчика» by Виноградов С.А.)
Здесь перечислены общие рекомендации по избежанию наиболее распространённых ошибок, совершаемых начинающими разработчиками БД.
Нарушение перечисленных рекомендаций, как правило, приводит к резкому увеличению времени разработки, росту количества ошибок, неоправданным сложностям в сопровождении и в конечном итоге, к провалу всего проекта.
Памятка 1. Стандартные имена или «не перегружайте никому мозги»
Одной сущности должно соответствовать всегда одно имя – это правило, в котором не может быть исключений.
Написание имён должно быть максимально стандартизировано. Регистр букв также важен, даже если средство разработки его не учитывает (зато регистр хорошо учитывается людьми).
Лучше всего использовать слова английского языка без сокращений. Большинство средства разработки не поддерживает идентификаторы, состоящие из букв других языков – и правильно делает.
Немногочисленные стандартные аббревиатуры и сокращения должны быть описаны в специальном словаре.
Пример: если типу объекта соответствует имя ObjectType, то в обращении не должно быть имён вида ObjType, Objecttype или OBJ_TYPE.
Использование стандартных имён позволяет сэкономить много времени, необходимого на поиск нужного имени, а также избежать возможных недоразумений.
Памятка 2. Отсутствие загадочных значений или «что это такое?»
Часто неопытные разработчики используют некоторые поля для хранения значений вроде 0, 1, 2 и т.п.
Эти поля не ссылаются на другую таблицу, зато используются где-нибудь в выражениях: if State = 2 then ... else ... Всё ведь понятно, не правда ли?
Немногим лучше выглядит и такой вариант: <U>, <T>, <S>. Кто угадает, что здесь означает <U>?
Правильным решением будет создание отдельной таблицы (Id, Code, Name, Note), содержащей набор возможных значений для этого поля.
В поле же надо хранить идентификатор (Id) значения из этой таблицы, при необходимости используя код и наименование значения.
Отсутствие загадочных значений освобождает память разработчика от ненужного мусора и уменьшает вероятность возникновения ошибок и непонимания.
Памятка 3. Поменьше ограничений или «не создавайте граблей на пустом месте»
Таблицы и поля стоит создавать с достаточно большим «запасом прочности», чтобы не было потом мучительно больно.
Если в задании написано, что какой-нибудь код содержит 17 символов, совсем необязательно понимать это буквально и объявлять поле как char(17).
Ведь завтра требования могут измениться, и уже понадобится 22 символа или больше. Гораздо лучше выглядит varchar(120), а места оно занимает не больше.
Когда создаётся таблица с предполагаемым числом записей не больше нескольких тысяч, вполне разумным кажется использование smallint (2-хбайтовое целое) поля в качестве первичного ключа.
А что же будет, если количество записей всё-таки превысит 32 тысячи? Придется менять первичный ключ в этой таблице и все внешние ключи, ссылающиеся на неё. Этого можно было бы избежать, сразу сделав первичный ключ размером в 4 байта.
Кажется, что всегда можно легко произвести любые необходимые изменения в структуре базы данных, однако это далеко не так. База может находиться в круглосуточной работе, в репликации, может быть уже заполненной многогигабайтными данными и т.п. И экономия на байтах здесь не уместна.
Отсутствие мелочных ограничений позволяет разработчику не думать о них и создавать более устойчивые и гибкие структуры.
Памятка 4. Одинаковые ключи или «надо быть проще»
В качестве первичных ключей для всех таблиц сущностей лучше всего использовать суррогатные ключи достаточно большого размера (4-16 байт).
При этом, все такие ключи должны быть одного типа. Благодаря этому, многие проблемы уходят и никогда не возвращаются.
Так как ключ суррогатный, то отпадает необходимость поиска и использования естественного ключа (часто – составного).
Из-за большого размера ключа не возникает ситуация его переполнения. Наличие у всех сущностей идентификатора одного типа позволяет организовать стандартную работу с этими сущностями.
Единственной проблемой может стать наличие двусторонней репликации между базами данных. Но это легко решается использованием глобального идентификатора в качестве ключа либо разделением диапазонов выделенных для ключей в разных БД.
Одинаковые ключи дают возможность работать с разными сущностями одинаковыми методами, часто используя один и тот же код.
Памятка 5. Независимость данных или «надо быть гибче»
Нормализация и ещё раз нормализация – вот залог жизнеспособности любой базы данных.
Как учат классики, все отдельные сущности должны быть выделены в отдельные таблицы. При этом связь с ними осуществляется по первичному ключу.
Одинаковые сущности, наоборот, сводятся в одну таблицу.
Зависимости между разными сущностями должны быть минимальны.
Из-за несовершенства SQL (и особенно его реализаций), полностью нормализованная БД может оказаться плохо приспособленной к получению сложных запросов. Поэтому, в исключительных случаях, допускается некоторое дублирование информации для ускорения выборок.
Независимость отдельных сущностей может упростить проект и добавить ему гибкости.
Памятка 6. Неповторяющийся код или «долой Copy&Paste!»
Казалось бы, тривиальное правило, гласящее, что повторяющийся код надо выносить в отдельные функции, знает даже самый неграмотный программист.
Однако в случае с SQL всё не так просто. Дело в том, что SQL изначально не предназначен для создания функций, процедур, триггеров и, соответственно, не предполагает для них никакого стандарта.
Поэтому у всех SQL-серверов есть свои собственные расширения для написания бизнес-логики. Эти расширения не совместимы друг с другом, а их уровень варьируется от достаточно высокого до совершенно убогого (лишь бы было).
Иногда даже опытные разработчики, впервые столкнувшись с неадекватными SQL-расширениями, впадают в какой-то ступор и забывают все свои навыки, пытаясь использовать навязанные им приемы работы.
При этом, часто пишут кучу однообразных триггеров и процедур, выполняющих одинаковые действия для разных таблиц. Тем не менее, правило повторного использования кода никто ещё не отменял, и обычно его везде можно применять, хотя и не всегда очевидным образом (например, передавая имя таблицы в качестве параметра).
Повторное использование улучшает качество кода и рекомендуется к применению везде, даже если средство разработки этого не поощряет.
Памятка 7. Обработка ошибок или «Invalid programmer is detected. Abort, Remove?»
Такое же стандартное правило, как и предыдущее – если хочешь, чтобы программа делала то, что нужно, необходимо проверять результат выполнения каждой функции (и каждого SQL-оператора).
В клиентском приложении должны везде проверяться коды ошибок вызываемых функций. При возникновении ошибки, её стоит записать в лог-файл, а пользователю должно быть показано уже обработанное внятное сообщение на человеческом языке.
То есть вместо «Network link failure #7244» надо вывести «Произошло отключение от сервера, дальнейшая работа невозможна».
Если в приложении всё более-менее понятно, то при написании процедур на SQL-сервере разработчики, видимо, надеются, что сервер сам прекратит выполнение процедуры при возникновении ошибки.
После каждого SQL-оператора обязательно должен проверяться и обрабатываться код последней ошибки.
Правильность работы программы не может быть обеспечена без тотальной обработки ошибок.
Памятка 8. Короткие транзакции или «скажи блокировкам – НЕТ!»
Большинство SQL-серверов используют технологию блокировок при любой модификации данных.
То есть, данные, изменённые в транзакции одним из пользователей, недоступны для других пользователей до завершения этой транзакции.
Совсем избежать блокировок нельзя, однако можно уменьшить продолжительность транзакций.
Для этого перед выполнением транзакции для неё должны быть уже подготовлены все необходимые данные. Внутри транзакции не должно быть никаких обращений к внешним устройствам (файлам, сети и т.п.) – только к базе данных.
Ситуация, когда внутри транзакции происходит диалог с пользователем, тем более недопустима.
Короткие транзакции дают возможность большему числу пользователей одновременно работать с базой данных, не конфликтуя друг с другом.
Памятка 9. Наличие метаданных или «кому нужна база без головы?»
Метаданные описывают структуру базы данных и взаимосвязи её объектов.
При некоторых манипуляциях с базой данных может потребоваться информация о том, какие сущности хранятся в этой базе, в каких таблицах и полях, как они связаны друг с другом.
Частично эту информацию можно получить из системного каталога SQL-сервера. Но системный каталог предназначен скорее не для разработчика, а для внутреннего использования самим сервером, поэтому найти там что-либо весьма проблематично.
При этом, его структура может меняться даже в разных версиях одного сервера, не говоря уже об отсутствии какой-либо совместимости с другими SQL-серверами.
Даже довольно неполные метаданные имеют широкую область применения. Но чаще всего они используются для упрощения собственной работы программистов, вплоть до автоматической генерации приложения и объектов БД.
Наличие метаданных даёт полную информацию о базе данных, облегчая разработчикам решение многих задач.
Памятка 10. Хранение истории или «кто владеет прошлым – тот владеет будущим»
Большинство объектов, хранящихся в базе данных, могут меняться с течением времени.
К сожалению, почти все современные СУБД не хранят историю изменений и не позволяют получить состояние объектов на определённую дату. Об этом должен позаботиться разработчик базы данных.
Только база данных, которая хранит всю историю изменений всех своих объектов, может претендовать на полноту и завершённость.
Иначе простейший запрос, вроде «Дайте список объектов в том виде, в котором они были на 01.05.2007 г» так и останется без ответа.
База данных, хранящая изменяемые объекты, должна содержать полную историю всех их изменений.