

2.4.24. Сбалансированные деревья
Построение В-деревьев (balanced trees, сбалансированных деревьев) связано с простой идеей построения индекса над уже построенным индексом.
Если мы построим неплотный индекс, то сама индексная область может быть рассмотрена как основной файл, над которым надо снова построить неплотный индекс, а потом снова над новым индексом строим следующий и так до того момента, пока не останется всего один индексный блок.
Мы в общем случае получим некоторое дерево, каждый родительский блок которого связан с одинаковым количеством подчинённых блоков, число которых равно числу индексных записей, размещаемых в одном блоке.
Количество обращений к диску при этом для поиска любой записи одинаково и равно количеству уровней в построенном дереве.
B-деревья могут применяться при любом виде индексирования (последовательном или произвольном). Они являются хорошим способом ускорить процедуры нахождения записей.
2.4.25. Ведение файла
Хотя последовательная организация данных требует меньший индекс, она более сложна для эксплуатации файла.
При включении новых записей возникает необходимость либо пересортировки файла, либо внесения новых записей в отдельную область и организации указателей на эти записи.
На следующем рисунке показано включение четырёх новых записей в последовательный файл.
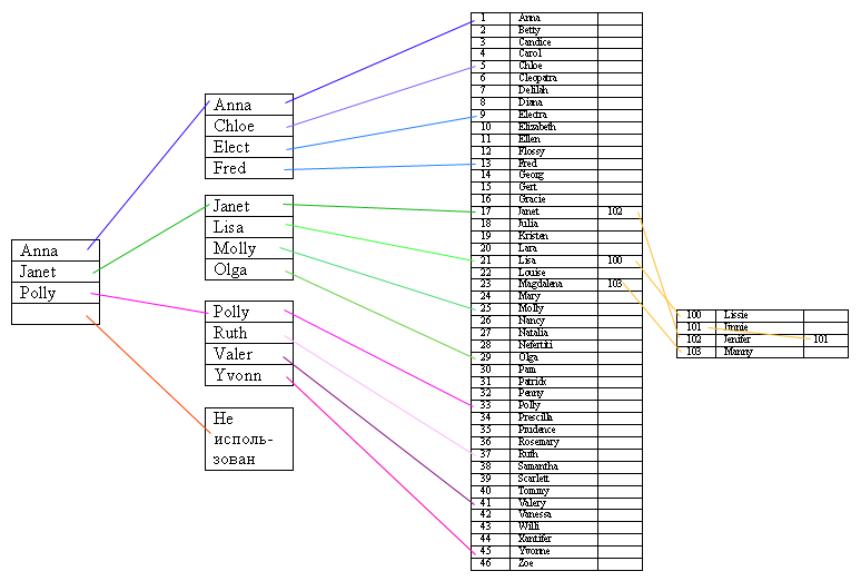
Рисунок 2.4.25.1 – Ведение файла
При добавлении записи оказались в т.н. «области переполнения». Затем будет произведена реорганизация основного файла и индексов, в результате чего новые записи займут своё место в последовательной организации.
Однако, как несложно понять, процесс реорганизации файлов и индексов – это долгий процесс.
Недостаток храпения записей в области переполнения заключается в том, что при всяком обращении к этим записям требуются дополнительные операции чтения.
Потом обычные файлы, имеющие области переполнения периодически реорганизуются, т.е. записи файла заново сортируются и производятся соответствующие изменения в индексе.
Эта операция называется ведением файла.
Ведение некоторых структур баз данных представляет собой более серьёзную проблему, чем ведение обычного файла с индексно-последовательной организацией.
В файле с произвольным расположением записей новые записи просто включаются в конец файла, и при этом не требуется организовывать указатели на область переполнения и выполнять процедуры включения записей.
Однако в данном случае возникает необходимость некоторой перегруппировки элементов индекса (что, впрочем, выполняется значительно быстрее, чем ведение большого файла).
При последовательном расположении записей можно избежать частого выполнения процедуры ведения, предусматривая в файле позиции с «пустыми записями».
Однако данный метод не позволяет полностью избежать выполнения процедуры ведения («пустые записи» могут закончиться; добавленные данные могут оказаться расположенными с нарушением упорядоченности).
Метод, основанный на включении пропусков в файле, называется «методом распределённой свободной памяти» (distributed free space).
Хотя, применяя данный метод, теоретически можно избежать записей переполнения (делая много «пустых записей» и реорганизовывая файл по мере уменьшения их количества), всё равно целесообразно периодически выполнять процедуры ведения с целью приведения файла к наиболее оптимальному для работы с ним виду.