

2.1.3Способ равных частот
Для выполнения данного этапа была взята часть данных, представляющая собой процент голосов за Единую Россию.
В Excel для реализации этого способа использовалась функция ЧАСТОТА
Результат представлен на листе Excel «способ равных частот», а также на рисунке 2.4

Рисунок 2.4 – Способ равных частот
2.1.4Группировка данных наблюдения над дискретной случайной величиной
Для выполнения данного этапа была взята о часть данных, представляющая собой процент голосов за «Яблоко». Все данные были округлены до двух знаков после запятой для того, чтобы смоделировать дискретную величину.
В Excel для реализации этого способа использовалась процедура Гистограмма.
Результат представлен на листе Excel «группировка данных над дсв», а также на рисунке 2.5

Рисунок 2.5 – Группировка данных наблюдения над дискретной случайной величиной
2.1.5Эмпирическая функция распределения
Для выполнения данного этапа была взята часть данных, представляющая собой процент голосов за Единую Россию. В данном случае число наблюдений за наблюдаемой величиной велико, поэтому были использованы таблицы частот из листов «сп. равн инт. с зад. границами», «способ равных частот» для построения эмпирической функции распределения по предварительно сгруппированным данных.
Результат представлен на листе Excel «Эмпирич. функция распр-я», а также на рисунке 2.6
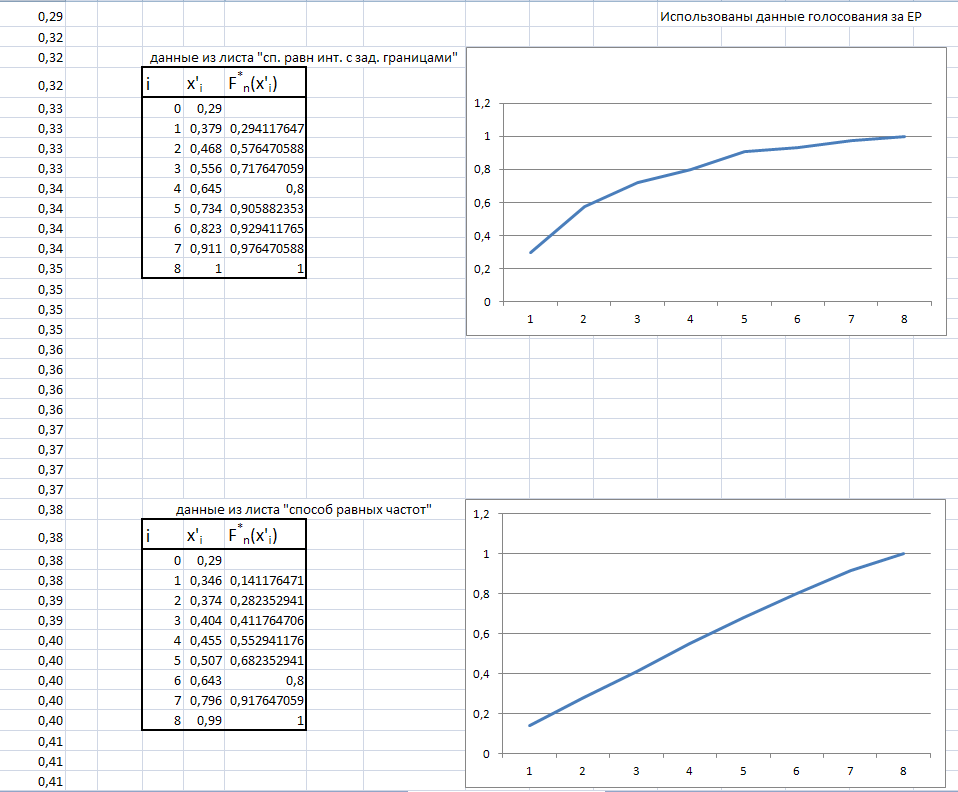
Рисунок 2.6 – Эмпирическая функция распределения
2.1.6Эмпирическая плотность вероятности
Для выполнения данного этапа была взята часть данных, представляющая собой процент голосов за Единую Россию. Были использованы таблицы частот из листов «сп. равн инт. с зад. границами», «способ равных частот».
Результат представлен на листе Excel «Эмпирич плотн вер-ти», а также на рисунке 2.7

Рисунок 2.7 – Эмпирическая плотность вероятности
2.1.7Эмпирический ряд распределения
Для выполнения данного этапа была взята часть данных, представляющая собой процент голосов за Единую Россию. Была использована таблица частот из листа «группировка данных над дсв».
Результат представлен на листе Excel «Эмпирич ряд распред-я», а также на рисунке 2.8

Рисунок 2.8 – Эмпирический ряд распределения
2.1.8Статистическая процедура «Описательная статистика»
Для выполнения данного этапа была взята часть данных, представляющая собой процент голосов за Единую Россию. Была использована процедура «Описательная статистика».
Стандартизованные значения эксцесса и асимметрии вычислены по формулам =D9/(КОРЕНЬ(24/85)) и =D10/(КОРЕНЬ(6/85)), где D9 и D10 – это вычисленные значения эксцесса и асимметрии с помощью стандартных функций Excel, а 85 – размер выборки.
Результат представлен на листе Excel «Стат проц. "описат. статистика"», а также на рисунке 2.9

Рисунок 2.9 – Статистическая процедура «Описательная статистика»
2.2Порядковые статистики и ранги
2.2.1Статистическая процедура “Ранг и персентиль”
Для выполнения данного этапа была взята часть данных, представляющая собой процент голосов за все партии в Ханты-Мансийском Автономном Округе и Челябинской области.
В Excel для реализации этого способа использовалась процедура Статистическая процедура “Ранг и персентиль”. Результат представлен на листе Excel «ранг», а также на рисунке 2.10

Рисунок 2.10 – Статистическая процедура “Ранг и персентиль”
2.2.2Функция ранг
Для выполнения данного этапа была взята часть данных, представляющая собой процент голосов за все партии в Ханты-Мансийском Автономном Округе и Челябинской области.
В Excel для реализации этого способа использовалась функция РАНГ. Результат представлен на листе Excel «ранг», а также на рисунке 2.11
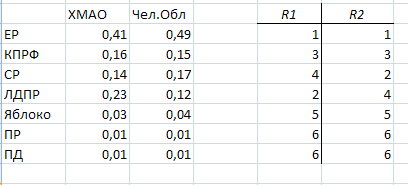
Рисунок 2.11 – Функция РАНГ