

4. Кодирование символьной информации
4.1 Постановка задачи кодирования. Первая теорема Шеннона
Будем считать, что источник представляет информацию в форме дискретного сообщения, используя для этого алфавит, который назовем первичным.
Далее это сообщение попадает в устройство, преобразующее и представляющее его в другом алфавите – назовем его вторичным.
Код – правило, описывающее соответствие знаков или их сочетаний первичного алфавита знакам или их сочетаниям вторичного алфавита;
– набор знаков вторичного алфавита, используемый для представления знаков или их сочетаний первичного алфавита.
Кодирование – перевод информации, представляемой сообщением в первичном алфавите, в последовательность кодов.
Декодирование – операция, обратная кодированию, то есть восстановление информации в первичном алфавите по полученной последовательности кодов.
Кодер – устройство, обеспечивающее выполнение операции кодирования.
Декодер – устройство, производящее декодирование.
Операции кодирования/декодирования называются обратимыми, если их последовательное применение обеспечивает возврат к исходной информации без каких-либо потерь.
(Пример обратимого кодирования – представление знаков в телеграфном коде и их восстановление после передачи. Пример необратимого кодирования – перевод с одного естественного языка на другой.)
В дальнейшем будем рассматривать только обратимое кодирование.
Кодирование предшествует передаче и хранению информации.
Не обсуждая технику сторон передачи и хранения сообщения, дадим математическую постановку задачи кодирования.
Пусть
первичный алфавит А состоит из N знаков
со средней информацией на знак
![]() ,
а вторичный алфавит В – из М знаков со
средней информацией на знак
,
а вторичный алфавит В – из М знаков со
средней информацией на знак
![]() .
.
Пусть исходное сообщение, представленное в первичном алфавите, содержит n знаков, а закодированное сообщение – m знаков.
Если исходное сообщение содержит Ist(A) информации, а закодированное Ifin(B), то условие обратимости кодирования, то есть неисчезновения информации при кодировании, может быть записано следующим образом
Ist(A) Ifin(B).
Смысл данной формулы в том, что операция обратимого кодирования может увеличить количество информации в сообщении, но не может его уменьшить.
Однако каждая из величин в данном неравенстве может быть заменена произведением числа на среднее информационное содержание знака, то есть
n
![]() m
m
![]() или
или
![]() .
.
Очевидно,
что
![]() характеризует среднее число знаков
вторичного алфавита, которое приходится
использовать для кодирования одного
знака первичного алфавита – будем
называть его длиной кода или длиной
кодовой цепочки и обозначим К(А,В) > 1,
то есть один знак первичного алфавита
представляется несколькими знаками
вторичного.
характеризует среднее число знаков
вторичного алфавита, которое приходится
использовать для кодирования одного
знака первичного алфавита – будем
называть его длиной кода или длиной
кодовой цепочки и обозначим К(А,В) > 1,
то есть один знак первичного алфавита
представляется несколькими знаками
вторичного.
Поскольку способов построения кодов при фиксированных алфавитах А и В существует множество, возникает проблема выбора наилучшего варианта – будем называть его оптимальным кодом.
Выгодность кода при передаче и хранении информации – это экономический фактор, так как более эффективный код позволяет затратить на передачу сообщения меньше энергии, а также времени, а при хранении – используется меньше площади поверхности носителя.
! Следует осознавать, что выгодность кода не идентична временной выгодности всей цепочки кодирование/передача /декодирование. Возможны ситуации, когда за использование эффективного кода при передаче придется расплачиваться тем, что операция кодирование/декодирование будут занимать больше времени и иных ресурсов.
Минимальным
возможным значением средней длины кода
будет
![]()
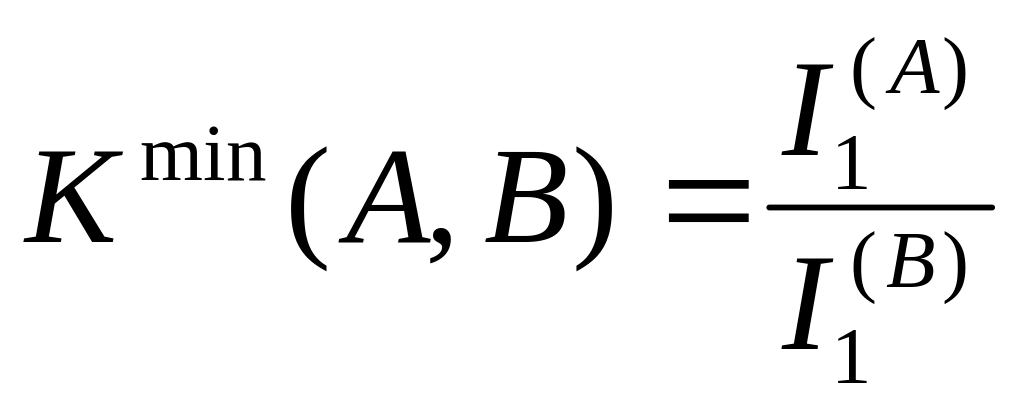 .
.
Данное выражение следует воспринимать как соотношение оценочного характера, устанавливающее нижний предел длины кода, однако из него неясно в какой степени в реальных схемах кодирования возможно приближение К(А,В) к Кmin (А,В).
Очевидно, что имеются два пути сокращения Кmin (А,В):
– уменьшение числителя (это возможно, если при кодировании учесть различие частот появления разных знаков, их двухбуквенные, трехбуквенные корреляции (I0 > I1 > I2 > … >In);
– увеличение знаменателя – такой способ кодирования, при котором появление знаков вторичного алфавита было бы равновероятным, то есть
IB = log 2 M .
В частной ситуации, рассмотренной Шенноном, при кодировании сообщения в первичном алфавите учитывается различная вероятность появления знаков, но их корреляции не отслеживаются – источники таких сообщений называются источниками без памяти.
Наиболее важной для практики оказывается ситуация, когда M=2, то есть для представления кодов в линии связи используются лишь 2 сигнала – технически это наиболее просто реализуется. Подобное кодирование называется двоичным, знаки двоичного алфавита (0,1).
При равных длительностях и вероятностях каждый элементарный сигнал несет в себе 1 бит информации I = log2 0,5 = 1 и тогда
Kmin (A, 2) = I1(A) .
Шеннон сформулировал в работе «Математическая теория связи» следующую теорему:
Основная теорема о кодировании при отсутствии помех
При отсутствии помех средняя длина двоичного кода может быть сколь угодно близкой к средней информации, приходящейся на знак первичного алфавита.
Но из самой теоремы никоим образом не следует, как такое кодирование осуществить практически. Важно, что теорема открывает принципиальную возможность оптимального кодирования.
Возможны следующие особенности вторичного алфавита, используемые при кодировании:
элементарные сигналы (0,1) могут иметь одинаковые длительности (0 = 1) или разные (0 1);
длина кода может быть одинаковой для всех знаков первичного алфавита (такой называется равномерным) или же коды разных знаков первичного алфавита могут иметь различную длину (неравномерный код);
коды могут строиться для отдельного знака первичного алфавита (алфавитное кодирование) или для их комбинаций (кодирование блоков, слов).
Комбинации перечисленных особенностей определяют основу конкретного способа кодирования, однако, даже при одинаковой основе возможны различные варианты построения кодов, отличающихся своей эффективностью.