

2.4.7. Индексирование по полям
Если запрос «найти всех поставщиков из данного города» является важным, мы можем выбрать вариант представления, изображенный на следующем рисунке:
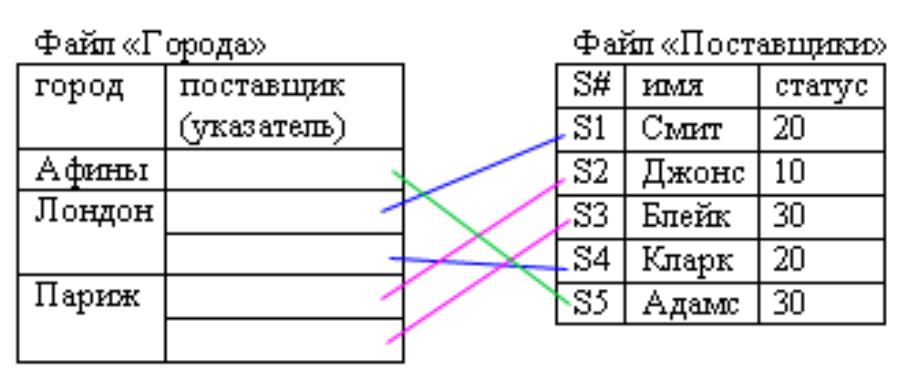
Рисунок 2.4.7.1 – Индексирование по полям
Здесь у нас также есть два хранимых файла: файл поставщиков и файл городов, но в этом случае указатели установлены из второго файла (городов) в первый (поставщиков).
Этот вариант лучше предыдущего для запросов о всех поставщиках, размещённых в некотором городе, но обеспечивает худшие характеристики для запросов о всех атрибутах некоторого поставщика.
Требования к объёму памяти здесь такие же, как и в предыдущем случае.
Интересным свойством этого представления является то, что файл городов служит индексом для файла поставщиков (индекс, управляемый СУБД, но не методом доступа).
Фактически это т.н. «плотный вторичный индекс» («плотный» означает, что индекс содержит отдельную запись для каждого экземпляра хранимой записи индексируемого файла, «вторичный» означает, что индексируемое поле не является первичным ключом).
В этом случае (поскольку индекс – плотный) индексируемый файл не должен содержать индексируемое поле (в этом примере файл поставщиков не включает поле города).
Мы рассмотрим «неплотное» индексирование чуть-чуть позже.
2.4.8. Комбинация простых представлений
Мы можем соединить два предыдущих варианта представления, чтобы получить преимущество каждого за счёт потери большего объёма памяти и (что, возможно, является более существенным) за счёт необходимости прилагать больше усилий для поддержания указателей при изменениях.

Рисунок 2.4.8.1 – Комбинация простых представлений
2.4.9. Использование цепочек указателей
Недостатком вторичных индексов является непредсказуемое число указателей в каждом элементе индекса, т.е. в каждом экземпляре хранимой записи в индексе. Это усложняет работу СУБД при изменениях в базе данных.
Другой вариант представления, который устраняет эту проблему, изображён на следующем рисунке.

Рисунок 2.4.9.1 – Использование цепочек указателей
В этом случае каждый экземпляр хранимой записи файла поставщиков или файла городов содержит только один указатель.
Каждая запись файла городов указывает на запись первого поставщика в этом городе. Эта запись поставщика указывает на запись второго поставщика того же самого города, которая в свою очередь указывает на запись третьего и т.д. до записи последнего, которая содержит указатель на запись города.
Таким образом, для каждой записи города у нас есть цепочка записей всех поставщиков в этом городе.
Преимущество этого варианта представления состоит в простоте внесения изменений.
Недостатком является то, что для данного города единственным способом доступа к n-му поставщику является последовательное прохождение по цепочке от первого ко второму и т.д. до (n-1)-го поставщика.
Если каждая операция доступа включает операцию поиска, то время доступа к n-му поставщику может стать достаточно большим.
Развитием описанного выше способа представления является использование двунаправленных цепочек (каждый экземпляр хранимых записей содержит строго два указателя).
Этот вариант представления хорош, если операция удаления поставщиков выполняется часто, так как такое представление упрощает процесс реорганизации ссылок, который необходимо осуществлять в подобных случаях.
Другим развитием подобного способа представления может также служить включение в запись поставщика указателя на соответствующую запись города, для того чтобы сократить объём просматриваемых ссылок при выполнении некоторых типов запросов.