

2.5.6. Размещение записей в области переполнения
Существуют два подхода к организации хранения записей, направляемых в область переполнения.
Записи располагаются в области переполнения, отделённой от основной области.
Записи располагаются в области переполнения, хранимой в пределах основной области.
Отдельная область переполнения может быть организована для каждого участка основной области, или записи могут быть объединены в области переполнения независимо от того, из какого участка основной области они были направлены.
Существуют два основных метода реализации этих подходов.
Метод организации цепочек участков переполнения.
Метод распределённой области переполнения, который аналогичен методу распределённой свободной памяти, рассмотренному в предыдущих разделах курса.
2.5.7. Итог
Итак, мы закончили рассмотрение основных алгоритмов хэширования, применяемых в СУБД.
В следующей теме мы поговорим о механизмах физического хранения данных в конкретных СУБД.
2.6. Механизмы обработки и хранения данных в бд
2.6.1. Введение
Итак, мы переходим к рассмотрению конкретных решений в области хранения и обработки данных на физическом уровне в реляционных СУБД.
Нам с вами предстоит рассмотреть принципы физической организации данных в MS SQL Server, а также такие методы физической организации данных как: ISAM, VSAM, MyISAM, InnoDB.
Рассмотрение этой части нашего курса мы начнём с классической СУБД, стоящей «посередине» по степени сложности, но в то же время дающей хорошее представление о механизмах хранения и обработки данных, – MS SQL Server.
2.6.2. Механизмы обработки и хранения данных в ms-sql 6.0-6.5
В версии 6.0 и 6.5 MS SQL Server структура хранения данных рассматривается в следующей иерархии.
Файлы операционной системы представляются как устройства (device) для хранения БД, устройства нумеруются.
Сервер может управлять 256 устройствами.
Главное устройство называется Master: на нём хранятся системные базы данных: Master, Model, Pubs, TcodepDb.
Устройство Master имеет номер 0 (ноль).
Каждое устройство разбивается не более чем на 16’777’216 виртуальных страниц (virtual page) по 2 Кб.
Максимальный размер устройства – 32 Гб.
Первые 4 страницы устройства Master заняты под блок конфигурации (configuration block) – там хранятся все параметры конфигурации сервера.
На каждом устройстве может быть размещено несколько баз данных, но и одна база может быть размещена на нескольких устройствах.
Каждая страница БД имеет свой уникальный номер.
Физически используются 3 единицы хранения данных:
страница (page);
блок (extent) – 16Кб из 8 следующих друг за другом страниц;
единица размещения (allocation unit) – 512 Кб из 32 последовательных блоков (256 страниц).
При создании новой базы данных пространство для неё отводится единицами размещения. Минимальный объём базы данных для данной версии сервера равен 1 Мб, то есть составляет 2 единицы размещения.
Страницы бывают пяти типов:
страницы размещения (allocation page);
страницы данных (data page);
индексные страницы (index page);
текстовые страницы (text/image page);
статистические страницы (distribution page).
Любая страница имеет заголовок, занимающий 32 байта.
Заголовок содержит:
номер страницы;
номера предыдущей и следующей страниц;
идентификатор объекта (владельца страницы);
сведения о свободном пространстве на странице.
Как видно из заголовка, страницы связаны в двунаправленный список.
Первая страница каждой единицы размещения (allocation unit) является страницей размещения (allocation page).
Таким образом, все страницы, кратные 256, начиная с 0, являются страницами размещения.
Они хранят информацию, необходимую для управления размещением страниц внутри единицы размещения.
Страница размещения содержит 32 16-байтовых структуры, по одной на каждый блок. Каждая структура содержит следующую информацию:
идентификатор объекта (владельца блока);
номер следующего блока в цепи;
номер предыдущего блока в цепи;
битовую карту распределения блока (allocation bitmap);
битовую карту перераспределения блока (deallocation bitmap);
идентификатор индекса (если таковой есть), размещённого на блоке;
статус.
Битовая карта распределения блока хранится в единственном байте, каждый бит которого соответствует одной странице блока.
Если бит равен 1, то страница в данный момент содержит данные, если 0 – страница свободна.
Карта перераспределения применяется для отслеживания страниц, которые освобождаются в течение транзакций.
Реально страница помечается как пустая только после успешной фиксации (завершения) транзакции. Это делается, чтобы другие транзакции не обращались к странице до подтверждения того факта, что она освобождена.
Все страницы в блоке могут использоваться только одной таблицей или её индексом. Это означает, что таблица может занимать минимально 1 блок – 16 Кбайт, даже если она содержит всего несколько строк.
Страницы данных используются для хранения собственно данных. Структурно страницу данных можно подразделить на три зоны:
заголовок;
строки данных;
таблицу смещения.
Рассмотрим на рисунке…
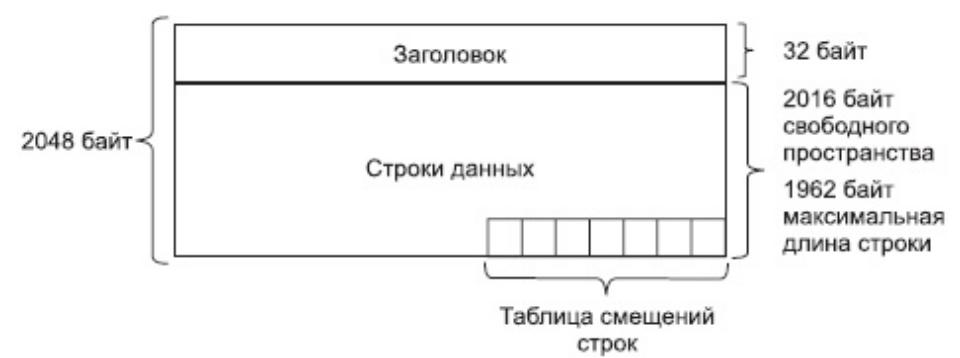
Рисунок 2.6.2.1 – Структура страницы
Строка данных должна полностью умещаться на странице, поэтому существуют ограничения на длину строки.
Размер страницы равен 2048 байт, 32 байта занимает заголовок.
Кроме того, в таблице смещения отводится по 2 байта на каждую строку на странице.
Страницы данных, относящиеся к одной таблице, объединяются в двунаправленный список и организуют цепочки.
Данные хранятся на страницах в виде строк (кортежей). Каждая строка данных кроме собственно данных хранит дополнительную форматирующую информацию.
Длина строки зависит от определения полей таблицы и конкретных данных в ней.
Независимо от объявления, каждая строка имеет номер и поле с указанием количества полей переменной длины (к ним относятся также поля, допускающие значения NULL).
Оба эти поля имеют размер по одному байту, следовательно, количество строк на странице не превышает 256, а на количество полей также существует внешнее ограничение – 250 полей в одной таблице.
Структура строки таблицы приведена на следующем рисунке…
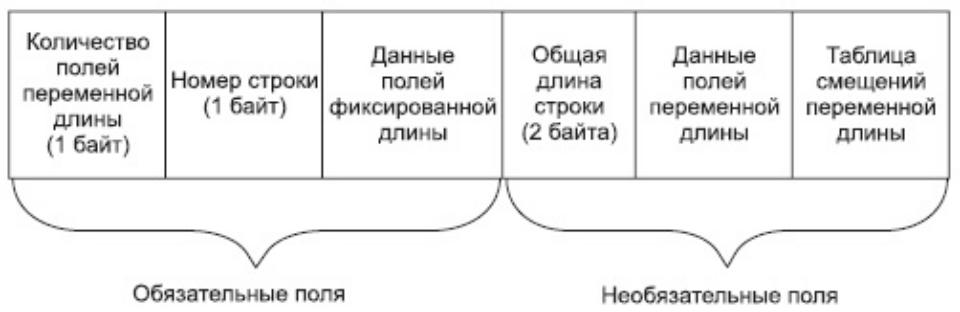
Рисунок 2.6.2.2 – Структура строки таблицы
Вторая часть строки – необязательная область, которая существует только тогда, когда в записи есть поля переменной длины.
Таблица смещений (column offset table) состоит из:
таблицы подстройки смещений (offset table adjust bytes) – по 1 дополнительному байту на каждое поле, смещение которого превышает 256 байт;
указателя на местоположение таблицы смещений;
указателя на местоположение полей переменной длины (1 байт на каждое поле).
Указатели занимают два последних байта в каждой структуре.
Таблица смещения строк
Местоположение строки на странице определяется таблицей смещения строк (row offset table).
Таблица располагается в самом конце страницы и забирает дополнительно по 2 байта на каждую строку данных.
Чтобы найти строку с заданным номером, SQL Server считывает из соответствующей ячейки смещение, которое и является адресом требуемой строки. Ячейка таблицы однозначно связана с определённым номером строки.
Удалённые строки имеют нулевое смещение. Поэтому из примера на следующем рисунке видно, что строки 1 и 4 удалены.
У этой модели есть недостаток. После удаления строки в таблице смещения всё равно остаётся ссылка на неё, которая занимает 1 байт.
Однако при добавлении новой строки SQL Server проверяет таблицу смещений, и новой строке присваивается номер удалённой, а в соответствующую ячейку таблицы смещений заносится адрес новой строки.
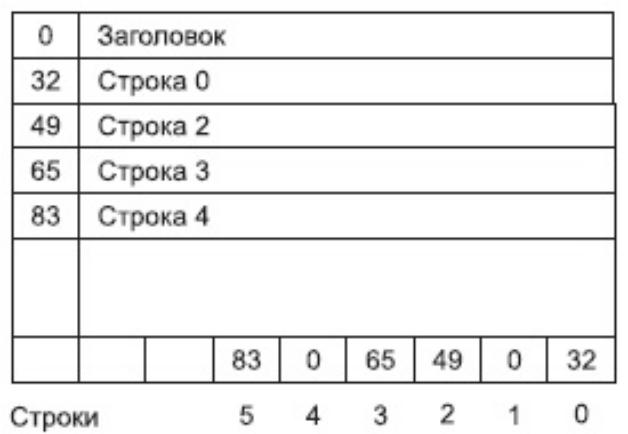
Рисунок 2.6.2.3 – Таблица смещений строк
В SQL Server 6.5 используется понятие кластерного индекса.
В таблице, для которой создаётся кластерный индекс, данные хранятся строго упорядоченно по полю, для которого создан этот кластерный индекс.
Это поле (или набор полей) является первичным ключом таблицы или обладает свойством уникальности.
При заполнении таблиц с кластерным индексом вводится параметр, соответствующий проценту заполнения страницы (fill-factor). Если страница заполнена, то данные заносятся на последнюю страницу в цепочке страниц, занятых этой таблицей.
На одной текстовой странице хранятся только данные одной строки основной таблицы (см. следующий рисунок).
В основной таблице в соответствующем месте хранится только ссылка на соответствующую текстовую страницу.
Если данные не умещаются на одной странице, они образуют цепочку взаимосвязанных страниц.
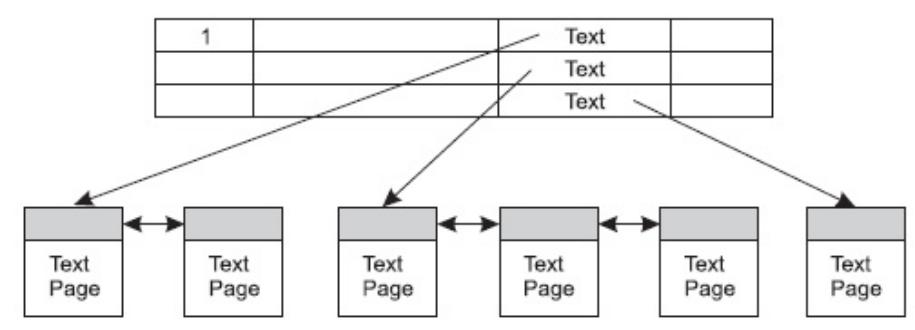
Рисунок 2.6.2.4 – Хранение тестовых данных