

2.3.8. Связи
Связь (relationship) – способ указания того факта, что два (иногда – одно или более двух) отношения находятся в логической взаимосвязи друг с другом. Наличие связи налагает на объединённые этой связью отношения ряд ограничений, призванных гарантировать те или иные виды целостности базы данных (будет рассмотрено немного позднее).
В реальных БД связи организуются с помощью ключей.
Именно о ключах мы сейчас и поговорим…
2.3.9. Ключи отношений
Ключ (key) – атрибут (или совокупность атрибутов) отношения, обладающий некоторыми специфическими свойствами, зависящими от вида ключа.
Первичный ключ (primary key) – минимальное множество атрибутов, являющееся подмножеством заголовка данного отношения, составное значение которых уникально определяет кортеж отношения.
На практике термин «первичный ключ» обозначает поле (столбец) или группу полей таблицы базы данных, значение которого (или комбинация значений которых) используется в качестве уникального идентификатора записи (строки) этой таблицы.
Напомним, что в теории реляционных баз данных таблица (отношение) представляет собой изначально неупорядоченный набор записей (кортежей).
Единственный способ идентифицировать определённую запись в этой таблице – указать набор значений одного или нескольких полей, который был бы уникальным для этой записи.
Первичный ключ в таблице является базовым уникальным идентификатором для записей. Значение первичного ключа используется везде, где нужно указать на конкретную запись. На использовании первичных ключей основана организация связей между таблицами реляционной БД.
Чтобы организовать между двумя таблицами связь типа «один к одному» или «один ко многим (многие к одному)» в одну из связываемых таблиц добавляют поле (поля), содержащее(ие) значение первичного ключа записи в связанной таблице (такое поле называют внешним ключом, а факт добавления такого поля – миграцией ключа).
Для организации связи типа «многие ко многим» создают отдельную таблицу (так называемую «таблицу связи» или «таблицу ассоциации»), каждая запись которой содержит первичные ключи двух связанных записей в разных таблицах.
Простой первичный ключ (simple key) – первичный ключ, состоящий из единственного поля таблицы (атрибута отношения), значения которого уникальны для каждой записи.
Так, например, не может быть двух работников с одинаковыми номерами паспортов, поэтому в таблице, содержащей записи о работниках, номер паспорта может быть первичным ключом.
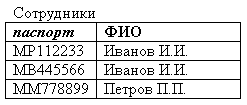
Рисунок 2.3.9.1 – Первичный ключ
Составной первичный ключ (compound key, composite key, concatenated key) – первичный ключ, состоящий из нескольких полей таблицы (атрибутов отношения).
Если таблица не имеет единственного уникального поля, первичный ключ может быть составлен из нескольких полей, совокупность значений которых гарантирует уникальность.
Классическим примером составного первичного ключа является ситуация с «таблицей связи», используемой при организации связи типа «многие ко многим».

Рисунок 2.3.9.2 – Составной первичный ключ
Что ещё (какие поля) можно добавить в такую таблицу?
Например: «вид родства» (усыновлён, родной ребёнок и т.п.)
Первичный ключ может состоять из информационных полей таблицы (то есть полей, содержащих полезную информацию об описываемых объектах).
Такой первичный ключ называют естественным ключом.
На практике использование естественных ключей наталкивается на определённые сложности:
низкая эффективность – естественный ключ может быть велик по размеру (особенно, когда он составной), и его использование окажется технически неэффективным (ведь во всех таблицах, связанных с данной, понадобится создать поле того же размера, чтобы хранить ссылки);
необходимость каскадных изменений – при изменении значения поля, входящего в естественный ключ, оказывается необходимым изменить значение поля не только в данной таблице, но и во всех таблицах, связанных с данной, в противном случае все ссылки на данную запись окажутся некорректными; при добавлении новых связанных таблиц приходится добавлять согласующие изменения во все места программ, где правится исходная таблица;
несоответствие реальности – уникальность естественного первичного ключа в реальных БД не всегда соблюдается (допустим, например, что первичный ключ в таблице - данные личного документа; в такую таблицу окажется невозможным внести человека, о документах которого нет информации в момент добавления записи, а на практике такая необходимость может возникнуть).
Вследствие этих и других соображений в практике проектирования БД чаще используют т.н. синтетические (суррогатные) ключи – искусственно созданные технические ключевые поля, не несущие информации об объектах.
Чаще всего таким ключом является целочисленное поле, на которое налагается функция автоинкрементирования.
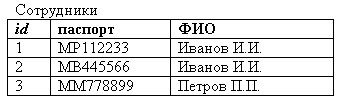
Рисунок 2.3.9.3 – Синтетический первичный ключ
Суррогатный ключ (surrogate key) – дополнительное служебное поле, добавленное к уже имеющимся информационным полям таблицы, единственное предназначение которого – служить первичным ключом.
Значение этого поля не образуется на основе каких-либо других данных из БД, а генерируются искусственно.
Как правило, суррогатный ключ – просто числовое поле, в которое заносятся значения из возрастающей числовой последовательности.
Это может делаться при помощи триггеров (типичный способ порождения ключей в Oracle).
В ряде СУБД (например, Sybase, MySQL или SQL Server) существует специальный тип данных для таких полей – числовое поле, в которое при добавлении записи в таблицу автоматически записывается уникальное для этой таблицы числовое значение – т.н. «автоинкремент» (autoincrement).
Главное достоинство суррогатного ключа состоит в том, что он никогда не изменяется, поскольку не является информативным полем таблицы (не несёт никакой информации об описываемом записью объекте).
Использовать суррогатный первичный ключ имеет смысл, если естественный первичный ключ (составленный из информативных полей таблицы) – составной, и на него придётся ссылаться во внешних ключах многих таблиц.
Так, например, проще написать запрос:
SELECT * FROM p, c WHERE p.primary_key = c.foreign_key;
Чем
SELECT * FROM p, c WHERE p.id1 = c.fk1 AND p.id2 = c.fk2 AND p.id3 = c.fk3;
Кроме того, первый вариант работает быстрее.
Также использовать суррогатный ключ имеет смысл в случае, когда возможны изменения полей, составляющих естественный первичный ключ (в особенности если этот ключ – составной).
Возможный ключ (possible key) – атрибут или набор атрибутов (полей) отношения (таблицы), совокупность значений которых отвечает требованиям, предъявляемым к первичному ключу (т.е. является уникальной для каждой записи в таблице).
Каждый возможный ключ, кроме выбранного первичным, называется так же альтернативным ключом (alternative key).
Таблица может иметь несколько возможных ключей. Так, например, в таблице сотрудников фирмы одним возможным ключом может являться табельный номер, другим – группа полей, хранящая данные личного документа сотрудника. Возможны и другие комбинации полей, также дающие уникальные значения для каждой записи.
Один из возможных ключей таблицы выбирается в качестве её первичного ключа.
Теоретически, все возможные ключи равно пригодны в качестве первичного ключа. На практике в качестве первичного обычно выбирается тот из возможных ключей, который имеет меньший размер и включает меньшее количество полей.
Нередко при наличии в таблице нескольких естественных возможных ключей в качестве первичного всё равно используется суррогатный ключ, в силу его преимуществ.
В реальных СУБД обычно имеется возможность специально описывать возможные ключи таблицы, не являющиеся её первичным ключом.
Для объявленных возможных ключей в БД создаются индексы, обеспечивающие быстрый поиск записей по набору значений полей ключа, и включаются механизмы, не позволяющие добавлять или редактировать записи таблицы таким образом, чтобы значение возможного ключа дублировалось в нескольких записях.
Интеллектуальный ключ (intelligent key) –разновидность естественного ключа: ключ, который зависит от одного или более полей своей таблицы, и его значение формируется на основе значений этих полей.
Например, мы можем сформировать трёхсимвольный интеллектуальный ключ для таблицы персонала из первых букв фамилии, имени и отчества сотрудников.
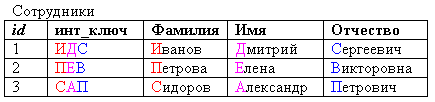
Рисунок 2.3.9.3 – Интеллектуальный ключ
Особенности интеллектуальных ключей
По сути, интеллектуальный ключ является естественным составным ключом, поэтому ему присущи все недостатки естественного ключа.
Главный недостаток интеллектуального ключа состоит в том, что если изменяются значения полей таблицы, от которых ключ зависит, то сам интеллектуальный ключ либо останется неизменённым, что приведёт к рассогласованности данных, либо также должен быть изменён, как в своей собственной таблице, так и во всех других таблицах, в которых он используется как внешний ключ.
Кроме того, интеллектуальный ключ не всегда может гарантировать уникальность, например, если в только что рассмотренную таблицу таблицу добавится запись «Петров Евгений Васильевич»:
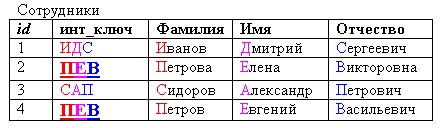
Рисунок 2.3.9.4 – Нарушение уникальности интеллектуального ключа
На практике интеллектуальные ключи часто используются в качестве т. н. «магических кодов» (magic codes) – идентификаторов, отражающих те или иные данные.
Например, идентификатор события «03-40123» в формате «FY-XNNNN», где:
FY = 2 цифры финансового года;
X = 1 цифра, задающая тип события;
NNNN = 4 цифры, задающие порядковый номер события данного типа в этом финансовом году.
Ничего не напоминает?
Это – хэш. Т.е. один из видов примитивного хэша.
Однако применении такого рода идентификаторов далеко не всегда оправдано по следующим причиним:
если при вводе данных произошла ошибка, и ключ оказался неверным (например, событие было типа 3, а не 4), то в системе это событие уже известно как «03-40123», и для исправления ситуации необходимы будут каскадные изменения данных;
в систему вносятся ограничения, основанные на предположениях о максимальных значениях полей:
количество событий в году не более 10000;
типов событий не более 10;
две цифры для года – вспомним «проблему 2000».
такие ключи неудобно реализовывать;
далеко не всегда существует необходимость знать значения атрибутов записи непосредственно из её ключа.
Один из способов решения вышеперечисленных проблем – использование суррогатных ключей.
Внешний ключ (foreign key) – поле таблицы, предназначенное для хранения значения первичного ключа другой таблицы с целью организации связи между этими таблицами.
Пусть имеются таблицы «A» и «B».
Таблица «A» содержит поля «a», «b», «c», «d», из которых поле «a» – первичный ключ.
Таблица «B» содержит поля «x», «y», «z». В поле «y» содержится значение поля «a» одной из записей таблицы «A».
В таком случае поле «y» называется внешним ключом таблицы «A» в таблице «B».
Вот такой SQL-запрос вернёт все связанные пары записей из таблиц «A» и «B»:
select * from A, B where A.a = B.y
Внешний ключ в таблице может ссылаться и на саму «свою» таблицу. В таких случаях говорят о рекурсивном внешнем ключе.
Рекурсивные внешние ключи используются для хранения гомогенной древовидной структуры данных в реляционной таблице.
Развитые СУБД поддерживают автоматический контроль ссылочной целостности на внешних ключах.
Пример только что описанных таблиц «A» и «B».
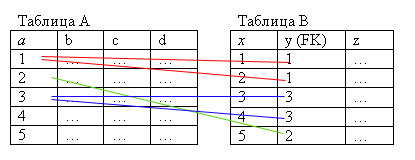
Рисунок 2.3.9.5 – Пример описанных таблиц
Пример рекурсивного внешнего ключа.
Хранимая структура:

Рисунок 2.3.9.6 – Хранимая структура
Пример рекурсивного внешнего ключа.
Таблица:
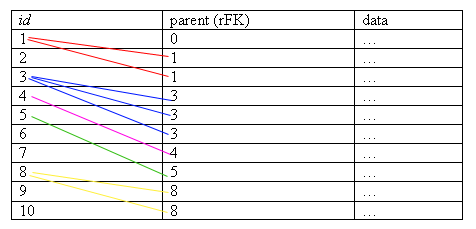
Рисунок 2.3.9.7 – Табличное представление хранимой структуры