

2.Пересылка слова данных из одного регистра в другой.
П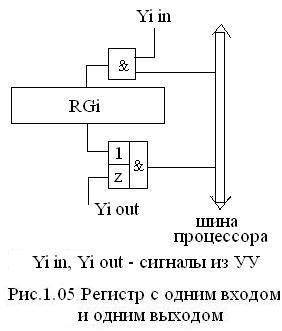 ри
загрузке RG:
подается сигнал Yi
in
из УУ, который открывает входные цепи
регистра и данные из шины записываются
в RGi.
ри
загрузке RG:
подается сигнал Yi
in
из УУ, который открывает входные цепи
регистра и данные из шины записываются
в RGi.
При считывании подается сигнал Yi out от УУ, открываются выходные цепи RGi и данные передаются на шину.
Если сигналы Yi in и Yi out равны «0», то RGi, имеющий 3 состояния выхода, отключается от шины, которая после этого может использоваться другими устройствами.
Все операции по пересылке данных внутри процессора выполняются в течение периода тактовых сигналов, причем, как правило RG срабатывают по фронту сигнала.
Возможны схемы, управляемые как фронтом, так и спадом или несколькими тактовыми сигналами (при многофазной синхронизации).
3.Выполнение арифметической или логической операции.
Допустим надо выполнить сложение двух операндов, хранимых в RG1 и RG2 блока RGM, а результат сложения записать в RG3 того же блока.
В первом такте сигналом Y1out активизируется выход RG1 и его содержимое (первый операнд) через шину процессора сигналом Yy in загружается в RGY.
Во втором такте по сигналу Ymux мультиплексор передает содержимое RGY в буфер ALU A. В этом же такте по сигналу Y2out второй операнд из RG2 передается на шину, с которой по сигналу YB in записывается в буфер ALU B.
В третьем такте по сигналу Yadd ALU производит сложение.
В четвертом такте по сигналу YSM in результат сложения из ALU записывается в RG SM.
В пятом такте по сигналу YSM out и Y3 in результат сложения из RG SM записывается в RG3. Операция выполнена.
Выводы:
Операция сложения произведена за 5 тактов, при использовании различных сигналов управления, вырабатываемых УУ при дешифровке им команды, находящейся в RG IR.
В некоторых тактах одновременно использовалось несколько управляющих сигналов (для устройств, которые могли работать параллельно).
Очевидно, что для различных операций требуется разное число тактов и управляющих сигналов. Так, например, для вычитания потребуется уже 6 тактов и один дополнительный сигнал подсуммирования «1» в ALU для получения результата вычитания в прямом коде.
Единственная шина в процессоре не позволяет проводить некоторые действия параллельно.
При рассмотрении выполнения операций, предполагалось наличие линии от УУ к объекту для каждого сигнала управления. На практике число линий меньше благодаря использованию кодирования числа сигналов управления. Например, если ALU выполняет 16 операций, то от УУ по 4 линиям (вместо 16) можно передать четырехразрядную комбинацию с последующей ее дешифровкой уже в блоке ALU.
Как это делается, будет рассмотрено позже.
1.4 Выборка слова из памяти.
Как уже известно, одна внутренняя пересылка данных в процессоре производится за один такт.
Если данные запрашиваются процессором из внешних устройств, в том числе и основной памяти, то в силу их разного быстродействия на этот запрос может уходить несколько тактов процессорного времени, и процессор вынужден ожидать ответ.
Послав запрос на данные, процессор будет ждать подтверждения получения этого запроса и выполнения данной операции. Для этого используется сигнал MFC (Memory Function Complete).
Внешнее устройство устанавливает этот сигнал в «1» после прочтения данных (памяти). Операция чтения из памяти с помощью команды MOVE(RG1), RG2 , ( MOVE – перемещение) которая читается следующим образом: .
По адресу. хранящемуся в RG1, прочитать данные в памяти и поместить их в RG2. Процесс выполнения команды чтения из памяти можно представить следующей временной диаграммой, представленной на рис. 1.06.
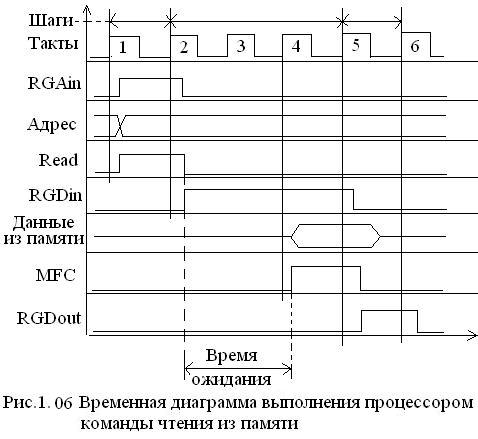
С момента подачи команды Read (читать) и до прихода сигнала MFC в процессоре вырабатывается сигнал WMFC (Wait for MFC – ожидание MFC), которое предписывает соответствующим схемам процессора находиться в режиме ожидания.
Запись данных в память аналогична с той разницей, что в командах вместо Read вписывается Write и используется команда MOVE R2,(R1).
Выполнение процессором всей команды.
Рассмотренные операции, необходимые для выполнения всей команды можно свести в одну последовательность.
Рассмотрим пример сложения двух операндов.
Исходные условия: первый операнд находится в памяти по адресу, хранящемуся в RG3, а второй операнд содержится в RG1. Результат поместить в RG3.
Сложение производится по команде:
Add(RG3),RG1
Выполняется в 4 этапа:
1. Выборка команды.
2.Выборка первого операнда из памяти.
3.Суммирование.
4.Загрузка результата в RG3.
Последовательность шагов (тактов) выполнения запишем в виде микропрограммы сложения (рис.1.07).

Комментарии шагов:
Шаг 1-3 – фаза выборки команды одинаковы для всех команд.
На шаге 1: в RGAin загружается содержимое (адрес команды) счетчика CTout, которое далее сигналом чтения Read по шине направляется в память, а на вход MUX подается сигнал выбора константы 4 (select 4)(при побайтовой адресации), которую надо прибавить к адресу CTin для получения нового адреса команды или операнда.
Для этого на вход A ALU подается 4, и поскольку на вход В – «0», то под действием сигнала суммирования Add ALU даст результат 4, который и записывается в RG SMin.
На шаге 2: Пока протекает ожидание ответа из памяти (WMFC), содержимое RG SMout прибавляется к содержимому счетчика СТin, формируя тем самым новый адрес.
На шаге 3: Принятая команда в RG Dout пересылается в регистр команды RG IRin. Далее в УУ происходит её дешифровка и начинается процесс выполнения команды.
На шаге 4: Дешифрованная команда активизирует соответствующие управляющие сигналы.
Содержимое RG 3out (адрес первого операнда) пересылается в RG Ain и инициируется сигнал чтения Read, которые по шине передаются в память.
На шаге 5: В течение ожидания (WMFC) содержимое RGout пересылается в RG Yin.
На шаге 6: Полученный из памяти операнд из RG Dout передаются на вход В ALU, а по сигналу Select Y (управление MUX) операнд из RG Y передается на вход А ALU.
По сигналу суммирования Add происходит сложение и далее запись результата в RG SMin.
На шаге 7: Результат из RG SMout пересылается в RG3in. Команда выполнена. УУ вырабатывает сигнал End, происходит возврат в шагу 1.